






本系列博客主要是在学习 C++ Primer 时的一些总结和笔记。
【C++ Primer 学习笔记】: 容器和算法之【泛型算法】
本文地址:http://blog.csdn.net/shanglianlm/article/details/50039465
1 概述
大多数情况下,每个算法都需要使用(至少)两个迭代器指出该算法操纵的元素范围。第一个迭代器指向第一个元素,而第二个迭代器则指向最后一个元素的下一位置。第二个迭代器所指向的元素[有时被称为超出末端迭代器]本身不是要操作的元素,而被用作终止遍历的哨兵(sentinel)。
标准库提供了超过 100 种算法。与容器一样,算法有着一致的结构。
算法永不执行容器提供的操作
泛型算法本身从不执行容器操作,只是单独依赖迭代器和迭代器操作实现。算法基于迭代器及其操作实现,而并非基于容器操作。
2 初窥
头文件
#include <algorithm>泛化的算术算法
#include <numeric>2-1 只读算法
2-1-1 find
// value we'll look for
int search_value = 42;
// call find to see if that value is present
vector<int>::const_iterator result = find(vec.begin(), vec.end(), search_value);2-1-2 accumulate
// sum the elements in vec starting the summation with thevalue 42
int sum = accumulate(vec.begin(), vec.end(), 42);用于指定累加起始值的第三个实参是必要的,因为 accumulate 对将要累加的元素类型一无所知,因此,除此之外,没有别的办法创建合适的起始值或者关联的类型。
find_first_of
用 find_first_of 统计有多少个名字同时出现在这两个列表中
// program for illustration purposes only:
// there are much faster ways to solve this problem
size_t cnt = 0;
list<string>::iterator it = roster1.begin();
// look in roster1 for any name also in roster2
while ((it = find_first_of(it, roster1.end(), roster2.begin(), roster2.end())) != roster1.end()) {
++cnt;
// we got a match, increment it to look in the rest of roster1
++it;
}
cout << "Found " << cnt
<< " names on both rosters" << endl; 2-2 写容器元素的算法
2-2-1 fill
fill(vec.begin(), vec.end(), 0); // reset each element to 0
// set subsequence of the range to 10
fill(vec.begin(), vec.begin() + vec.size()/2, 10);2-2-2 fill_n
fill_n 函数带有的参数包括:一个迭代器、一个计数器以及一个值。
vector<int> vec; // empty vector
// disaster: attempts to write to 10 (nonexistent) elements in vec
fill_n(vec.begin(), 10, 0); fill_n 函数假定对指定数量的元素做写操作是安全的。初学者常犯的错误的是:在没有元素
的空容器上调用 fill_n 函数(或者类似的写元素算法)。对指定数目的元素做写入运算,或者写到目标迭代器的算法,都不检查目标的大小是否足以存储要写入的元素。
2-2-3 back_inserter
vector<int> vec; // empty vector
// ok: back_inserter creates an insert iterator that adds elements
to vec
fill_n (back_inserter(vec), 10, 0); // appends 10 elementsto vec 2-2-3 copy
vector<int> ivec; // empty vector
// copy elements from ilst into ivec
copy (ilst.begin(), ilst.end(), back_inserter(ivec));2-2-4 replace
// replace any element with value of 0 by 42
replace(ilst.begin(), ilst.end(), 0, 42);2-3 对容器元素重新排序的算法
2-3-1 unique
// sort words alphabetically so we can find the duplicates sort(words.begin(), words.end());
/* eliminate duplicate words:
* unique reorders words so that each word appears once inthe
* front portion of words and returns an iterator one past the
unique range;
* erase uses a vector operation to remove the nonunique elements
*/
vector<string>::iterator end_unique = unique(words.begin(), words.end());
words.erase(end_unique, words.end()); - unique 算法带有两个指定元素范围的迭代器参数。该算法删除相邻的重复元素,然后重新排列输入范围内的元素,并且返回一个迭代器,表示无重复的值范围的结束。
- unique 实际上并没有删除任何元素,而是将无重复的元素复制到序列的前端,从而覆盖相邻的重复元素。unique 返回的迭代器指向超出无重复的元素范围末端的下一位置。
算法不直接修改容器的大小。如果需要添加或删除元素,则必须使用容器操作
2-3-2 stable_sort
stable_sort 保留相等元素的原始相对位置。
// sort words by size, but maintain alphabetic order for words of the same size
stable_sort(words.begin(), words.end(), isShorter);
// comparison function to be used to sort by word length
bool isShorter(const string &s1, const string &s2)
{
return s1.size() < s2.size();
} 2-3-3 count_if
vector<string>::size_type wc = count_if(words.begin(), words.end(), GT6);
// determine whether a length of a given word is 6 or more
bool GT6(const string &s)
{
return s.size() >= 6;
} 2-3-4 实例
假设我们要分析一组儿童故事中所使用的单词。例如,可能想知道它们使用了多少个由六个或以上字母组成的单词。每个单词只统计一次,不考虑它出现的次数,也不考虑它是否在多个故事中出现。要求以长度的大小输出这些单词,对于同样长的单词,则以字典顺序输出。
// comparison function to be used to sort by word length
bool isShorter(const string &s1, const string &s2)
{
return s1.size() < s2.size();
}
// determine whether a length of a given word is 6 or more
bool GT6(const string &s)
{
return s.size() >= 6;
}
int main()
{
vector<string> words;
// copy contents of each book into a single vector
string next_word;
while (cin >> next_word) {
// insert next book's contents at end of words
words.push_back(next_word);
}
// sort words alphabetically so we can find the duplicates sort (words.begin(), words.end());
/* eliminate duplicate words:
* unique reorders words so that each word appears once in the
* front portion of words and returns an iterator one past the unique range;
* erase uses a vector operation to remove the nonunique elements
*/
vector<string>::iterator end_unique = unique(words.begin(), words.end());
words.erase(end_unique, words.end());
// sort words by size, but maintain alphabetic order for words of the same size
stable_sort(words.begin(), words.end(), isShorter);
vector<string>::size_type wc = count_if (words.begin(), words.end(),GT6);
cout << wc << " " << make_plural(wc, "word", "s")
<< " 6 characters or longer" << endl;
return 0;
} 3 再谈迭代器
头文件
#include <iterator>- 插入迭代器:这类迭代器与容器绑定在一起,实现在容器中插入元素的功能。
- iostream 迭代器:这类迭代器可与输入或输出流绑定在一起,用于迭代遍历所关联的 IO 流。
- 反向迭代器:这类迭代器实现向后遍历,而不是向前遍历。所有容器类型都定义了自己的 reverse_iterator 类型,由 rbegin 和 rend 成员函数返回。
- const_iterator 迭代器
3-1 插入迭代器
- back_inserter,创建使用 push_back 实现插入的迭代器。
- front_inserter,使用 push_front 实现插入。
- inserter,使用 insert 实现插入操作。除了所关联的容器外,inserter 还带有第二实参:指向插入起始位置的迭代器。
front_inserter需要使用 push_front
只有当容器提供 push_front 操作时,才能使用 front_inserter。在 vector 或其他没有 push_front 运算的容器上使用 front_inserter,将产生错误。
inserter将产生在指定位置实现插入的迭代
inserter 适配器提供更普通的插入形式。这种适配器带有两个实参:所关联的容器和指示起始插入位置的迭代器。
// position an iterator into ilst
list<int>::iterator it = find (ilst.begin(), ilst.end(), 42);
// insert replaced copies of ivec at that point in ilst
replace_copy (ivec.begin(), ivec.end(), inserter (ilst, it), 100, 0);ilst 的新元素在 it 所标明的元素前面插入。
在创建 inserter 时,应指明新元素在何处插入。inserter 函数总是在它的迭代器实参所标明的位置前面插入新元素。
list<int> ilst, ilst2, ilst3; // empty lists
// after this loop ilst contains: 3 2 1 0
for (list<int>::size_type i = 0; i != 4; ++i)
ilst.push_front(i);
// after copy ilst2 contains: 0 1 2 3
copy (ilst.begin(), ilst.end(), front_inserter(ilst2));
// after copy, ilst3 contains: 3 2 1 0
copy (ilst.begin(), ilst.end(), inserter (ilst3, ilst3.begin()));front_inserter 的使用将导致元素以相反的次序出现在目标对象中。
3-2 iostream 迭代器
3-2-1 定义

两种构建 istream_iterator 的方式:
istream_iterator<int> cin_it(cin); // reads ints1 from cin
istream_iterator<int> end_of_stream; // end iterator value或者
istream_iterator<int> cin_it; 该迭代器指向超出末端位置。

流迭代器只定义了最基本的迭代器操作:自增、解引用和赋值。此外,可比较两个 istream 迭代器是否相等(或不等)。而 ostream 迭代器则不提供比较运算
3-2-2 istream_iterator对象上的操作
istream_iterator<int> in_iter(cin); // read ints from cin
istream_iterator<int> eof; // istream "end" iterator
// read until end of file, storing what was read in vec
while (in_iter != eof)
// increment advances the stream to the next value
// dereference reads next value from the istream
vec.push_back(*in_iter++);也可以这样写
istream_iterator<int> in_iter(cin); // read ints from cin
istream_iterator<int> eof; // istream "end" iterator
vector<int> vec(in_iter, eof); // construct vec from an iterator range 这个构造函数的效果是读 cin,直到到达文件结束或输入的不是 int 型
数值为止。读取的元素将用于构造 vec 对象。
3-2-3 ostream_iterator 对象上的操作
// write one string per line to the standard output
ostream_iterator<string> out_iter(cout, "\n");
// read strings from standard input and the end iterator
istream_iterator<string> in_iter(cin), eof;
// read until eof and write what was read to the standard output
while (in_iter != eof)
// write value of in_iter to standard output
// and then increment the iterator to get the next value from
cin
*out_iter++ = *in_iter++;3-2-4 与算法一起使用流迭代器
例子 从标准输入读取一些数,再将读取的不重复的数写到标准输出:
istream_iterator<int> cin_it(cin); // reads ints from cin
istream_iterator<int> end_of_stream; // end iterator value
// initialize vec from the standard input:
vector<int> vec(cin_it, end_of_stream);
sort(vec.begin(), vec.end());
// writes ints to cout using " " as the delimiter
ostream_iterator<int> output(cout, " ");
// write only the unique elements in vec to the standard output
unique_copy(vec.begin(), vec.end(), output);3-3 反向迭代器
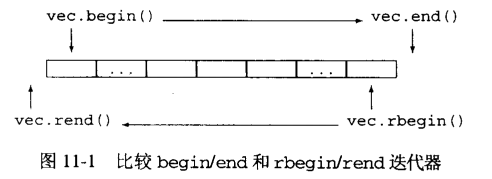
3-3-1 反向迭代器需要使用自减操作符
从一个既支持 – 也支持 ++ 的迭代器就可以定义反向迭代器,这不用感到吃惊。毕竟,反向迭代器的目的是移动迭代器反向遍历序列。标准容器上的迭代器既支持自增运算,也支持自减运算。但是,流迭代器却不然,由于不能反向遍历流,因此流迭代器不能创建反向迭代器。
3-3-2 所有反向迭代器类型都提供的成员函数 base
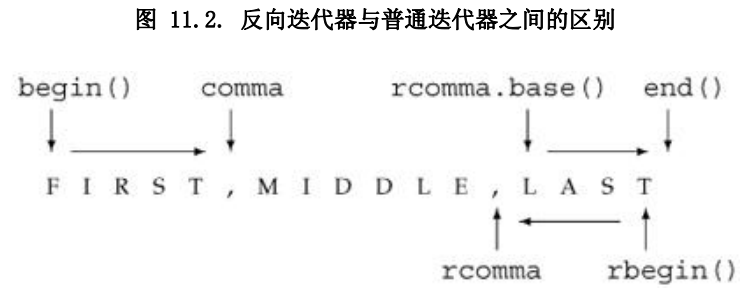
假设有一个名为 line 的 string 对象,存储以逗号分隔的单词列表。我们
希望输出 line 中的第一个单词。使用 find 可很简单地实现这个任务:
// find first element in a comma-separated list
string::iterator comma = find(line.begin(), line.end(), ',');
cout << string(line.begin(), comma) << endl; 如果要输出列表中最后一个单词,可使用反向迭代器:
// find last element in a comma-separated list
string::reverse_iterator rcomma = find(line.rbegin(), line.rend(), ',');base 对 rcomma 转换
// ok: get a forward iterator and read to end of line
cout << string(rcomma.base(), line.end()) << endl;反向迭代器用于表示范围,而所表示的范围是不对称的,这个事实可推导出一个重要的结论:使用普通的迭代器对反向迭代器进行初始化或赋值时,所得到的迭代器并不是指向原迭代器所指向的元素。
3-4 const 迭代器
// call find to look through elements in a list
list<int>::const_iterator result = find(lst.begin(), lst.end(), search_value); 将 result 定义为 const_iterator 类型。这样做是因为我们不希望使用这个迭代器来修改容器中的元素。
// program for illustration purposes only:
// there are much faster ways to solve this problem
size_t cnt = 0;
list<string>::iterator it = roster1.begin();
// look in roster1 for any name also in roster2
while ((it = find_first_of(it, roster1.end(), roster2.begin(), roster2.end())) != roster1.end()) {
++cnt;
// we got a match, increment it to look in the rest of roster1
++it;
}
cout << "Found " << cnt << " names on both rosters" << endl; 该函数调用的输入范围由 it 和调用 roster1.end() 返回的迭代器指定。roster1 不是 const 对象,因而 end 返回的只是一个普通的迭代器。
3-5 五种迭代器

3-5-1 输入迭代器
可用于读取容器中的元素,但是不保证能支持容器的写入操作。输入迭代器必须至少提供下列支持。
- 相等和不等操作符(==,!=),比较两个迭代器。
- 前置和后置的自增运算(++),使迭代器向前递进指向下一个元素。
- 用于读取元素的解引用操作符(*),此操作符只能出现在赋值运
算的右操作数上。 - 箭头操作符(->),这是 (*it).member 的同义语,也就是说,对迭代器进行解引用来获取其所关联的对象的成员。
输入迭代器只能顺序使用;一旦输入迭代器自增了,就无法再用它检查之前的元素。
3-5-2 输出迭代器
可视为与输入迭代器功能互补的迭代器;输出迭代器可用于向容器写入元素,但是不保证能支持读取容器内容。输出迭代器要求:
- 前置和后置的自增运算(++),使迭代器向前递进指向下一个元素。
- 解引用操作符(*),引操作符只能出现在赋值运算的左操作数上。给解引用的输出迭代器赋值,将对该迭代器所指向的元素做写入操作。
输出迭代器可以要求每个迭代器的值必须正好写入一次。使用输出迭代器时,对于指定的迭代器值应该使用一次 * 运算,而且只能用一次。输出迭代器一般用作算法的第三个实参,标记起始写入的位置。
3-5-3 前向迭代器
用于读写指定的容器。这类迭代器只会以一个方向遍历序列。前向迭代器支持输入迭代器和输出迭代器提供的所有操作,除此之外,还支持对同一个元素的多次读写。可复制前向迭代器来记录序列中的一个位置,以便将来返回此处。需要前向迭代器的泛型算法包括 replace。
3-5-4 双向迭代器
从两个方向读写容器。除了提供前向迭代器的全部操作之外,双向迭代器还提供前置和后置的自减运算(–)。需要使用双向迭代器的泛型算法包括 reverse。所有标准库容器提供的迭代器都至少达到双向迭代器的要求。
3-5-5 随机访问迭代器
提供在常量时间内访问容器任意位置的功能。这种迭代器除了支持双向迭代器的所有功能之外,还支持下面的操作:
- 关系操作符 <、<=、> 和 >=,比较两个迭代器的相对位置。
- 迭代器与整型数值 n 之间的加法和减法操作符 +、+=、- 和 -=,结果是迭代器在容器中向前(或退回)n 个元素。
- 两个迭代器之间的减法操作符(–),得到两个迭代器间的距离。
- 下标操作符 iter[n],这是 *(iter + n) 的同义词。
需要随机访问迭代器的泛型算法包括 sort 算法。vector、deque 和 string 迭代器是随机访问迭代器,用作访问内置数组元素的指针也是随机访问迭代器。
map、set 和 list 类型提供双向迭代器,而 string、vector 和 deque 容器上定义的迭代器都是随机访问迭代器都是随机访问迭代器,用作访问内置数组元素的指针也是随机访问迭代器。istream_iterator 是输入迭代器,而 ostream_iterator 则是输出迭代器。
尽管 map 和 set 类型提供双向迭代器,但关联容器只能使用算法的一个子集。问题在于:关联容器的键是 const 对象。因此,关联容器不能使用任何写序列元素的算法。只能使用与关联容器绑在一起的迭代器来提供用于读操作的实参。
在处理算法时,最好将关联容器上的迭代器视为支持自减运算的输入迭代器,而不是完整的双向迭代器。
4 泛型算法的结构
4-1 算法的形参模型
大多数算法采用下面四种形式之一:
alg (beg, end, other parms);
alg (beg, end, dest, other parms);
alg (beg, end, beg2, other parms);
alg (beg, end, beg2, end2, other parms);其中,alg 是算法的名字,beg 和 end 指定算法操作的元素范围。我们通常将该范围称为算法的“输入范围”。其他形参:dest、beg2 和 end2,它们都是迭代器。
4-1-1 带有单个目标迭代器的算法
dest 形参是一个迭代器,用于指定存储输出数据的目标对象。算法假定无论需要写入多少个元素都是安全的。
调用这些算法时,必须确保输出容器有足够大的容量存储输出数据,这正是通常要使用插入迭代器或者 ostream_iterator 来调用这些算法的原因。如果使用容器迭代器调用这些算法,算法将假定容器里有足够多个需要的元素。
4-1-2 带第二个输入序列的算法
有一些算法带有一个 beg2 迭代器形参,或者同时带有 beg2 和 end2 迭代器形参,来指定它的第二个输入范围。这类算法通常将联合两个输入范围的元素来完成计算功能。
与写入 dest 的算法一样,只带有 beg2 的算法也假定以 beg2 开始的序列与 beg 和 end 标记的序列一样大。
-4-2 算法的命名规范
标准库使用一组相同的命名和重载规范。它们包括两种重要模式:第一种模式包括测试输入范围内元素的算法,第二种模式则应用于对输入范围内元素重新排序的算法。
4-2-1 区别带有一个值或一个谓词函数参数的算法版本
很多算法通过检查其输入范围内的元素实现其功能。这些算法通常要用到标准关系操作符:== 或 <。其中的大部分算法会提供第二个版本的函数,允许程序员提供比较或测试函数取代操作符的使用。
sort (beg, end); // use < operator to sort the elements
sort (beg, end, comp); // use function named comp to sort the elements find(beg, end, val); // find first instance of val in the input range
find_if(beg, end, pred); // find first instance for which pred is true 4-2-2 区别是否实现复制的算法版本
reverse(beg, end);
reverse_copy(beg, end, dest); reverse 函数的功能就如它的名字所意味的:将输入序列中的元素反射重新排列。其中,第一个函数版本将自己的输入序列中的元素反向重排。而第二个版本,reverse_copy,则复制输入序列的元素,并将它们逆序存储到 dest 开始的序列中。
5 容器特有的算法
list 容器上的迭代器是双向的,而不是随机访问类型。由于 list 容器不支持随机访问,因此,在此容器上不能使用需要随机访问迭代器的算法。
如果可以结合利用 list 容器的内部结构,则可能编写出更快的算法。与其他顺序容器所支持的操作相比,标准库为 list 容器定义了更精细的操作集合,使它不必只依赖于泛型操作。

l.remove(val); // removes all instances of val from 1
l.remove_if(pred); // removes all instances for which predis true
from 1
l.reverse(); // reverses the order of elements in 1
l.sort(); // use element type < operator to compare elements
l.sort(comp); // use comp to compare elements
l.unique(); // uses element == to remove adjacent duplicates
l.unique(comp); // uses comp to remove duplicate adjacent copies list 容器特有的算法与其泛型算法版本之间有两个至关重要的差别。
- 其中一个差别是 remove 和 unique 的 list 版本修改了其关联的基础容器:真正删除了指定的元素。
- 另一个差别是 list 容器提供的 merge 和 splice 运算会破坏它们的实参。
与对应的泛型算法不同,list 容器特有的操作能添加和删除元素。
对于 list 对象,应该优先使用 list 容器特有的成员版本,而不是泛型算法














 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









