







TensorFlow可以用单个GPU,加速深度学习模型的训练过程,但要利用更多的GPU或者机器,需要了解如何并行化地训练深度学习模型。
常用的并行化深度学习模型训练方式有两种:同步模式和异步模式。
下面将介绍这两种模式的工作方式及其优劣。
如下图,深度学习模型的训练是一个迭代的过程。
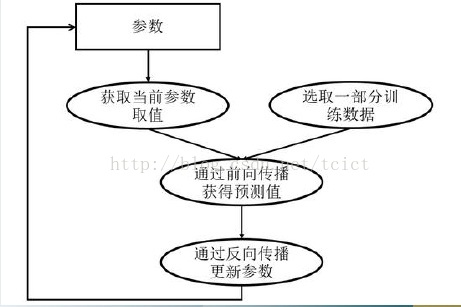
在每一轮迭代中,前向传播算法会根据当前参数的取值,计算出在一小部分训练数据上的预测值,然后反向传播算法,再根据损失函数计算参数的梯度并更新参数。
异步模式的训练流程图
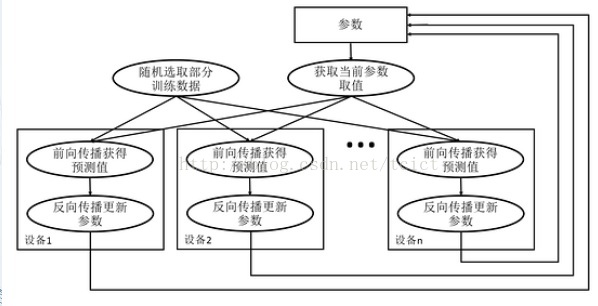
在并行化地训练深度学习模型时,不同设备(GPU或CPU),可以在不同训练数据上,运行这个迭代的过程,而不同并行模式的区别在于,不同的参数更新方式。
异步模式的训练流程
从异步模式的训练流程图中可以看到,在每一轮迭代时,不同设备会读取参数最新的取值。
–但因为不同设备,读取参数取值的时间不一样,所以得到的值也有可能不一样。
根据当前参数的取值,和随机获取的一小部分训练数据,不同设备各自运行反向传播的过程,并独立地更新参数。
–可以认为异步模式,就是单机模式复制了多份,每一份使用不同的训练数据进行训练。
同步模式深度学习训练
在同步模式下,所有的设备同时读取参数的取值,并且当反向传播算法完成之后同步更新参数的取值。
单个设备不会单独对参数进行更新,而会等待所有设备都完成反向传播之后再统一更新参数。
分析
图中在每一轮迭代时,不同设备首先统一读取当前参数的取值,并随机获取一小部分数据。
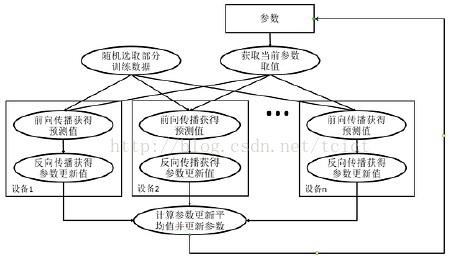
然后在不同设备上运行反向传播过程得到在各自训练数据上参数的梯度。
当所有设备完成反向传播的计算之后,需要计算出不同设备上参数梯度的平均值,最后再根据平均值对参数进行更新。
3多GPU并行
下面将给出具体的TensorFlow代码,在一台机器的多个GPU上并行训练深度学习模型。
–因为一般来说一台机器上的多个GPU性能相似,所以在这种设置下,会更多地采用同步模式,训练深度学习模型。
下面将给出具体的代码,在多GPU上训练深度学习模型解决MNIST问题。
–样例代码将沿用mnist_inference.py程序,来完成神经网络的前向传播过程。
–新的神经网络训练程序是mnist_multi_ gpu_train.py
运行样例
运行MNIST样例程序时GPU的使用情况
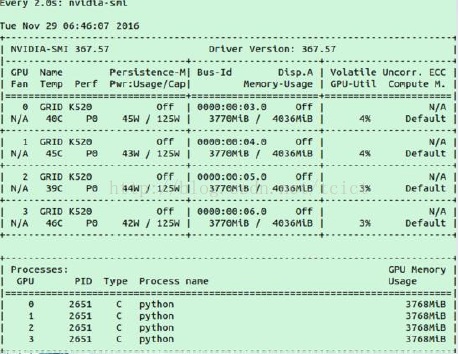
–因为定义的神经网络规模比较小,所以在图中显示的GPU使用率不高。
常用的并行化深度学习模型训练方式有两种:同步模式和异步模式。
下面将介绍这两种模式的工作方式及其优劣。
如下图,深度学习模型的训练是一个迭代的过程。
在每一轮迭代中,前向传播算法会根据当前参数的取值,计算出在一小部分训练数据上的预测值,然后反向传播算法,再根据损失函数计算参数的梯度并更新参数。
异步模式的训练流程图
在并行化地训练深度学习模型时,不同设备(GPU或CPU),可以在不同训练数据上,运行这个迭代的过程,而不同并行模式的区别在于,不同的参数更新方式。
异步模式的训练流程
从异步模式的训练流程图中可以看到,在每一轮迭代时,不同设备会读取参数最新的取值。
–但因为不同设备,读取参数取值的时间不一样,所以得到的值也有可能不一样。
根据当前参数的取值,和随机获取的一小部分训练数据,不同设备各自运行反向传播的过程,并独立地更新参数。
–可以认为异步模式,就是单机模式复制了多份,每一份使用不同的训练数据进行训练。
同步模式深度学习训练
在同步模式下,所有的设备同时读取参数的取值,并且当反向传播算法完成之后同步更新参数的取值。
单个设备不会单独对参数进行更新,而会等待所有设备都完成反向传播之后再统一更新参数。
分析
图中在每一轮迭代时,不同设备首先统一读取当前参数的取值,并随机获取一小部分数据。
然后在不同设备上运行反向传播过程得到在各自训练数据上参数的梯度。
当所有设备完成反向传播的计算之后,需要计算出不同设备上参数梯度的平均值,最后再根据平均值对参数进行更新。
3多GPU并行
下面将给出具体的TensorFlow代码,在一台机器的多个GPU上并行训练深度学习模型。
–因为一般来说一台机器上的多个GPU性能相似,所以在这种设置下,会更多地采用同步模式,训练深度学习模型。
下面将给出具体的代码,在多GPU上训练深度学习模型解决MNIST问题。
–样例代码将沿用mnist_inference.py程序,来完成神经网络的前向传播过程。
–新的神经网络训练程序是mnist_multi_ gpu_train.py
运行样例
运行MNIST样例程序时GPU的使用情况
–因为定义的神经网络规模比较小,所以在图中显示的GPU使用率不高。
–如果训练大型的神经网络模型,TensorFlow将会占满所有用到的GPU。














 765
765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









