










在C语言中利用PCRE实现正则表达式
http://dev.jizhiinfo.net/?post=49(转载地址)
1. PCRE简介
2. 正则表达式定义
3. PCRE正则表达式的定义
4. PCRE的函数简介
5. 使用PCRE在C语言中实现正则表达式的解析
6. PCRE函数在C语言中的使用小例子
1. PCRE简介
PCRE(Perl Compatible Regular Expressions即:perl语言兼容正则表达式)是一个用C语言编写的正则表达式函数库,由菲利普.海泽(Philip Hazel)编写。PCRE是一个轻量级的函数库,比Boost之中的正则表达式库小得多。PCRE十分易用,同时功能也很强大,性能超过了POSIX正则表达式库和一些经典的正则表达式库[1]。
和Boost正则表达式库的比较显示[2],双方的性能相差无几,PCRE在匹配简单字符串时更快,Boost则在匹配较长字符串时胜出---但两者差距很小,考虑到PCRE的大小和易用性,我们可以认为PCRE更值得考虑。
PCRE被广泛使用在许多开源软件之中,最著名的莫过于Apache HTTP服务器和PHP脚本语言、R脚本语言,此外,正如从其名字所能看到的,PCRE也是perl语言的缺省正则库。
PCRE是用C语言实现的,其C++实现版本是PCRE++。
2. 正则表达式定义
一个正则表达式就是由普通字符(例如字符 a 到 z)以及特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
例如下面一些正则表达式:
^(-?\d+)(\.\d+)?$ 匹配浮点数
^[A-Za-z]+$ 匹配由26个英文字母组成的字符串
^[A-Z]+$ 匹配由26个英文字母的大写组成的字符串
^[a-z]+$ 匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ 匹配由数字和26个英文字母组成的字符串
^\w+$ 匹配由数字、26个英文字母或者下划线组成的字符串
^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$ 匹配email地址
当然,可能你会问上面这些表达式为什么是这样写。这里就暂时不做多讲,因为本文主要讲的是PCRE库的应用,所以想了解更多的话,可以看我下面的[附录1],里面有全部正则表式用到的元字符说明。或参考网址[3]正则表达式语言元素msdn文档。
3. PCRE正则表达式的定义
用于描述字符排列和匹配模式的一种语法规则。它主要用于字符串的模式分割、匹配、查找及替换操作。
正则中重要的几个概念有:元字符、转义、模式单元(重复)、反义、引用和断言。
常用的元字符(Meta-character)
元字符 说明
\A 匹配字符串串首的原子
\Z 匹配字符串串尾的原子
\b 匹配单词的边界/\bis/匹配头为is的字符串/is\b/ 匹配尾为is的字符串 /\bis\b/ 定界
\B 匹配除单词边界之外的任意字符 /\Bis/ 匹配单词“This”中的“is”
\d 匹配一个数字;等价于[0-9]
\D 匹配除数字以外任何一个字符;等价于[^0-9]
\w 匹配一个英文字母、数字或下划线;等价于[0-9a-zA-Z_]
\W 匹配除英文字母、数字和下划线以外任何一个字符;等价于[^0-9a-zA-Z_]
\s 匹配一个空白字符;等价于[\f\t\v]
\S 匹配除空白字符以外任何一个字符;等价于[^\f\t\v]
\f 匹配一个换页符等价于 \x0c 或 \cL
匹配一个换行符;等价于 \x0a 或 \cJ
匹配一个回车符等价于\x0d 或 \cM
\t 匹配一个制表符;等价于 \x09\或\cl
\v 匹配一个垂直制表符;等价于\x0b或\ck
\oNN 匹配一个八进制数字
\xNN 匹配一个十六进制数字
\cC 匹配一个控制字符
模式修正符(Pattern Modifiers)
模式修正符在忽略大小写、匹配多行中使用特别多,掌握了这一个修正符,往往能解决我们遇到的很多问题。
i -可同时匹配大小写字母
M -将字符串视为多行
S -将字符串视为单行,换行符做普通字符看待,使“.”匹配任何字符
X -模式中的空白忽略不计
U -匹配到最近的字符串
e -将替换的字符串作为表达使用
格式:/apple/i匹配“apple”或“Apple”等,忽略大小写。
当然这里还有很多种情况,在这里就不一一描述出来了。
4. PCRE的函数简介
PCRE是一个NFA正则引擎,不然不能提供完全与Perl一致的正则语法功能。但它同时也实现了DFA,只是满足数学意义上的正则。
PCRE提供了19个接口函数。
这里只介绍了几个主要和常用的接口函数,另外的可通过PCRE源码文档进行了解。注意,使用PCRE主要是使用下面介绍的前四个函数,对这四个函数有了了解,使用PCRE库的时候就会简单很多了。
下面所讲的函数,都在PCRE头文件上定义申明:#include <pcre.h>。
1.pcre_compile
函数原型:
pcre *pcre_compile(const char *pattern, int options, const char **errptr, int *erroffset, const unsigned char *tableptr)
功能:将一个正则表达式编译成一个内部表示,在匹配多个字符串时,可以加速匹配。其同pcre_compile2功能一样只是缺少一个参数errorcodeptr。
参数说明:
pattern 正则表达式
options 为0,或者其他参数选项
errptr 出错消息
erroffset 出错位置
tableptr 指向一个字符数组的指针,可以设置为空NULL。
2. pcre_compile2
函数原型:
pcre *pcre_compile2(const char *pattern, int options, int *errorcodeptr, const char **errptr, int *erroffset, const unsigned char *tableptr)
功能:将一个正则表达式编译成一个内部表示,在匹配多个字符串时,可以加速匹配。其同pcre_compile功能一样只是多一个参数errorcodeptr。
参数:
pattern 正则表达式
options 为0,或者其他参数选项
errorcodeptr 存放出错码
errptr 出错消息
erroffset 出错位置
tableptr 指向一个字符数组的指针,可以设置为空NULL。
3. pcre_exec
函数原型:
int pcre_exec(const pcre *code, const pcre_extra *extra, const char *subject, int length, int startoffset, int options, int *ovector, int ovecsize)
功能:使用编译好的模式进行匹配,采用与Perl相似的算法,返回匹配串的偏移位置。
参数:
code 编译好的模式
extra 指向一个pcre_extra结构体,可以为NULL
subject 需要匹配的字符串
length 匹配的字符串长度(Byte)
startoffset 匹配的开始位置
options 选项位
ovector 指向一个结果的整型数组
ovecsize 数组大小。
4. pcre_study
函数原型:
pcre_extra *pcre_study(const pcre *code, int options, const char **errptr)
功能:对编译的模式进行学习,提取可以加速匹配过程的信息。
参数:
code 已编译的模式
options 选项
errptr 出错消息
5. pcre_version
函数原型:
char *pcre_version(void)
功能:返回PCRE的版本信息。
参数:无。
6. pcre_config
函数原型:
int pcre_config(int what, void *where)
功能:查询当前PCRE版本中使用的选项信息。
参数:
what 选项名
where 存储结果的位置
7.pcre_maketables
函数原型:
const unsigned char *pcre_maketables(void)
功能:生成一个字符表,表中每一个元素的值不大于256,可以用它传给pcre_compile()替换掉内建的字符表。
参数:无
5. 使用PCRE在C语言中实现正则表达式的解析
上述讲了这么多PCRE相关函数的介绍,目的还是为了能够运用上,所以这里就先讲解下使用PCRE的过程。主要过程分三步走第一步编译正则表达式;第二匹配正则表达式;第三步释放正则表达式。
1.编译正则表达式
为了提高效率,在将一个字符串与正则表达式进行比较之前,首先要用pcre_compile() /pcre_compile2() 函数对它时行编译,转化成PCRE引擎能够识别的结构(struct real_pcre)。
这里还可以调用pcre_study()函数,对编译后的正则表达式结构(struct real_pcre)时行分析和学习,学习的结果是一个数据结构(struc pcre_extra),这个数据结构连同编译后的规则(struct real_pcre)可以一起送给pcre_exec单元进行匹配。
2.匹配正则表达式
一旦用函数pcre_compile() /pcre_compile2()成功地编译了正则表达式,接下来就可以调用pcre_exec()函数完成模式匹配。根据正则表达式到指定的字符串中进行查找和匹配,并输出匹配的结果。
3. 释放正则表达式
无论什么时候,当不再需要已经编译过的正则表达式时,都应该调用函数free()将其释放,以免产生内在泄漏。
6. PCRE函数在C语言中的使用小例子
在使用PCRE库时,首先肯定是需要安装pcre的,不过一般的系统都会有自带的PCRE库。不过如果想使用最新版本的话,也可以自已下载一个安装包。我这里下载的安装是pcre-8.13.tar.gz版本。安装过程很简单,把安装包上传需要安装的服务器上,安装时默认路径即可,我是在linux环境下安装的,执行命令如下:
1.[root@host70-151 pcre-8.13]# ./configure
2.[root@host70-151 pcre-8.13]# make && make install
此两步即可安装完成,安装成功后的头文件在:/usr/local/include, 库文件在:/usr/local/lib 。
下面是我的一个使用PCRE库函数的一个小例子,其功能是匹配手机号码的正则表达式是否成功,分成四类手机号码时行匹配,分别是移动、电信、联通和CDMA的手机号。里面用到了PCRE库函数中的pcre_compile()和pcre_exec():
因为我是在linux下编译C程序的,所以要用到makefile文件。注意:如果你在编译时出现提示:
/usr/zej/zej_test/kernel/pcre_test2.c:29: undefined reference to `pcre_compile'
/usr/zej/zej_test/kernel/pcre_test2.c:35: undefined reference to `pcre_exec'
没有定义pcre.h文件里面的函数时,是因为没有链接到库文件里,这时可以能过修改makefile,在l里面添加一个lpcre即可。然后在编译便可成功。
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- #include <pcre.h>
- #define OVECCOUNT 30 /* should be a multiple of 3 */
- #define EBUFLEN 128
- #define BUFLEN 1024
- int main()
- {
- pcre *reCM, *reUN, *reTC, *reCDMA;
- const char *error;
- int erroffset;
- int ovector[OVECCOUNT];
- int rcCM, rcUN, rcTC, rcCDMA, i;
- /*
- 常用号段前三位
- 中国移动CM:134.135.136.137.138.139.150.151.152.157.158.159.187.188 ,147(数据卡)
- 中国联通UN:130.131.132.155.156.185.186
- 中国电信TC:133.153.180.189
- CDMA :133,153
- */
- char src[22];
- char pattern_CM[] = "^1(3[4-9]|5[012789]|8[78])\\d{8}$"; //正则表达式
- char pattern_UN[] = "^1(3[0-2]|5[56]|8[56])\\d{8}$";
- char pattern_TC[] = "^18[09]\\d{8}$";
- char pattern_CDMA[] = "^1[35]3\\d{8}$";
- printf("Please input your telephone number \n");
- scanf("%s", src);
- printf("String : %s\n", src);
- printf("Pattern_CM: \"%s\"\n", pattern_CM);
- printf("Pattern_UN: \"%s\"\n", pattern_UN);
- printf("Pattern_TC: \"%s\"\n", pattern_TC);
- printf("Pattern_CDMA: \"%s\"\n", pattern_CDMA);
- reCM = pcre_compile(pattern_CM, 0, &error, &erroffset, NULL); //将正则表达式编译成pcre内部表示结构
- reUN = pcre_compile(pattern_UN, 0, &error, &erroffset, NULL);
- reTC = pcre_compile(pattern_TC, 0, &error, &erroffset, NULL);
- reCDMA = pcre_compile(pattern_CDMA, 0, &error, &erroffset, NULL);
- if (reCM==NULL && reUN==NULL && reTC==NULL && reCDMA==NULL) {
- printf("PCRE compilation telephone failed at offset %d: %s\n", erroffset, error);
- return 1;
- }
- rcCM = pcre_exec(reCM, NULL, src, strlen(src), 0, 0, ovector, OVECCOUNT); //匹配pcre编译好的模式,成功返回正数,失败返回负数
- rcUN = pcre_exec(reUN, NULL, src, strlen(src), 0, 0, ovector, OVECCOUNT);
- rcTC = pcre_exec(reTC, NULL, src, strlen(src), 0, 0, ovector, OVECCOUNT);
- rcCDMA = pcre_exec(reCDMA, NULL, src, strlen(src), 0, 0, ovector, OVECCOUNT);
- if (rcCM<0 && rcUN<0 && rcTC<0 && rcCDMA<0) { //若没匹配返回错误信息
- if (rcCM==PCRE_ERROR_NOMATCH && rcUN==PCRE_ERROR_NOMATCH &&
- rcTC==PCRE_ERROR_NOMATCH && rcTC==PCRE_ERROR_NOMATCH) {
- printf("Sorry, no match ...\n");
- }
- else {
- printf("Matching error %d\n", rcCM);
- printf("Matching error %d\n", rcUN);
- printf("Matching error %d\n", rcTC);
- printf("Matching error %d\n", rcCDMA);
- }
- free(reCM);
- free(reUN);
- free(reTC);
- free(reCDMA);
- return 1;
- }
- printf("\nOK, has matched ...\n\n"); //匹配成功把对应的正则表达式和号码打印出来
- if (rcCM > 0) {
- printf("Pattern_CM: \"%s\"\n", pattern_CM);
- printf("String : %s\n", src);
- }
- if (rcUN > 0) {
- printf("Pattern_UN: \"%s\"\n", pattern_UN);
- printf("String : %s\n", src);
- }
- if (rcTC > 0) {
- printf("Pattern_TC: \"%s\"\n", pattern_TC);
- printf("String : %s\n", src);
- }
- if (rcCDMA > 0) {
- printf("Pattern_CDMA: \"%s\"\n", pattern_CDMA);
- printf("String : %s\n", src);
- }
- free(reCM); //释放内存
- free(reUN);
- free(reTC);
- free(reCDMA);
- return 0;
- }
下面是编译通过后,运行程序后的结果:
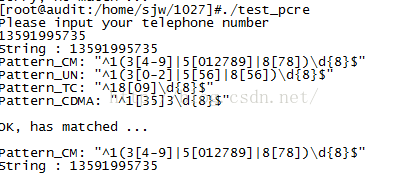
按照提示输入手机号:13591995735(移动手机号)
<!--[endif]-->
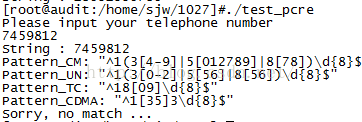
随便输入一个号码:7459812
<!--[endif]-->
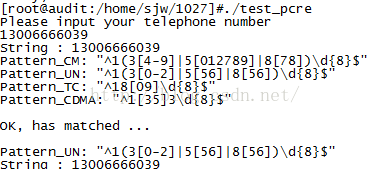
输入联通手机号码:13006666039
<!--[endif]-->
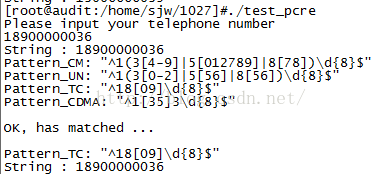
输入电信手机号码:18900000036
[1]:一些正则表达库的对比
http://www.regular-expressions.info/refflavors.html
[2]:Boost和PCRE正则库的性能对比
http://www.boost.org/doc/libs/1_40_0/libs/regex/doc/gcc-performance.html
[3]:正则表达式语言元素
http://msdn.microsoft.com/zh-cn/library/az24scfc.aspx
附录1:
元字符及其在正则表达式上下文中的行为的一个完整列表:
| 字符 | 描述 |
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 后向引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 '\\' 匹配 "\" 而 "\(" 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。 * 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。刘, "o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| (pattern) | 匹配pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在Visual Basic Scripting Edition 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 ' ′或′ '。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。 |
| (?=pattern) | 正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如, 'Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 负向预查,在任何不匹配Negative lookahead matches the search string at any point where a string not matching pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如'Windows (?!95|98|NT|2000)' 能匹配 "Windows 3.1" 中的 "Windows",但不能匹配 "Windows 2000" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
| x|y | 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。 x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如, '\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。. |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个后向引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为后向引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个后向引用。如果 \nm 之前至少有is preceded by at least nm 个获取得子表达式,则 nm 为后向引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的后向引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |














 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









