









前面我们说了无监督学习的第一个问题K-means算法,这里我们说第二个问题——降维。
降维
我们使用降维的第一个原因就是数据压缩。对数据进行压缩不仅能够使数据占用更少的计算机内存和硬盘空间。还能提高算法效率。
数据压缩 (Data Compression)
作者这里给了一个从二维降到一维的例子。
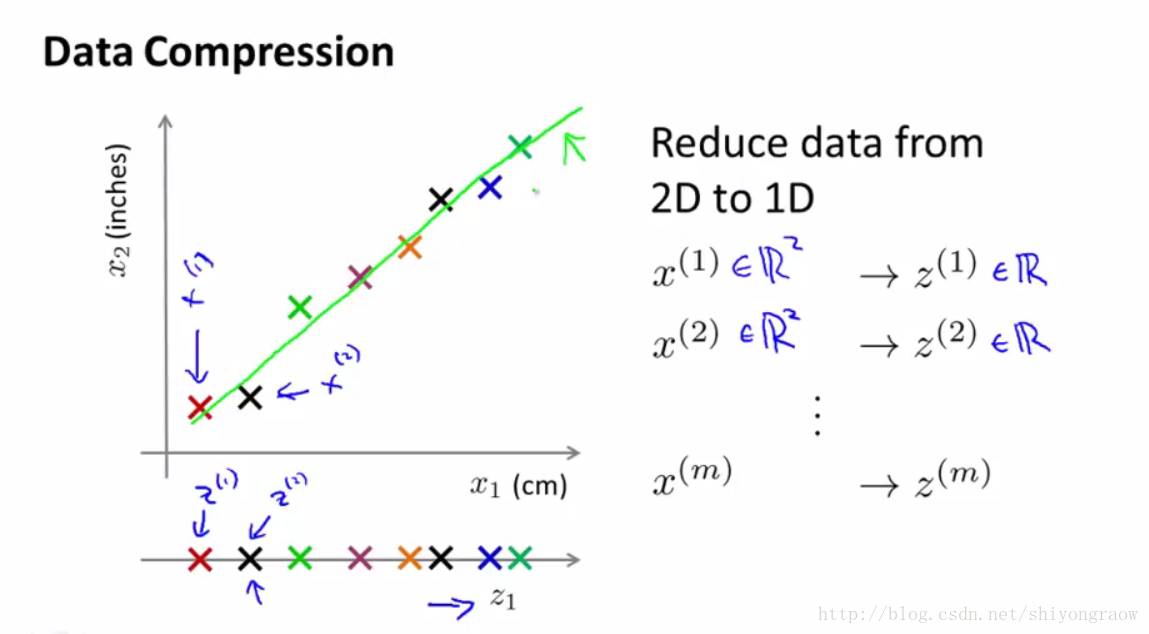
原先处于坐标系中的每个数据,需要俩个坐标来表示。当把数据降到一维后只需一个坐标来表示。
当数据维度越多时,这种效果越明显。这里给出从三维降到二维的一个过程。
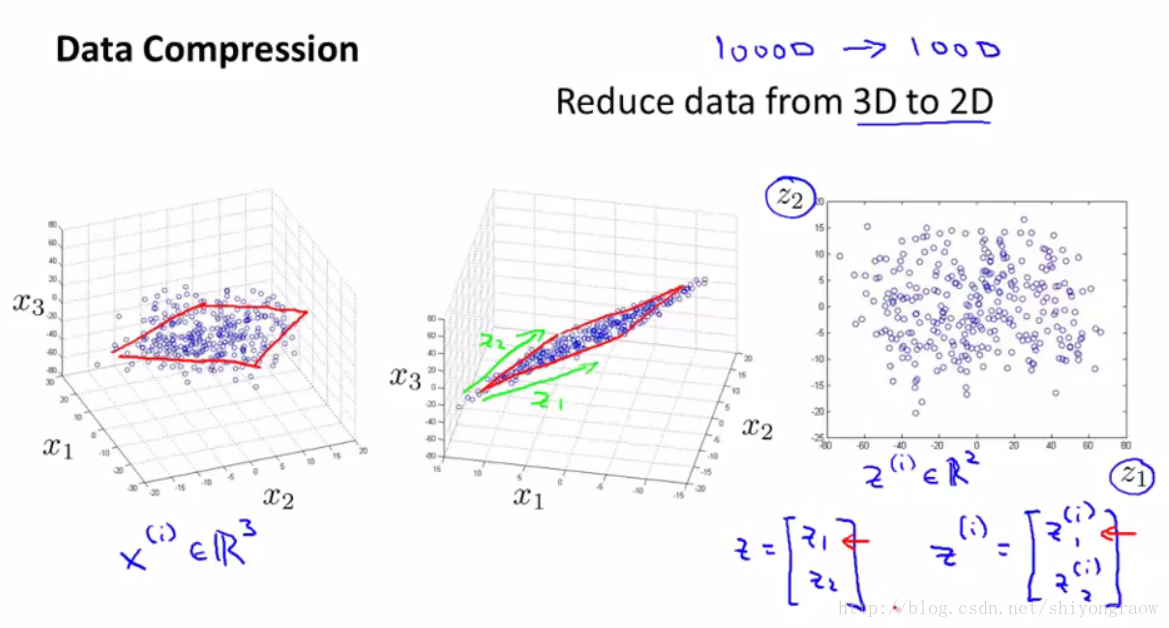
三维空间中所有数据映射到二维空间中,这样原来每个数据需要三维表示降到只需二维。
可视化数据 (Data Visualization)
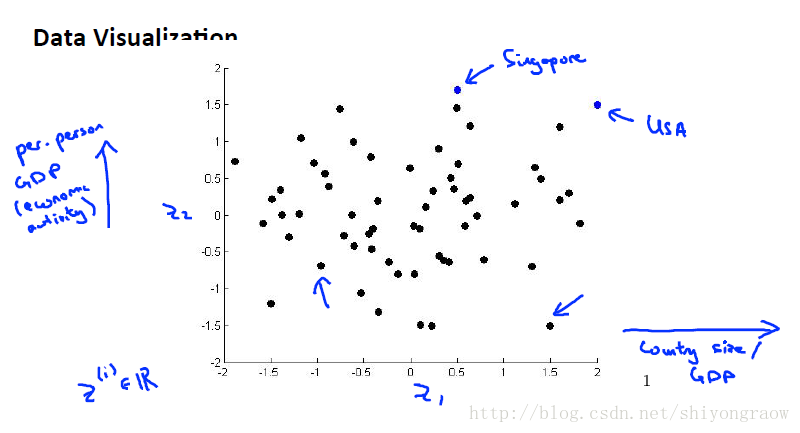
使用降维的第二个动机就是可视化数据。
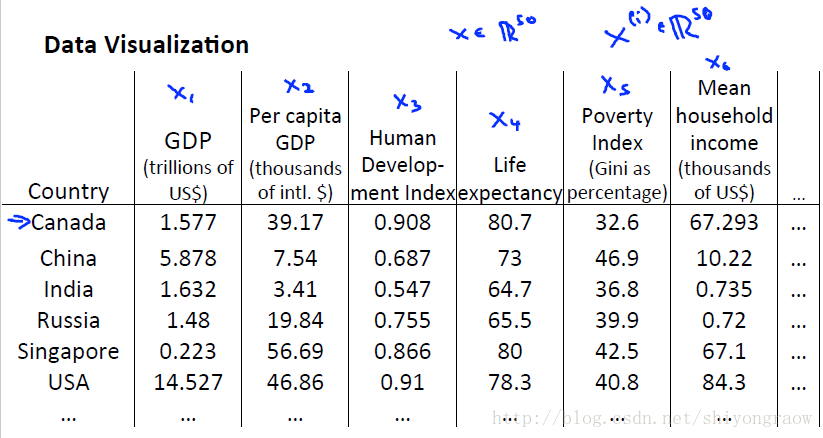
假设每个国家有50个特征表示。图中我们只列出其中六个,纵然如此,我们要画出一幅50维度的图是非常困难的,我们需要对数据进行降维,然后可视化。
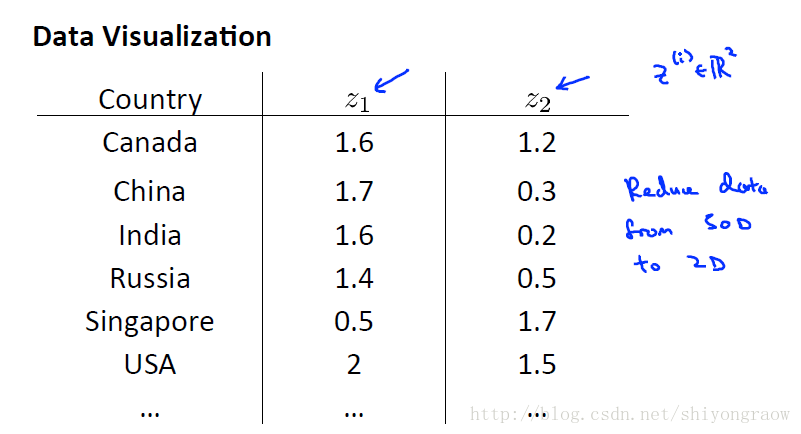
我们对50个特征降维,用一个2维向量来表示每个国家。在这个二维空间下再绘图。这就很简单了。
这里我们讲到使用降维的俩个动机,那么我们怎样去降维呢???














 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









