







 本文介绍了一个简单的爬虫开发过程,包括确定目标、分析目标、编写代码及执行爬虫。通过实例演示了如何抓取特定网站的数据,涉及URL管理、网页下载、解析与输出等关键环节。
本文介绍了一个简单的爬虫开发过程,包括确定目标、分析目标、编写代码及执行爬虫。通过实例演示了如何抓取特定网站的数据,涉及URL管理、网页下载、解析与输出等关键环节。
跟着视频学做了一个爬虫,但是却有些很烦的编码问题没能解决。
开发一个爬虫的基本步骤
①确定抓取目标,即哪些网站的哪部分数据。
②分析目标,即抓取这些网站的策略。要分析抓取的页面的url格式,用来限定要抓取的页面的范围。要分析要抓取的数据的格式,往往是对应标签的格式。要分析页面的编码,在网页解析器这里要确定编码才能进行解析。
③编写代码:爬虫调度端、url管理器、网页下载器、网页解析器、输出器等。
④执行爬虫。
在一个文件夹下建立调度程序、url管理器、网页下载器、网页解析器和输出器。注意还要建立一个__init__.py文件,虽然它是空的。
爬虫总调度程序spider_main.py
爬虫总调度程序以一个入口的url作为参数,来爬取所有相关的页面。
import url_manager,html_downloader,html_parser,html_outputer
class SpiderMain(object):
def __init__(self):#在构造器中初始化所需要的对象
self.urls=url_manager.UrlManager()#url管理器
self.downloader=html_downloader.HtmlDownloader()#下载器
self.parser=html_parser.HtmlParser()#解析器
self.outputer=html_outputer.HtmlOutputer()#价值数据的输出
def craw(self,root_url):
count=1#记录当前爬取的是第几个url
self.urls.add_new_url(root_url)#先将入口url给url管理器
#启动爬虫的循环
while self.urls.has_new_url():#如果管理器中还有url
try:
new_url=self.urls.get_new_url()#就从中获取一个url
print ('craw %d : %s'%(count,new_url))#打印正在爬的url
html_cont=self.downloader.download(new_url)#然后用下载器下载它
#调用解析器去解析这个页面的数据
new_urls,new_data=self.parser.parse(new_url,html_cont)
self.urls.add_new_urls(new_urls)#新得到的url补充至url管理器
self.outputer.collect_data(new_data)#收集数据
if count==30:#如果已经爬了30个直接退出
break
count+=1
except:
print ('craw failed')#标记这个url爬取失败
self.outputer.output_html()#循环结束后输出收集好的数据
if __name__=="__main__":
root_url="http://baike.baidu.com/item/Python"#入口url
obj_spider=SpiderMain()
obj_spider.craw(root_url)
URL管理器url_manager.py
URL管理器需要维护两个集合:待爬取的url集合和爬取过的url集合。
class UrlManager(object):
def __init__(self):
self.new_urls=set()
self.old_urls=set()
#向管理器中添加一个新的url
def add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
#向管理器中添加多个新的url
def add_new_urls(self,urls):
if urls is None or len(urls)==0:
return
for url in urls:
self.add_new_url(url)
#判断管理器中是否还有新的待爬取的url
def has_new_url(self):
return len(self.new_urls)!=0
#从管理器中获取一个新的待爬取的url
def get_new_url(self):
new_url=self.new_urls.pop()#获取并移除
self.old_urls.add(new_url)#添加至旧的集合
return new_url
网页下载器html_downloader.py
下载器只需要实现一个方法,下载一个url里的数据,这里用urllib模块。
import urllib.request
class HtmlDownloader(object):
#下载一个url里的数据
def download(self,url):
if url is None:
return None
response=urllib.request.urlopen(url)#注意py2和py3不同
if response.getcode()!=200:#状态码200表示获取成功
return None
return response.read()#返回下载好的内容
网页解析器html_parser.py
网页解析器需要接收正在爬的url和下载好的页面,返回新的url集合和当前页面的解析结果(这里用了字典)。
from bs4 import BeautifulSoup
import re
import urllib.parse
#py3中urlparse在urllib中
class HtmlParser(object):
#返回新的url集合
def _get_new_urls(self,page_url,soup):
new_urls=set()
#获取所有的链接,用正则匹配
links=soup.find_all('a',href=re.compile(r"/item/"))
for link in links:
new_url=link['href']#获取它的链接(不完全)
#将不完整的new_url按照page_url的格式拼成完整的
new_full_url=urllib.parse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
#返回对soup的解析结果
def _get_new_data(self,page_url,soup):
res_data={}
#url
res_data['url']=page_url
#<dd class="lemmaWgt-lemmaTitle-title"><h1>Python</h1>
#获取词条名(用了两次find)
title_node=soup.find('dd',class_="lemmaWgt-lemmaTitle-title").find("h1")
#注意这里先split再做join,将\\变成了\
res_data['title']='\\'.join(title_node.get_text().split('\\\\'))#加入字典中
#<div class="lemma-summary">
#获取摘要文字
summary_node=soup.find('div',class_="lemma-summary")
#注意这里先split再做join,将\\变成了\
res_data['summary']='\\'.join(summary_node.get_text().split('\\\\'))#加入字典中
return res_data
#解析一个下载好的页面的数据,并返回新的url列表和解析结果
def parse(self,page_url,html_cont):
if page_url is None or html_cont is None:
return
#创建一个bs对象(将网页字符串html_cont加载成一棵DOM树)
soup=BeautifulSoup(html_cont,'html.parser')
new_urls=self._get_new_urls(page_url,soup)
new_data=self._get_new_data(page_url,soup)
return new_urls,new_data
输出器html_outputer.py
输出器收集网页解析器所有解析好的数据(字典),放到集合里,将最后整个集合输出形成一个html网页查看。
class HtmlOutputer(object):
def __init__(self):
self.datas=[]
#收集解析好的数据
def collect_data(self,data):
if data is None:
return
self.datas.append(data)
#输出所有收集好的数据
def output_html(self):
with open('output.html','w') as fout:
fout.write("<html>")
'''fout.write("<head>")
fout.write("<meta charset=\"utf-8\">")
fout.write("</head>")'''
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>"%data['url'])
fout.write("<td>%s</td>"%data['title'])
fout.write("<td>%s</td>"%data['summary'].encode('utf-8'))
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()
运行结果
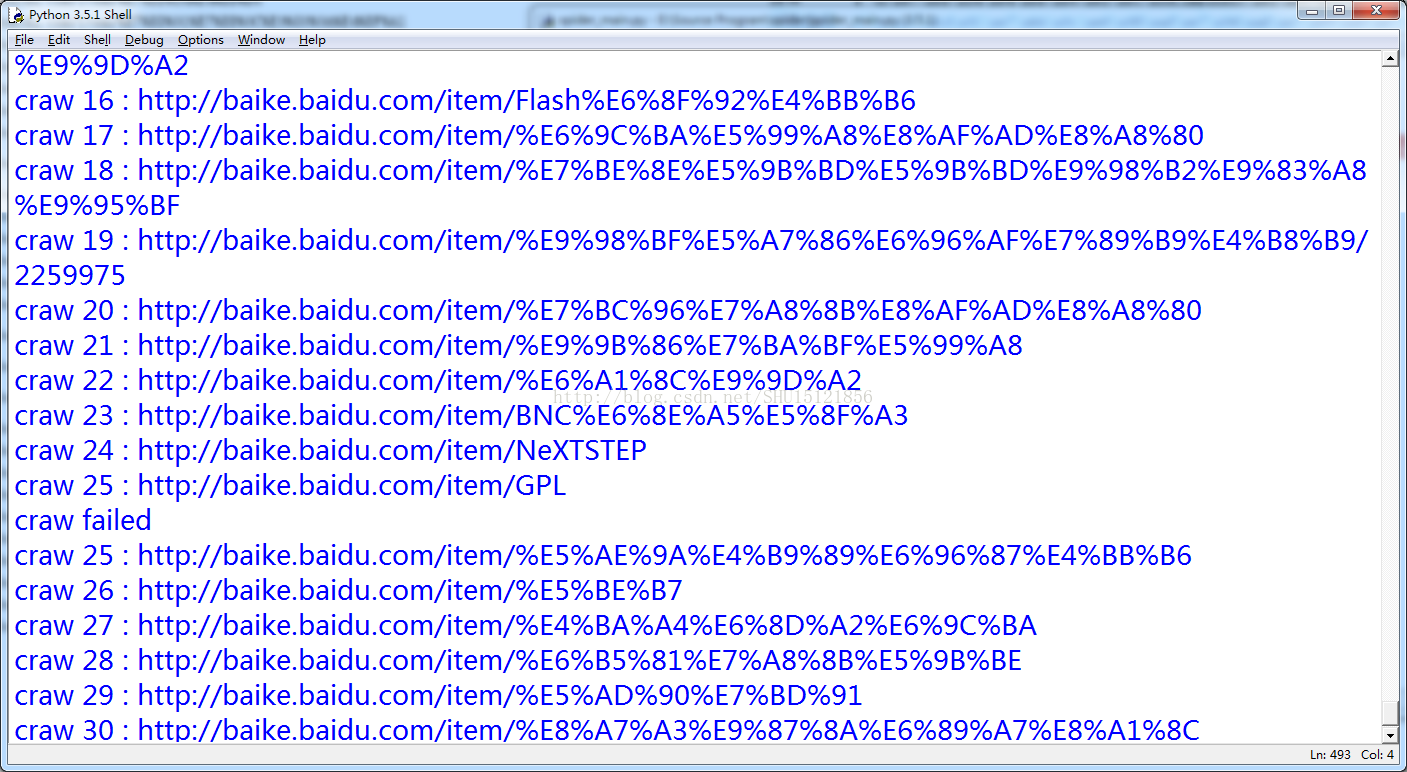

待解决的问题
网页里的摘要文字弄了很久编码问题都没能解决。一开始标题文字也是这样,后来查了一下,python里的中文单字节编码后,整个放在其它对象(如list或者tuple)里,那么反斜杠\就会被加上一个反斜杠\表示转义,那么这里就有两个反斜杠了(在串里也就是\\),这时候再整个输出就会变成\xe7这样的形式。解决方法,网上给出一种解决方法就是遍历刚刚说的'其它对象',然后每次分别输出一个单字。这样做是可以的,但是对文件进行多次写效率肯定非常低,我这里用的方法是先用split('\\\\')把字符串用两个反斜杠隔开,放进list里,然后再用'\\'.join将这些串连在一起,就把两个反斜杠变成了一个。当然也可以直接用replace('\\\\','\\')。
同样的做法,标题文字解决了,摘要文字却没能解决。而且如果摘要文字write时不做encode('utf-8')会报错,我也不清楚是怎么回事,查了很多资料也没解决。
以后再回头解决这个问题吧,如果有知道的朋友可以在评论里交流一下哈。

















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









