







本文内容来自于慕课网《Python开发简单爬虫》,感兴趣的同学可以去看视频。http://www.imooc.com/learn/563
一个简单的爬虫主要分为 调度器、URL管理器、网页下载器、网页解析器几个部分,本文只涉及不需要登录操作的简单爬虫。
1.爬虫简介
爬虫是能够自动抓取互联网信息的程序
价值:新闻聚合阅读器、图书价格对比网、Python技术文章大全
2.简单爬虫架构
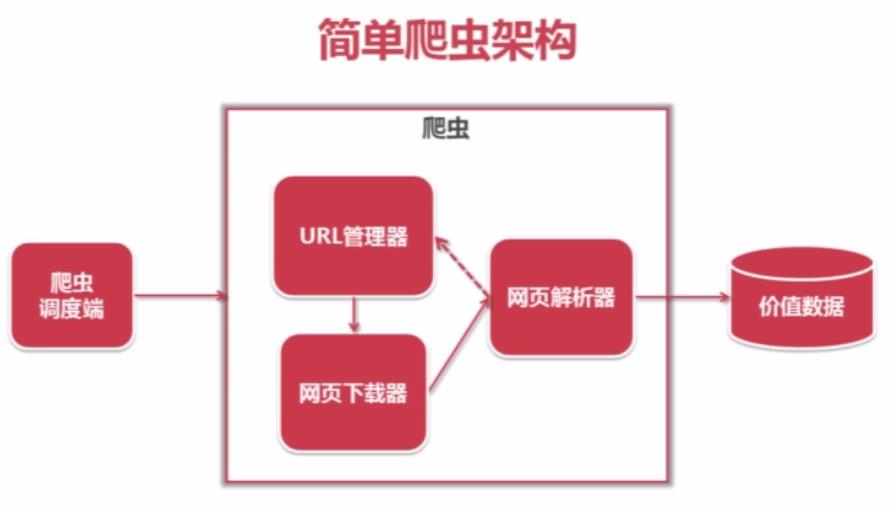
URL管理器主要负责存储URL,一个待爬取的URL通过下载器下载后传入解析器,再输出价值数据。
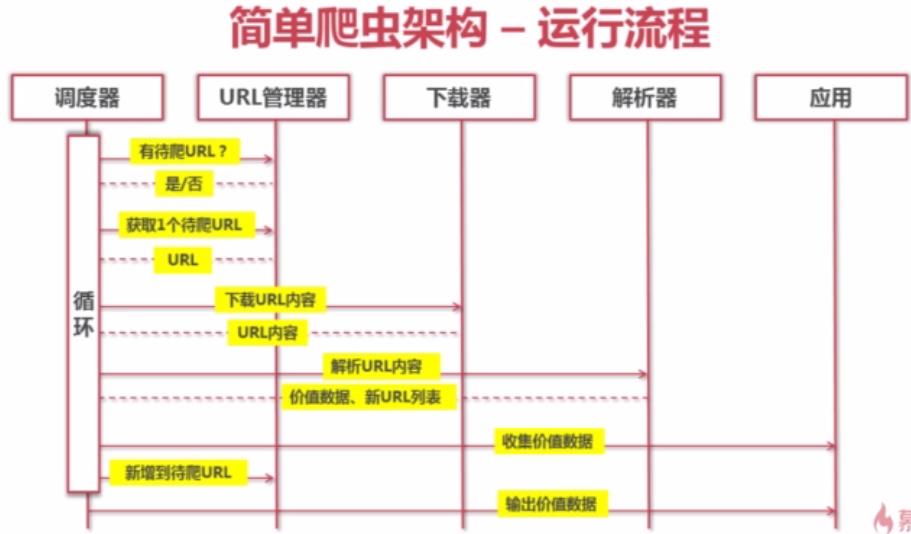
3.URL管理器
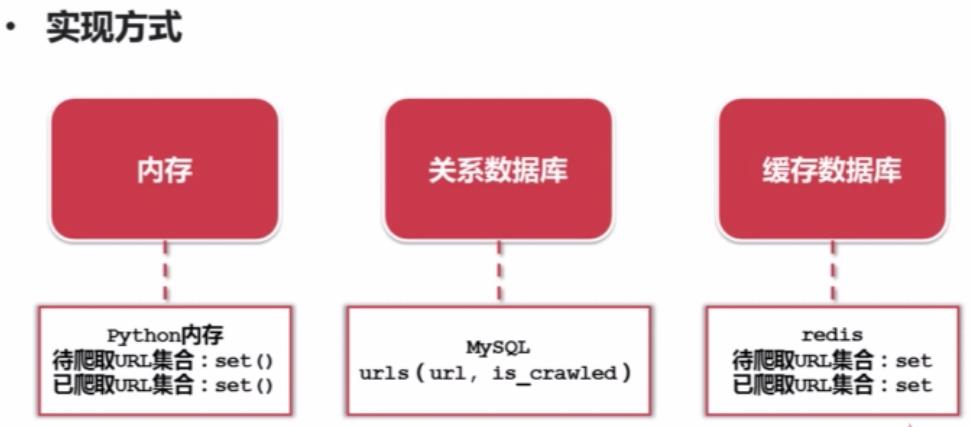
URL管理器:管理待抓取URL集合和已抓取URL集合
----防止重复抓取、防止循环抓取

4.网页下载器(urllib2)
网页下载器是将互联网上URL对应的网页下载到本地的工具,通常使用的库有
urllib2: Python官方基础模块
requests:第三方包更强大,后期推荐使用
urllib2下载网页方法1:最简洁方法 urlopen(url)
import urllib2
#直接请求
response = urllib2.urlopen('http://www.baidu.com')
# 获取状态码,如果是200表示 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









