







决策树归纳分类算法理解
决策树归纳是从类标记的训练数据构建决策树,属于分类领域。遍历根节点到全部叶节点的路径,每条路径都属于一个元组分类。整棵决策树形成分类规则。目前构造决策树的算法包括ID3(iterative dichotomy),C4.5,CART,都基于如下抽象的算法流程,现通过一个详细的数据集对算法进行详细解释:

该算法名称Generate_decision_tree(,,),递归进行决策树构建。
Input:
数据划分D,即训练数据,包含训练元组(tuples)和对应类标记。
attribute_list是候选属性集
attribute_selection_method 确定分裂准则splitting_criterion(确定将哪个属性作为第一分裂属性,应该是最合适的分裂属性),包含确定分裂属性和分裂子集/分裂点。
(分裂点:针对连续型元组(每一行数据代表一个元组);分裂子集:针对离散的数据)
Output:
决策树
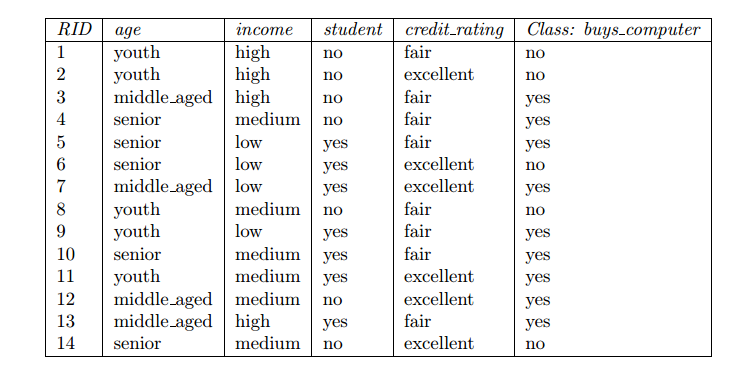
该数据集就是数据划分D,包含4个属性和及其对应的类标记。
attribute_list是{age,income,student,credit_rating}构成的候选属性集合。数据划分是根据属性选择度量(Gain、Gainratio、Gini指标)依次选取最合适的属性作为分裂属性。
以ID3算法为例:
分别计算四个属性的信息增益值:Gain(age)、Gain(income)、Gain(student), Gain(credit_rating) (具体求解见博文……)得到Gain(age)最高,故其被选为第一个最合适的分裂属性,其有三个分裂子集,分别对应youth、middle_aged、senior构成的子数据集。
算法中j表示属性age的三个值youth、middle_aged、senior。
Dj表示按这三个值分类对应的新数据划分,如下:
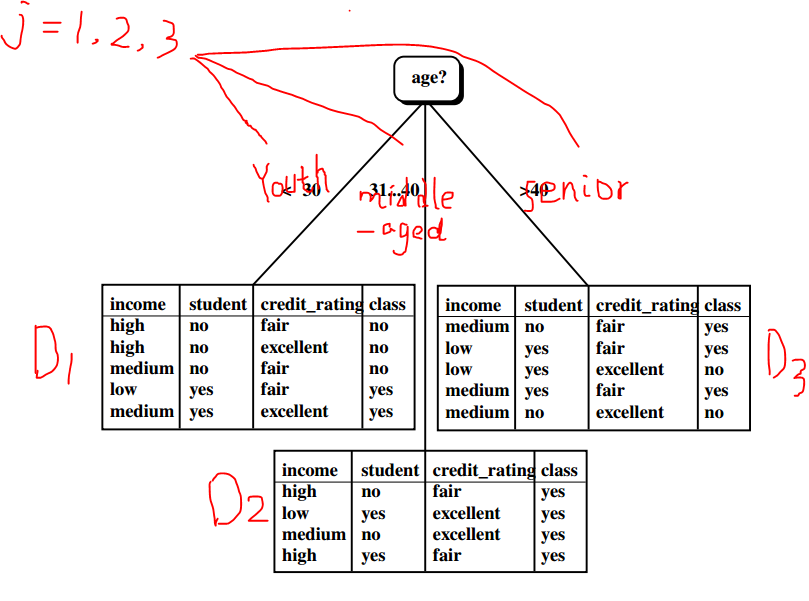
j的值就是age属性拥有的值的个数,构成了新的数据划分。然后分别针对D1,D2,D3递归调用Generate_decision_tree(,,)
递归出口:
1.Di中的元组都属于同一类,直接将其所属的类作为叶节点
2. 候选属性集attribute_list为空,将Di中的多数类作为叶节点。














 4109
4109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









