







本次介绍一篇来自小米黑科技的人脸检测文章:
《arxiv: Bootstrapping Face Detection with Hard Negative Examples》.
看完后续算法讲解之后,请自行体会人脸检测专业研究人员看到下图的感受。
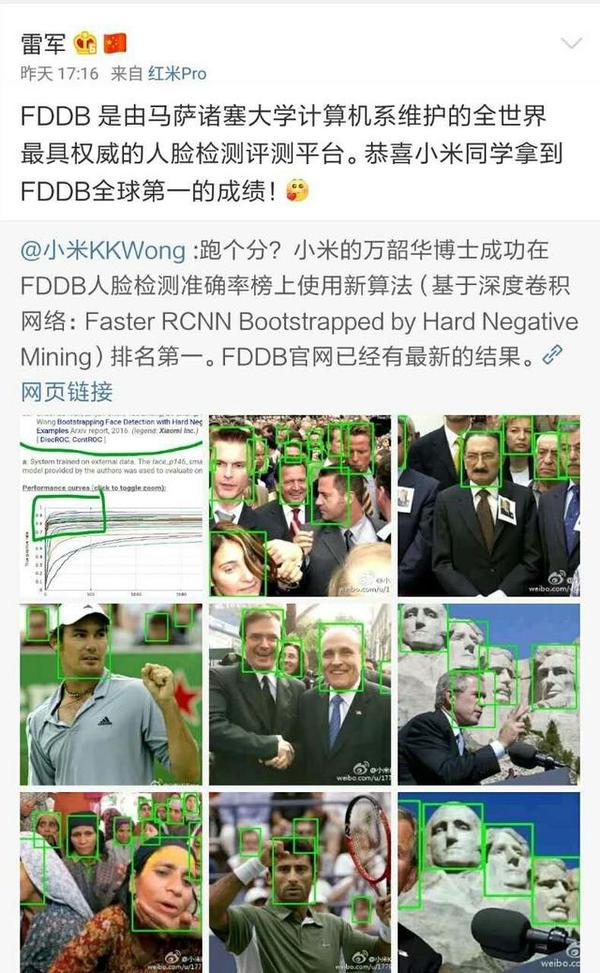
————————— 分割线 —————————
文章很短,没有创新。
核心思想: Hard Negative Mining + Faster R-CNN
要点说明:
(1)样本均衡问题:
人脸检测基本都会和二分类器有关,即分类一个窗口是或者不是人脸。易知,正样本(人脸)通常都要比负样本(非人脸)多很多很多,这种样本分布的严重不平衡会影响模型收敛。通常采取的处理策略是:在一个batch中,通过某种采样手段(random、hard mining)将正负样本的比例固定(如1:3)。小米同样采用了这种均衡策略。
(2)负例挖掘问题:
负例挖掘的本质在于大部分的窗口都很容易判断是否为人脸,这也是为什么在人脸检测领域“级联”这一思想大行其道。小米也使用了很普通的挖掘方法:先训练一个普通的Faster-R-CNN,然后把整个训练集跑一遍,选中分错的。下次finetune的时候,将选中的Hard-Negative加入训练,同时保证正负例1:3。
评价:
刷榜作品,没有创新。
刷榜时使用的是VGG和ResNet-50这种规模比较大的网络,速度堪忧。
PS. 人脸检测大家的水平其实差的不会太多,速度才是真正影响商业化的难点。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









