









视频链接:李宏毅机器学习(2016)_演讲•公开课_科技_bilibili_哔哩哔哩
课程资源:Hung-yi Lee
课程相关PPT已经打包命名好了:链接:https://pan.baidu.com/s/1c3Jyh6S 密码:77u5
我的第十七讲笔记:李宏毅机器学习2016 第十七讲 迁移学习
Support Vector Machine
本章主要讲述了支持向量机的原理。
SVM有两个特色,一个是Hinge Loss,另一个就是Kernel Method。
1.Hinge Loss
在二分类问题中,假设类标签是1和-1。

对于第一步建立函数集来说,希望能有这样一个函数,当f(x)大于0时输出为1,f(x)小于0时输出为-1。理想的损失函数想定义为出现不一致结果的次数,但是其不可微,所以考虑其他函数。
理想的函数曲线为黑色函数代表。其期望是 f(x)的值越大越好,二者变化方向一致。
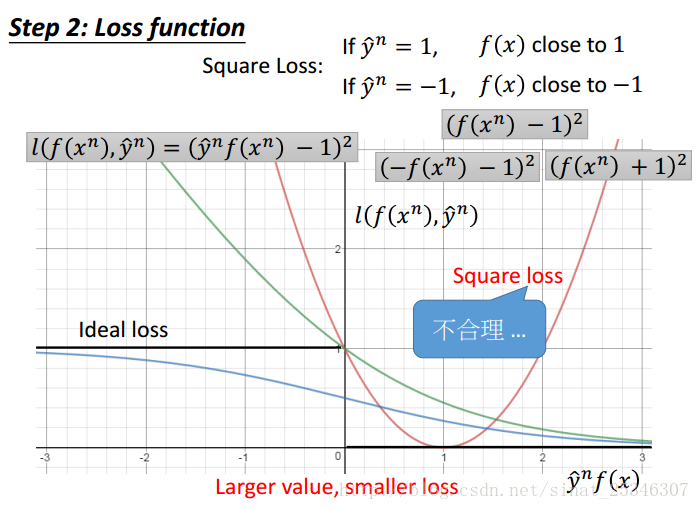
Square Loss函数曲线是红色曲线所示,其显然是不合理的,不能满足 f(x)的值越大,损失越小的要求。
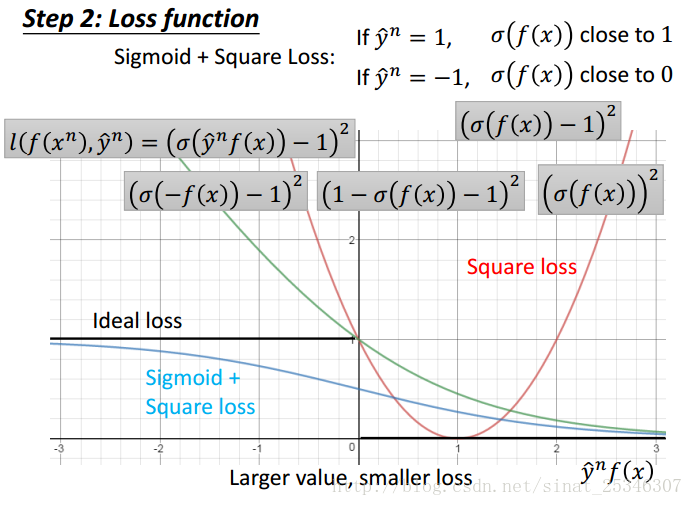
Simoid+Square Loss函数是黑曲线下方的浅蓝曲线所示。其是能够满足条件的。
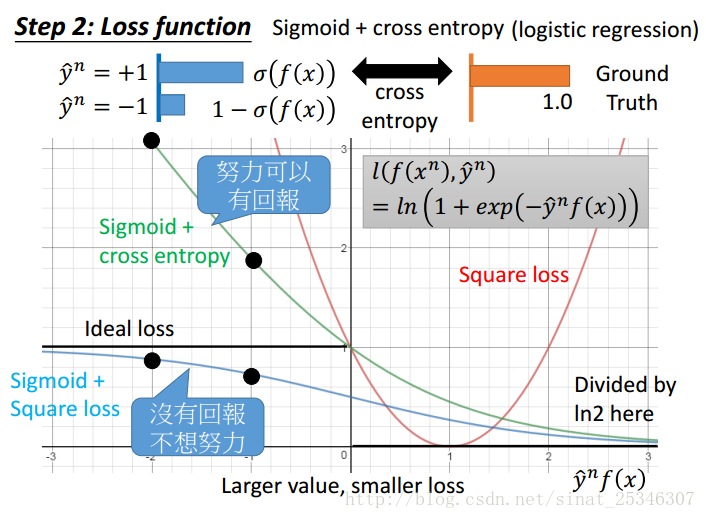
Sigmoid+cross entropy如上图黑色曲线上方的蓝色曲线所示。当 f(x)趋向于无穷大时,值就为0,是能够满足的。

Hinge Loss函数如上图中紫色曲线所示。Hinge Loss的优点在于不害怕利群点。“及格就行”
相比于logistic regression,linear SVM的区别就在于损失函数的不同,logistic regression使用的是交叉熵函数而linear用的是Hinge Loss。
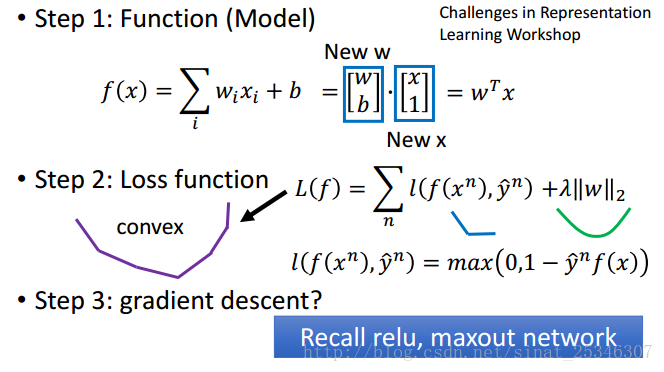
某些点不可微并不影响其使用梯度下降来求解。

通过化解可得到通常见到的SVM形式。

2.核方法(Kernel Method)
核方法是SVM的第二大特点。核方法的主要思想是基于这样一个假设:“在低维空间中不能线性分割的点集,通过转化为高维空间中的点集时,很有可能变为线性可分的” 。
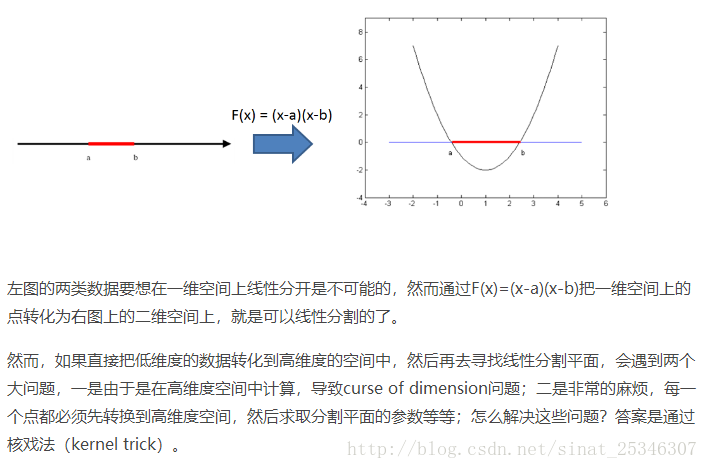
Kernel Trick:定义一个核函数K(x1,x2) = <\phi(x1), \phi(x2)>, 其中x1和x2是低维度空间中点(在这里可以是标量,也可以是向量),\phi(xi)是低维度空间的点xi转化为高维度空间中的点的表示,< , > 表示向量的内积。这里核函数K(x1,x2)的表达方式一般都不会显式地写为内积的形式,即我们不关心高维度空间的形式。
核函数巧妙地解决了上述的问题,在高维度中向量的内积通过低维度的点的核函数就可以计算了。这种技巧被称为Kernel trick。
核技巧直接计算K(x,z)能够比先进行特征转换再进行内积更快更高效。
常见的核函数之径向基函数(高斯核)

常见的核函数之sigmoid核
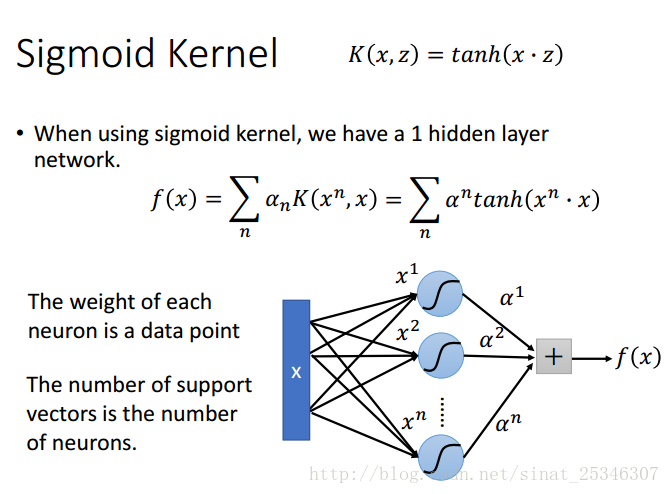
常见的核函数汇总:

此外SVM和Deep Learning是相似的。
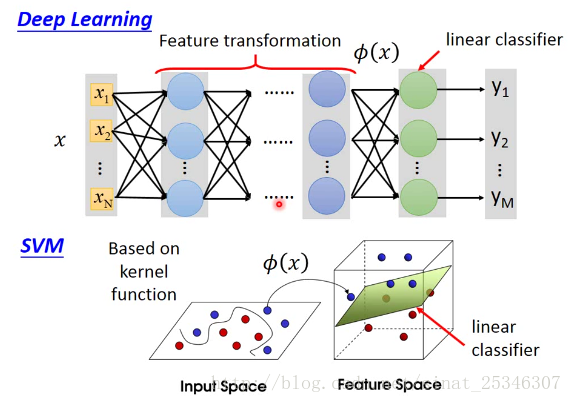
深度学习前几层可能就是在做特征转换,接着再一个线性分类。在SVM同样如此,基于核函数同样能够进行特征转换,在新的特征空间中再用线性分类器进行分类。只是深度学习中的“核函数”是更加强大的。
3.总结
本章主要讲解了支持向量机(Support Vector Machine,SVM)方法的两大特点Hinge Loss和核方法(Kernel Method)。














 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









