







网上看到很多对于朴素贝叶斯的文字描述,内容繁杂,不够简单,具体可参考该篇文章朴素贝叶斯案例,这里文字性的内容就不多说,主要强调点就是使用要求:各元素之间保持相互独立性。直接以几幅公式图来表述朴素贝叶斯的应用:
假设M,N代表文档的类别(例如,’科技’或’体育’等),而A,B,C则分别表示不同的词汇(例如,’大数据’,’云计算’等词从属于科技类新闻,而’篮球’,’足球’等词从属于体育类新闻),一般贝叶斯公示为:
::::::::::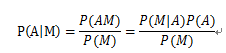
该表达式表示A词在M文档中出现的概率,即在文档M的条件下,A词出现的概率,其它形式相同。
现在,假设某文档出现A,B,C三词,需要判定该文档到底是M类还是N类了? P(M|ABC)和P(N|ABC),这两个条件概率便是计算点,其表达式表述为:
::::::
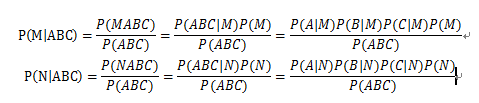
其实,从代码函数来看,我们只需要计算P(MABC)及P(NABC)即可。
总结:
朴素贝叶斯算法是一个直观的方法,使用每个属性归属于某个类的概率来做预测。你可以使用这种监督性学习方法,对一个预测性建模问题进行概率建模。
给定一个类,朴素贝叶斯假设每个属性归属于此类的概率独立于其余所有属性,从而简化了概率的计算。这种强假定产生了一个快速、有效的方法。
给定一个属性值,其属于某个类的概率叫做条件概率。对于一个给定的类值,将每个属性的条件概率相乘,便得到一个数据样本属于某个类的概率。
我们可以通过计算样本归属于每个类的概率,然后选择具有最高概率的类来做预测。















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









