







 本文介绍了如何使用Python爬虫模拟登录设有验证码的学校教务处网站,通过分析登陆过程,获取验证码图片,使用cookiejar处理session,并展示了获取个人信息的代码示例。
本文介绍了如何使用Python爬虫模拟登录设有验证码的学校教务处网站,通过分析登陆过程,获取验证码图片,使用cookiejar处理session,并展示了获取个人信息的代码示例。
其实是半年前做的一段小代码,爬取自己的学校教务处网站大概是每个学习爬虫的同学的入门必备吧(心疼一秒教务处)。其实想起来本科的时候有大神做了南理工GPA的网页,其实也就是个爬虫然后做了数据处理(只是我的猜测啦,不是请不要拍我。。),当时的教务处系统还比较简单,也没有验证码的问题,post一个表单就可以模拟登陆。但是!南理工教务处他改版了,还做的很不错(大概招了个不错的前端),加了验证码大概是这次爬虫比较大的问题了。
1.登陆过程分析
利用chrome的开发者工具,可以清楚地看出南理工研究生院登陆的过程是怎样的。首先,登陆页面长这样:
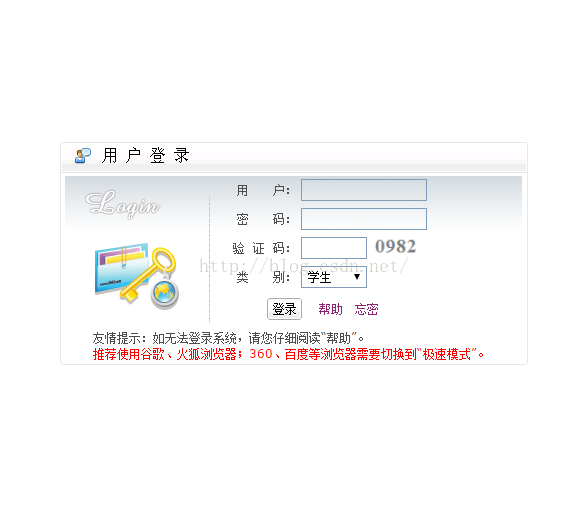
打开chrome的更多工具中的开发者工具,选择network,把preserve log勾上(这样才能把中间过程保存下来),好了,输入你的用户名密码以及验证码,点击登陆。看一下出现了一个POST方法,这个就是我们提交表单的信息了,点进去拖到最下方可以看到from data,是不是看到了你提交的用户名密码之类的信息,接下来用代码模拟登陆的话把这个data里的信息提交就可以了。
同时,登陆的时候也需要提供请求头,这个在刚刚那个post方法下面也是可以看到的。具体每个域有什么作用这个应该的HTTP协议中用的了。
Host头域指定请求资源的Intenet主机和端口号,必须表示请求url的原始服务器或网关的位置。HTTP/1.1请求必须包含主机头域,否则系统会以400状态码返回。
Accept:告诉WEB服务器自己接受什么介质类型,/ 表示任何类型,type/* 表示该类型下的所有子类型,type/sub-type。
Accept-Charset: 浏览器申明自己接收的字符集。
Authorization:当客户端接收到来自WEB服务器的 WWW-Authenticate 响应时,用该头部来回应自己的身份验证信息给WEB服务器。
User-Agent头域的内容包含发出请求的用户信息。
Referer 头域允许客户端指定请求uri的源资源地址,这可以允许服务器生成回退链表,可用来登陆、优化cache等。如果请求的uri没有自己的uri地址,Referer不能被发送。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2947
2947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









