







数据结构之二叉树
本文详细介绍了二叉树的遍历算法;根据遍历序列还原二叉树的方法;二叉搜索树及其插入、删除算法;AVL树及其插入、删除算法;红黑树及其插入和删除算法;二叉线索树、哈夫曼树以及union-find树等知识;
本文github源码(Java语言实现,现已完成至二叉平衡树,即将开始红黑树实现)
二叉树的遍历方法及特点分析
访问一棵树时:
- 先序遍历:首先访问树的根结点,然后先序遍历其左子树,最后先序遍历右子树;
- 中序遍历:首先中序遍历根结点的左子树,然后访问根结点,最后中序遍历右子树;
- 后序遍历:首先后序遍历根结点的左子树,然后后序遍历根结点的右子树,然后访问根结点;
二叉树的遍历实际上将一棵二叉树线性化,得到的序列分别称为先序序列、中序序列、后序序列;其中先序序列的第一个结点为树的根结点;而中序序列和先序序列可以还原一棵树;中序序列和后序序列也可以,但是先序序列和后序序列是不能还原一棵树的~;
还原思路如下:
首先由先序序列得到树的根结点,然后在中序序列中找到该结点;该结点以前的结点序列为根结点左子树的中序序列(后面的为右子树的中序序列),然后统计该序列的结点个数,然后在先序序列中截取根结点之后相应长度的结点序列,此序列即为左子树的先序序列,由此,重复该动作, 直到根结点的左子树构造完毕,再构造根结点的右子树即可;由于遍历一棵树最后会得到一个线性序列,所以在X序遍历得到的序列中,某结点的前驱称为X序前驱,其后继称为X序后继;
分类介绍
二叉搜索树
二叉搜索树,也叫二叉排序树。它满足这样的特点,树中任何一个结点,其左子树中所有结点的值都小于等于该结点的值,而右子树中所有结点的值都大于该结点的值;对这样的树进行中序遍历可以得到一个有序的线性表;
二叉搜索树的插入算法:
二叉搜索树的插入要保证其特性不被改变,即”左小右大”的特点,所以在插入前需要找到的合适的插入点,这个插入点的父结点一定是某个叶结点,寻找的过程就是不断比大小的过程:如果待插入结点的值大于根结点的值,那么进入根结点的右子树继续查找,反之则进入左子树查找;如果需要进入某棵树,但是这棵树为空,则此时的根结点即为插入点的父结点,返回即可;插入通过建立指针连接即可完成;二叉搜索树的删除算法:
删除同插入一样,都需要保证“左小右大”的特点。首先记录该结点的父结点P,然后分三类情况:
该结点为叶子结点:将父结点P对应的指针置空即可;
该结点只有一个子结点:将P原来指向该结点的指针指向其子结点即可;
该结点有两个子结点:第一步,寻找该结点的中序先驱(中序序列中该结点的前驱的查找:进入左子树,然后一路向右,直到叶子结点,该结点即为其中序前驱;)F;第二步,交换该结点与结点F;第三步,删除交换后的结点(同删除叶子结点的情况);
关于如何保留父结点的实现,其实寻找指针只要指向父结点就可以起到检查其子结点的目的,然后返回该指针即可。在这里是可行的,因为我们知道需要的是它的右子结点;其他情况下,还是需要一个辅助指针来记录父结点的~;
至此,二叉搜索树的相关算法介绍完毕~
AVL树
以其首创者Adelson-Velskii 和Landis命名的树;记二叉树中结点V右子树高和左子树高之差为结点V的平衡因子,所有结点的平衡因子均小于等于1的二叉树即为AVL树;AVL树是一种平衡树(高度H限定在结点个数N的对数范围内的树);AVL检索树是指既是AVL树又是检索树的树;由于AVL树的目的就是为了设计检索树(也叫搜索树),所以常使用AVL树代表AVL检索树;
AVL树的插入算法:
AVL树的插入,首先像检索树一样,将X作为叶结点插入;然后调整树高,并沿插入路线一路返回,在返回的过程中更新根结点的平衡因子,如果发现平衡因子由1变为2,或者由-1变为-2,则这棵子树失去平衡,需要调整以该结点为根的树,以便恢复平衡;否则,这棵树是平衡的,继续向上返回即可;下面讨论需要调整的各种情况,记该树根结点为P:
1)插入前hr=h,hl=h+1,树高h+2;插入后hr=h,hl=h+2(即插入使得平衡因子从-1变为-2);
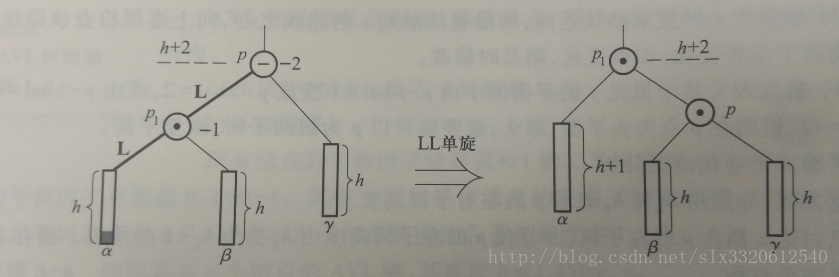
很明显的,树P失去平衡的原因是左子树高度的变大,从左子树S的角度来看,S的两棵子树必然是原来一样高,即S的左子树高等于S的右子树高=h,然后结点X的插入到S的左子树或者右子树中;(首先S作为P的子树,P需要调整平衡,那么S一定就是平衡的(S最初有可能不平衡,但是从下到上返回的时候,S就一定会被调整,所以此时S一定平衡);S平衡的情况下,高度增加,只能是平衡因子从0变为1或者从0变为-1,因为从-1到0和从1到0是不增加高度的,至此解释完毕)如果X插入到S的左子树中,那么我们为恢复平衡进行的操作为L(X首先进入P的左子树S)L(然后再进入S的左子树)单旋(通过调整一个子树的所属关系完成平衡);
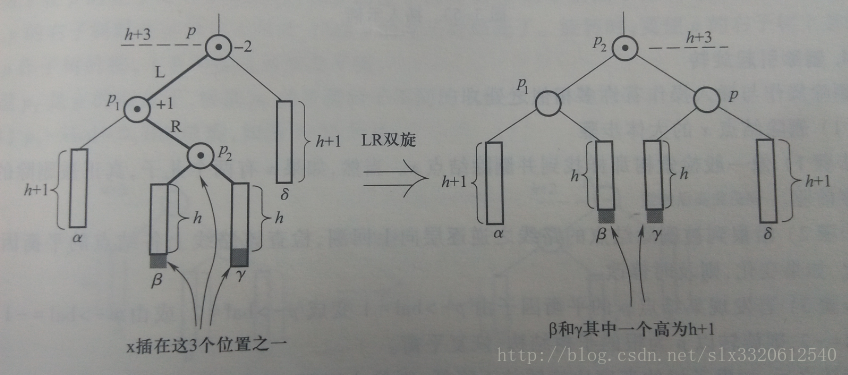
如果X插入到S的右子树中,那么我们为恢复平衡进行的操作为L(同上)R(同上)双旋(通过改变两棵子树的所属关系完成平衡);
2)插入前hr=h+1,hl=h,树高h+2;插入后hl=h,hr=h+2(即插入使得平衡因子从1变为2);这种情况和上面的情况是对称的,对应的平衡操作为RR单旋和RL双旋,由于其核心理念是一致的,所以不再列出~
从上面的分析可以看出,由于插入引起的失衡经过一次平衡操作即可恢复,这和由删除操作引起的失衡不同!
下面详细讨论LL单旋以及LR双旋的算法及其核心理念:
1)LL单旋:S的根结点作为调整后树的根结点,然后S的右子树作为P的根结点的左子树,P此时作为新树的右子树,S的左子树作为新树的左子树;交换完毕后,整棵树恢复平衡且树高h+2不变,左右子树高相同为h+1,所以回溯也停止;
2) LR双旋:将S的右子树SR的根结点作为调整后树的根结点;SR的右子树作为S的右子树;SR的左子树作为P的左子树;P作为新树的右子树;S作为新树的左子树;调整后新树高为h+2;其平衡因子为0,两棵子树高度为h+1;子树的平衡因子为(0,1)或者(-1,0),这取决于X是插入到SR的位置。
不论是LL单旋还是LR双旋,其核心都是通过调整子树的所属关系,让树保持高度不变;- AVL树的删除算法:
AVL树的删除算法设计两个概念:第一是恢复平衡,第二是回溯;回溯停止的标志是进行完恢复平衡操作后树的高度不发生变化;
首先像搜索树(检索树)一样找到真正删除的结点(一定是一个叶子结点),然后从该结点出发,逐层调整平衡并回溯;
我们假定是在P的左子树上删除了一个结点X(右子树的情况对称处理即可);
情况1:删除前p的平衡因子为0,删除后p的平衡因子为1,树的高度不变,回溯停止;
情况2:删除前p的平衡因子为-1,删除后p的平衡因为0,树的高度降低,不需要恢复平衡,但是还是要向上回溯;
情况3:删除前p的平衡因子为1,删除后p平衡因子为2,失去平衡,需要恢复平衡;此时根据p的右儿子s的平衡因子sb的取值又分为三种情况:
- sb=0;RR单旋恢复:s的根结点作为新树的根结点;原来s的左子树作为p的左子树;p作为s的左儿子;原来s的右子树还是s的右子树;此时树的高度不变,回溯停止;
- sb=1;RR单旋恢复:此时恢复完毕后,树的高度降低,继续回溯;
- sb=-1;RL双旋恢复;s的右儿子sr作为新树的根结点;原来sr的右子树作为p的左子树;sr的左子树变为s的左子树;p作为sr的右儿子;s作为sr的左儿子;树的高度降低,继续回溯;这里记得更新子树的平衡因子即可;
红黑树
红黑树也是一种二叉平衡树,也称为RB树,因其结点被标记为红色或者黑色而得名;
在二叉树中,如果一个结点缺少一个子结点,那么就认为该结点有一个空的外部结点;于是该结点便成为一个内部结点;
红黑树定义如下:红黑树是带有外部结点的且满足下列条件的二叉树:
1)每个结点不是红的就是黑的;
2)根结点是黑的;
3)外结点是黑的;
4)红结点的儿子为黑的,黑结点的儿子既可以是红的,也可以是黑的;(红不相邻);
5)根(包括子树的根结点)到外结点的每条路径上,标为黑色的结点个数相同;
下面介绍红黑树的插入和删除的伪算法算法:
百度云附属资料(伪代码书写起来影响布局,若有兴趣,请移步~)
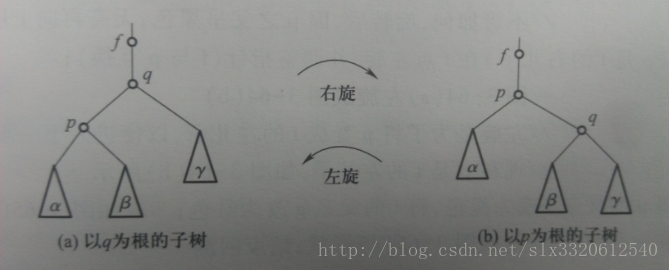
红黑树中涉及的一个重要操作便是左右旋;左右旋的时候到底发生了什么呢?
如果在x处进行了左旋,那么x将进入其左子树l的根结点位置,其右子树r的根结点将出现在x的位置;如此一来,从x通向其左子树中叶子结点的路径上就会多一个r的右结点;而通向其右子树中叶子结点的路径上就会少一个x;右旋的道理是一样的~二叉线索树:
最开始我们知道,通过二叉树的遍历,可以得到层次结构的二叉树的一个线性排列,那么在这个排列中自然也有前驱和后继的关系,特别是二叉搜索树、平衡树、AVL树以及红黑树中进行删除操作时都需要找到某结点的中序前驱;所以我们应该以某种方式将这种前驱和后继关系记录下来,方便删除操作,而不至于每次需要时都去遍历一遍二叉树;
一棵有n个结点的二叉树共有n-1条边,但是指针域中共有2n个指针,所以存在n+1个空指针;充分利用这些空指针来存储前前驱和后继关系(即为线索),可以使查找某结点的周边信息变的简单;
二叉线索树的实现应该在对应的遍历过程中完成;由于指针域可能指向子树,也有可能指向线索结点,所以每个结点还需要两个标记变量用于标记指针存储的内容(两个布尔值即可);
具体实现日后完成;
哈夫曼树:
关于哈夫曼树,其定义如下:设树T共有n个叶子结点,每个叶子结点分别带有一个正实数权值w,根结点到叶子结点的路径长度即为p,则称p*w为该叶子结点的加权路径长度;所有叶子结点的加权路径长度的和称为该树的权;对于给定的n个正实数作为叶子结点的权值,使其对应树的权最小的数称为哈夫曼树;
哈夫曼树采用从底向上的思想,逐步合并形成哈夫曼树,其思想是权值较小的叶子结点有较长的路径;权值越大,其对应的路径长度越小;
其构造算法如下:
1)构造n棵单结点的二叉树,形成初始森林,将n个正实数分别赋值给它们;
2)从森林中选取两棵权值最小的树,将其合并为一棵树并使新树的权值为其子树之和;然后将新树投入森林中;
3)重复2,直到森林中只剩一棵树,即为哈夫曼树;
union-find树:
union-find树是用来求解union-find问题而设计的一种树形数据结构,用于处理一些不相交集合的合并及查询问题;它的特点如下:
1)n个元素分别以0-n标记;
2)开始时,每个元素自成一类;每一类结点的集合名由根结点的标号表示;
3)union(a,b,c)表示将a和b合并为c集合;find(x)表示查找结点x所处的集合标号;
4)常使用父亲链域法表示树的结构;a[x]=y表示标号为x的结点其父亲标号为y;
另外,为加快运算速度,常常使用两个特殊的技术:小合并到大以及路径压缩;
小合并到大是指在两个集合合并时,总是让小集合的根作为大集合的根的儿子,这样树的高度可以比大合并到小要低,便于find操作找寻集合点;
路径压缩是指在进行find操作的时候,从起始结点其,将沿路遇到的结点都直接作为根结点的儿子,提高下一次find操作时的速度;














 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









