









通过我其他的zeppelin分析文章,大家可以从中了解zeppelin是什么样的。本篇试着阐述问题的另外一面,zeppelin为什么是这样的?本文从需求出发,探寻zeppelin的架构设计、技术选型、代码的模块划分和依赖关系最初的“出发点”。
zeppelin的核心功能用一句话总结就是:支持多语言混合的REPL(Read-Evaluation-Print-Loop)。这个核心功能的价值体现在:
站在使用者的角度,意味着:
1. 可以在一个Note中混合使用多种语言。用户可以根据需要完成的任务的类型,选择最合适的语言来实现,不再受限于单个语言的特性。例如:MarkDown能做出漂亮的文档,python和R有大量的科学计算、机器学习和可视化包,scala与Spark有天然的血缘关系,Shell处理本地文件非常方便……,可以想象一下将这些语言的优点都结合起来,会产生多么强大的生产力。
2. 数据分析和机器学习,从来都不是一个“一蹴而就”的过程。分析过程和机器学习算法一样,本质是不断迭代和试错的过程。数据科学家和算法工程师对数据分析平台最看中的能力是“有丰富的组件”和“可调试”(至少在我接触到的数据科学家和算法工程师来看是这样的),前者表达了对平台功能全面的需求,后者表达了如何对采用这些功能“平顺”地开展实际业务分析的需求,二者相辅相成。REPL相对于“拖拽式”的数据分析平台,虽然不能像传统IDE一样,设置断点和查看中间变量,但是相对于“纯黑盒”的拖拽式数据分析工具,能在很大程度上实现“调试”功能。
站在管理者的角度,意味着:
1. 使得统一工具环境成为可能。一个数据分析团队中,各成员由于擅长的语言不同,可能需要同时维护多种环境,如R、Python远程桌面开发环境,R和Python都是通过第三方扩展包进行扩展的,成员熟练使用的包,也有所不同,给运维造成了较大压力。实现一个集中式的分析工具,在服务端集中于一处,统一配置R、Python、Spark、Hadoop、Hive等开发环境,显著降低运维成本。
2. 使得进行统一安全控制成为可能。B/S系统,方便进行集中式用户权限控制,并且由于该平台”看到”的是各种语言的源码,可以对恶意代码进行监测和过滤,避免有意或者无意地对系统造成的损害。此外,可以限制所有过程都在线操作,不存在跨机器传递数据的问题,可限制导出数据,保障数据安全。
现在,让我们抛开对zeppelin的已有认知,假设让我们重新设计一个平台,实现上述核心功能,会面临哪些问题,这些问题都有哪些解决方案,各种方案又孰优孰劣,在此过程中,探寻zeppelin的设计动因和它要解决的问题。
首先看一下该平台要应对的典型场景:
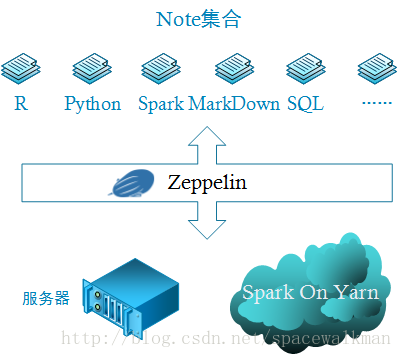
平台要解决的是:在服务端资源一定的情况下,如何尽可能正确和高效地执行多个用户混合了多种语言的Notes问题。
由于我们要实现IPython Notebook式的B/S架构的共享式的分析工具,所以至少需要一台Web服务器。一般zeppelin典型的使用方式是与spark一起使用,而spark on Yarn又是常见的spark部署方式,因此,上图就是生产环境下,zeppelin部署时的最小配置。确定了部署方式,软件设计问题会接踵而至,每种问题的解决都影响的该平台技术的选型和架构的设计:
- 各种语言的代码在哪里执行?
代码的执行是会消耗服务器资源的,资源是共享的,有限的,合理的分配代码的执行环境,对平台的扩展能力至关重要。 在有web服务器的前提下,显然不会每个用户直接连接spark集群,提交任务(否则,就退化成了每个用户在本地启动一个spark-shell了,这也就是失去了集中共享式数据分析平台建设的意义),web服务器自然成了spark集群唯一的客户端,所有用户的任务都间接通过web服务器向spark集群提交。但是,并不是所有语言写的代码都需要提交的spark集群上执行,各种不同的语言的代码“理想”的执行位置如下:
| 语言 | 单机/集群 | 代码在哪里执行 |
|---|---|---|
| R | 单机 | web服务器 |
| R(SparkR) | 集群 | Spark集群 |
| Python | 单机 | web服务器 |
| Python(PySpark) | 集群 | Spark集群 |
| MarkDown | 单机 | web服务器 |
| SQL(SparkSQL) | 集群 | Spark集群 |
| SQL(其他SQL) | 单机 | web服务器 |
| Shell | 单机 | web服务器 |
通过上表可以看出:
1. Spark集群有自己独立的资源管理器Yarn。任务的调度和资源的分配都有该资源管理器接管,这里不讨论。
2. 还有大量的语言代码,是在Web服务器本地执行的。一台Web服务器的资源是有限的,会成为限制该平台横向扩展的瓶颈。这就有必要在web服务器端,对用户执行代码的频率进行限制,如进行排队。或者将代码的执行环境从web服务器端抽取出来,额外建立一个集群(这个集群与Spark集群不同),该集群的目的很单一,就是执行web服务器发过来的各种语言的代码。它可以是“无中心”节点的方式,各自向Web服务器报告,或者是类似Yarn集群的方式,只不过获取到的container专门用来执行一段代码。
- multi-tenancy支持问题
多用户系统,每个用户创建的note,每个note执行的结果,都应该是属于该用户的。其他用户未经授权不能访问。
repl解释器应该至少实现各个用户之间隔离,因为repl解释器是执行过程中会保存context,即:之前定义的变量或者routine等,能够直接检视和使用,但是一般情况下,repl解释器不应该被共享,否则,就会出现两个用户相互影响的情况。那么问题来了,同一个用户不同的note,含有相同语言的代码,可以共享同一个repl解释器吗?这个问题抽象出来,就是repl解释器粒度问题,是per-user还是per-note的问题,2者各有优劣:
per-user模式,节省资源,同一个用户不同note之间的相同语言的代码都可以发送到同一个解释器,节省服务器资源。由于解释器同时保留多个代码段执行的上下文,这种模式可以实现跨note交换数据。同时,由于多个note共用一个repl解释器,解释器比较繁忙,用户的响应时间变长。
per-note模式,耗费服务器资源,但是代码执行速度块,用户体验好。
平台应该将选择权交给用户,提供灵活的配置功能。
- Note中paragraph执行的顺序问题
并发还是顺序执行?其实答案不是个0/1问题,而是要视代码是否具有上下文相关性而定。
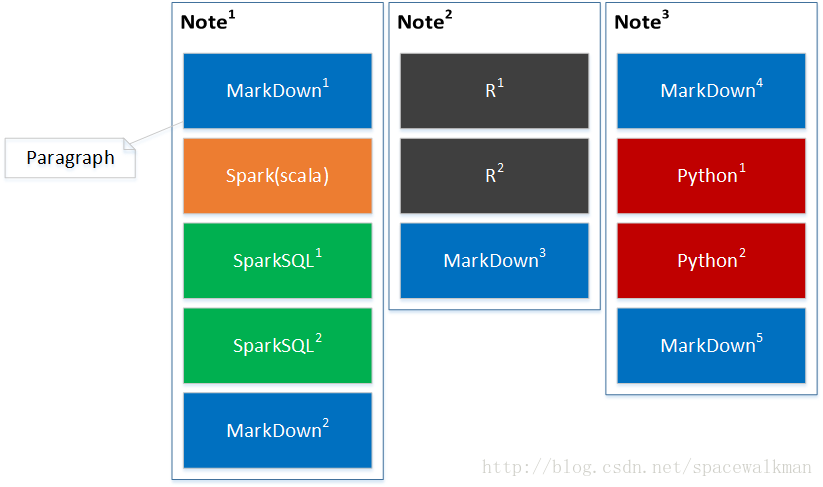
上图是Note内部构成逻辑图,一个Note由一系列paragraph(代码段)组成,代码段有序的。每个代码段只能使用一种语言,但是不同paragrah的语言可以各不相同。理想情况下,所有的代码都并行执行,以期望获得最高的执行效率,但是实际上由于大部分语言的前后代码之间存在上下文相关性,一般情况下是不能并行的。各语言代码段之间能否并行如下表所示:
| 语言 | 是否能并行 | 解释&示例 |
|---|---|---|
| R | 否 | 存在执行顺序相关性,如:前面定义的变量后面才能使用 |
| Python | 否 | 同上 |
| Spark | 否 | 同上 |
| Shell | 否 | 同上,如:只有目录存在了,才能往里面放文件 |
| SQL | 否 | 存在执行顺序相关性,DDL、DML语句会相互影响,如必须先create table才能insert数据 |
| MarkDown | 是 | 上下文无关,一段MarkDown可以独立与其他MarkDown代码独立渲染 |
可以看出,除了MarkDown之外,其他代码都是不能并发执行的。当然,不存在上下文相关性的时候,是可以并行的。例如SQL语句,在table和数据都已经存在的前提下,2条select语句是可以并发执行的。
需要提供每个repl解释器级别的并发设置,在分析师人工检查代码后,能够确定并发执行的代码,能够显式启用该设置,以提高速度。
相同的repl解释器不同的runtime依赖的问题
一个典型的场景是支持同一个产品的不同版本。只要该产品的public API不改变,通过配置修改该repl解释器的运行时依赖,就可以实现代码不变,支持多个版本的能力。
另一个典型的场景是JDBC repl解释器,使用的都是SQL语句,但是后台配置不同的连接就访问不同的库,可以是RDBMS也可以是NoSQL,每次解释器启动的时候,都要根据需要加载不同的runtime依赖,以完成Driver的加载、connection的获取以及SQL语句的执行。这要求repl解释器具有运行时动态查找、下载并加载依赖的能力。当前maven基于GAV(Group、Artifact、Version)坐标和公共repo的方式唯一定位依赖,并自动下载的方式,已经成为事实上的标准,故平台需要具有动态加载maven格式依赖包的能力。该问题也引出了下面的问题。repl解释器进程管理问题
由于同一个JVM(这里不讨论为什么采用JVM-Based语言的问题)class加载是根据classpath定义的顺序决定的,一旦找到就终止查找。这决定了要支持不同的runtime依赖和同一个产品的不同的版本,需要启动单独的JVM,以实现依赖的隔离。但是这样,问题又来了,repl解释器需要受到平台的控制。我们常用的在操作系统中启动一个R或者Python的repl进程,该进程的生命周期是只受操作系统控制的。而本平台要实现的repl解释器进程需要”受控“,即:其启动、停止、解释执行代码、输出反馈等过程都要在平台的控制下进程,以实现自动化repl进程控制,同时避免资源泄露。
再者,不同语言的repl进程,如何与JVM-Based的平台的进程进行跨语言通信,也是需要考虑的问题。常见的IPC(Inter-Process-Communication)机制,Shared-Memory、Pipe、Socket,这三种中,考虑到未来支持repl解释器集群化部署,基于Socket的实现方式是适应性最好的。平台需要确定一种IPC通信协议,规定repl解释器集成和平台之间的数据交换的格式和时序。
此外,尽可能复用多种语言的repl进程的生命周期控制逻辑,实现通用的控制,避免增加repl解释器扩展开发的工作量。
上述需求,是zeppelin的核心需求,zeppelin都给出了相应的解决方案:
| 需求 | zeppelin的解决方案 |
|---|---|
| 代码在哪里执行 | 单机版的R和Python,在Web服务器上执行,SparkR和PySpark在spark集群上执行。在zeppelinServer端进行进行调度和排队,对代码解释任务进行限流。远程启动repl进程到另外的节点上,zeppelinServer端可直接基于Socket连接到该repl解释器进程上,一定程度上解决在web服务器成为横向扩展瓶颈的问题。 |
| multi-tenancy支持 | Shiro-Based Authentication,Per-User/Per-Note两种mode的repl解释器进程共享方式,生命周期受控的多repl解释器进程。 |
| Note中paragraph执行的顺序 | 在repl解释器级别,可配置是否运允许并行执行。某些特殊的repl解释器还支持配置并发数,如JDBC。 |
| “相同的repl解释器不同的runtime依赖的问题”&“repl解释器进程管理问题” | 多JVM隔离runtime依赖。Thrift-Based跨语言IPC机制。抽象出repl解释器生命周期管理接口,各repl解释器受zeppelinServer端控制。 |
围绕着上述核心功能,zeppelin还需要提供如下“外围功能”:
方便扩展的解释器接口设计
显然,一个大数据分析工具,只有建立起良好的生态圈,才能保证长久的生命力。zeppelin显然不想只支持有限的几种语言的repl解释器。提供定义良好接口,支持二次开发,是必备项。一种将后台解释器进程的输出格式化到前端UI的能力
前面提到了python和R有大量可视化包,将这些后端输出,发送到前端,前后端一致,就跟用户在自己本机打开R和python repl进程一样,也是一必备项。当然,还提供格式化普通文本为表格的能力。配置化能力
将编译时常量变为运行时常量,抽取出来,配置文件化,可以显著提高的系统的可移植性。Hadoop生态系统大部分产品,都有xxx-default.xml和xxx-site.xml这样灵活的配置系统,zeppelin也具备这种能力。前端实时反馈能力
大数据分析,最痛苦的事情莫过于“代码跑了很长时间,最后程序挂了”。在大数据处理过程中,实时地反馈执行结果,显示进度和日志,允许用户中止正在执行的任务,是易用性的很重要的方面。持久化能力
系统所有的配置项目,所有的note代码和执行结果、权限等,系统重启之后,都需要恢复,因此需要持久化。版本控制
算法无论以什么语言表达,都是代码,是代码就避免不了版本演化问题。zeppelin对note的持久化 方式,决定了进行版本控制的难易程度,纯文本方式,则便于版本控制实现;二进制方式,则版本控制中高级特性,如版本比对,merge以及冲突解决,会很困难。Note共享平台
zeppelin自身是个工具,使用该工具做出来的面向各个行业的Note,才会产生外在价值。zeppelin官方推出的zeppelinhub代码分享平台,将广大zeppelin用户分享的note进行分门别类的整理,试图构建一个从工具到行业应用,不断反馈、改进、推广的良性的生态圈。
一些zeppelin不具备的能力(并不是完全没有,有些实现起来比较蹩脚)。
集群化部署
interperter Process已经成为制约zeppelin横向扩展的瓶颈问题。如何优雅地在多个节点上动态分布interpreter进程,并且保持zeppelin与这些进程之间的通信,是一个亟待解决的问题。目前有一些蹩脚的实现的方式,勉强实现了zeppelin的集群化部署,但却不”优雅“。安全性问题
这里是除了用户权限以外的安全问题:包括系统安全和数据安全。可以写代码,对分析师来讲是最灵活的方式,但是对系统开发者来讲,要执行用户输入的各种代码,保证系统的稳定,却是“噩梦”一般。几行简单的代码,就可以让操作系统资源耗尽。本来可以很“优雅”地表达的代码,却被写地很低效、bug频出,占用大量的后端资源,使得repl进程迟迟没有响应。数据是资产,已经成为行业共识,作为一个共享式的大数据分析工具,所有的数据操作必须是在线的,数据资产不能导出。此外,数据的加密和脱敏问题,也属于此范畴的问题。














 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









