









前言
Softmax回归模型的理论知识上一篇博文已经介绍。C++代码来源于一个开源项目,链接地址我忘了 ,哪天找到了再附上。对原代码改动不大,只是进行了一些扩充。
,哪天找到了再附上。对原代码改动不大,只是进行了一些扩充。
,哪天找到了再附上。对原代码改动不大,只是进行了一些扩充。
实验环境
Visual Studio 2013
数据
数据来自http://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits,包含了26个大写字母。
里面共有20000个样本,每个样本16维。
实验目的
完成对数据集中字符样本的分类。
实验代码
1.定义一个LogisticRegression的类:
头文件 LogisticRegression.h
#include <iostream>
#include <math.h>
#include<algorithm>
#include <functional>
#include <string>
#include <cassert>
#include <vector>
using namespace std;
class LogisticRegression {
public:
LogisticRegression(int inputSize, int k, int dataSize, int num_iters,double learningRate);
~LogisticRegression();
bool loadData(const string& filename);//加载数据
void train();//训练函数
void softmax(double* thetaX);//得到样本对应的属于某个类别的概率
double predict(double* x);//预测函数
double** getX();
double** getY();
void printX();
void printY();
void printTheta();
private:
int inputSize;//输入特征数,不包括bias项
int k;//类别数
int dataSize;//样本数
int num_iters;//迭代次数
double **theta;//学习得到的权值参数
double alpha;//学习速率
double** x;//训练数据集
double** y;//训练数据集对应的标号
};实现文件 LogisticRegression.cpp
#include "LogisticRegression.h"
LogisticRegression::LogisticRegression(int in, int out,int size, int num_iters,double learningRate) {
inputSize = in;
k = out;
alpha = learningRate;
dataSize = size;
this->num_iters = num_iters;
// initialize theta
theta = new double*[k];
for (int i = 0; i<k; i++) theta[i] = new double[inputSize];
for (int i = 0; i<k; i++) {
for (int j = 0; j<inputSize; j++) {
theta[i][j] = 0;
}
}
//initialize x
x = new double*[dataSize];
for (int i = 0; i<dataSize; i++) x[i] = new double[inputSize];
for (int i = 0; i<dataSize; i++) {
for (int j = 0; j<inputSize; j++) {
x[i][j] = 0;
}
}
//initialize y
y = new double*[dataSize];
for (int i = 0; i<dataSize; i++) y[i] = new double[k];
for (int i = 0; i<dataSize; i++) {
for (int j = 0; j<k; j++) {
y[i][j] = 0;
}
}
}
LogisticRegression::~LogisticRegression() {
for (int i = 0; i<k; i++) delete[] theta[i];
delete[] theta;
for (int i = 0; i < dataSize; i++)
{
delete[] x[i];
delete[] y[i];
}
delete[] x;
delete[] y;
}
void LogisticRegression::train() {
for (int n = 0; n < num_iters; n++)
{
for (int s = 0; s < dataSize; s++)
{
double *py_x = new double[k];
double *dy = new double[k];
//1.求出theta*x
for (int i = 0; i<k; i++) {
py_x[i] = 0;
for (int j = 0; j<inputSize; j++) {
py_x[i] += theta[i][j] * x[s][j];
}
}
//2.求出概率
softmax(py_x);
for (int i = 0; i<k; i++) {
dy[i] = y[s][i] - py_x[i];//真实值与预测值的差异
for (int j = 0; j<inputSize; j++) {
theta[i][j] += alpha * dy[i] * x[s][j] / dataSize;
}
}
delete[] py_x;
delete[] dy;
}
}
}
void LogisticRegression::softmax(double *x) {
double max = 0.0;
double sum = 0.0;
for (int i = 0; i<k; i++) if (max < x[i]) max = x[i];
for (int i = 0; i<k; i++) {
x[i] = exp(x[i] - max);
sum += x[i];
}
for (int i = 0; i<k; i++) x[i] /= sum;
}
double LogisticRegression::predict(double *x) {
double clsLabel;
double* predictY = new double[k];
for (int i = 0; i < k; i++) {
predictY[i] = 0;
for (int j = 0; j < inputSize; j++) {
predictY[i] += theta[i][j] * x[j];
}
}
softmax(predictY);
double max = 0;
for (int i = 0; i < k; i++)
{
if (predictY[i]>max) {
clsLabel = i;
max = predictY[i];
}
}
return clsLabel;
}
double** LogisticRegression::getX()
{
return x;
}
double** LogisticRegression::getY()
{
return y;
}
bool LogisticRegression::loadData (const string& filename)
{
const int M = 1024;
char buf[M + 2];
int i;
vector<int> responses;
FILE* f = fopen(filename.c_str(), "rt");
if (!f)
{
cout << "Could not read the database " << filename << endl;
return false;
}
int rowIndex = 0;
for (;;)
{
char* ptr;
if (!fgets(buf, M, f) || !strchr(buf, ','))// char *strchr(const char *s,char c):查找字符串s中首次出现字符c的位置
break;
y[rowIndex][buf[0] - 'A'] = 1;
ptr = buf + 2;
for (i = 0; i < inputSize; i++)
{
int n = 0;//存放sscanf当前已读取了的总字符数
int m = 0;
sscanf(ptr, "%d%n", &m, &n);//sscanf() - 从一个字符串中读进与指定格式相符的数据
x[rowIndex][i] = m;
ptr += n + 1;
}
rowIndex++;
if (rowIndex >= dataSize) break;
if (i < inputSize)
break;
}
fclose(f);
cout << "The database " << filename << " is loaded.\n";
return true;
}
void LogisticRegression::printX()
{
for (int i = 0; i<dataSize; i++) {
for (int j = 0; j<inputSize; j++) {
cout << x[i][j] << " ";
}
cout << endl;
}
}
void LogisticRegression::printY()
{
for (int i = 0; i<dataSize; i++) {
for (int j = 0; j<k; j++) {
cout << y[i][j] << " ";
}
cout << endl;
}
}
void LogisticRegression::printTheta()
{
for (int i = 0; i < k; i++) {
for (int j = 0; j < inputSize; j++) {
cout << theta[i][j] << " ";
}
cout << endl;
}
}#include "LogisticRegression.h"
void letter_recog()
{
double learning_rate = 0.1;
int num_iters = 500;//迭代次数
int train_N =10000;//训练样本个数
int test_N = 8;//测试样本个数
int n_in = 16;//输入特征维数
int n_out = 26;//类别数
LogisticRegression classifier(n_in, n_out, train_N, num_iters, learning_rate);
classifier.loadData("letter-recognition.data");
//训练
classifier.train();
// test data
double test_X[8][16] = {
{ 5, 10, 6, 8, 4, 7, 7, 12, 2, 7, 9, 8, 9, 6, 0, 8 },//M
{ 6, 12, 7, 6, 5, 8, 8, 3, 3, 6, 9, 7, 10, 10, 3, 6 },//W
{ 3, 8, 4, 6, 4, 7, 7, 12, 1, 6, 6, 8, 5, 8, 0, 8 },//N
{ 1, 0, 1, 0, 0, 7, 8, 10, 1, 7, 5, 8, 2, 8, 0, 8 },//H
{ 3, 6, 5, 5, 6, 6, 8, 3, 3, 6, 5, 9, 6, 7, 5, 9 },//R
{ 7, 11, 11, 8, 7, 4, 8, 2, 9, 10, 11, 9, 5, 8, 5, 4 }, //X
{ 6, 9, 6, 4, 4, 8, 9, 5, 3, 10, 5, 5, 5, 10, 5, 6 },//P
{ 4, 7, 6, 5, 5, 8, 5, 7, 4, 6, 7, 9, 3, 7, 6, 9 }//Q
};
// test
for (int i = 0; i<test_N; i++) {
double predict = classifier.predict(test_X[i]);
char char_predict = 'A' + predict;
cout << "predict:" << char_predict << endl;
}
}
int main() {
letter_recog();
getchar();
return 0;
输出结果:
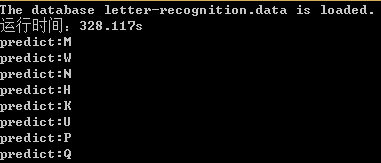
程序中用了前1w个样本来训练分类器,整个训练过程花了328.117s。为了加快程序的运行速度,决定使用OpenMP来加速for循环。
在Visual Studio里面使用OpenMP很简单。
点击项目-->属性,进入属性页。在c/c++下面的Language中开启Open MP Support即可。

修改过后的train函数:
void LogisticRegression::train() {
for (int n = 0; n < num_iters; n++)
{
#pragma omp parallel for
for (int s = 0; s < dataSize; s++)
{
double *py_x = new double[k];
double *dy = new double[k];
//1.求出theta*x
for (int i = 0; i<k; i++) {
py_x[i] = 0;
for (int j = 0; j<inputSize; j++) {
py_x[i] += theta[i][j] * x[s][j];
}
}
//2.求出概率
softmax(py_x);
#pragma omp parallel for
for (int i = 0; i<k; i++) {
dy[i] = y[s][i] - py_x[i];//真实值与预测值的差异
for (int j = 0; j<inputSize; j++) {
theta[i][j] += alpha * dy[i] * x[s][j] / dataSize; //- lambda*theta[i][j];
}
}
delete[] py_x;
delete[] dy;
}
}
}
修改过后的softmax函数:
void LogisticRegression::softmax(double *x) {
double max = 0.0;
double sum = 0.0;
for (int i = 0; i<k; i++) if (max < x[i]) max = x[i];
#pragma omp parallel for
for (int i = 0; i<k; i++) {
x[i] = exp(x[i] - max);//防止数据溢出
sum += x[i];
}
#pragma omp parallel for
for (int i = 0; i<k; i++) x[i] /= sum;
}
输出结果:
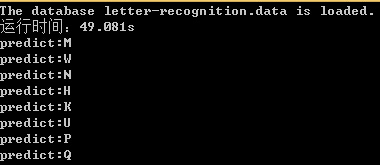
训练时间从之前的328.117s较少到49.081s,提升了6.68倍。
从测试结果来看,分类器把R预测成了K,把X预测成了U。本文没有对分类器的准确率进行严格的测试,有兴趣的同学可以自己去测一下。















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









