









前言
神经网络的理论知识上一篇博文已经介绍。本文主要是通过编程实现神经网络模型,并对给定样本集进行分类。我们知道神经网络分为输入层、隐层和输出层。各层在通过前向传播计算激活值和反向传播计算偏导数的时候,只要分清楚该层的输入、输出即能正确编程实现。
本文的C++代码主要来自于万能的网络,感谢众大神的开源精神。
实验环境
Visual Studio 2013
数据
数据来自http://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits,包含了26个大写字母。
里面共有20000个样本,每个样本16维。
神经网络模型
step1 构建神经网络
神经网络对应的C++类NeuralNetwork定义如下:
#ifndef NEURALNETWORK_H
#define NEURALNETWORK_H
#include "HiddenLayer.h"
#include "Softmax.h"
#include <fstream>
#include <string>
using namespace std;
class NeuralNetwork
{
public:
NeuralNetwork(int n, int n_i, int n_o, int nhl, int*hls, int _num_iters, double _alpha);
~NeuralNetwork();
void train();
double predict(double* in_data);
bool loadData(const string& filename);//加载数据
private:
int dataSize; //样本数量
int inputSize; //输入维数
int k; //输出维数
int n_hidden_layer; //隐层数目
int* hidden_layer_size; //中间隐层的大小 e.g. {3,4}表示有两个隐层,第一个有三个节点,第二个有4个节点
HiddenLayer **hidden_layer;//隐层
Softmax *output_layer;//输出层
double** x;//训练数据集
double** y;//训练数据集对应的标号
bool isLoadData;//如果没有加载x,y,只是加载训练好的模型,isLoadData=false;
int num_iters;//迭代次数
double alpha;//learning rate
};
#endif</span>
本文构建的神经网络结构包括:
输入层:16维,激活函数:sigmoid
隐层:2个,每层100维,激活函数:sigmoid
输出层:26维,激活函数:softmax
对应的C++代码如下:
const int ihiddenSize = 2;//隐层数
int phidden[ihiddenSize] = { 100, 100 };//每个隐层的size
int n_train = 16000;//训练样本数
int in_node = 16;//输入维数
int out_node = 26;//类别数
int num_iters = 500;
double alpha = 0.1;//learning rate
NeuralNetwork neural(n_train, in_node, out_node, ihiddenSize, phidden, num_iters, alpha);</span>真正构建网络是通过NeuralNetwork类的构造函数:
/**
*参数说明
*@param n 训练样本数
*@param n_i 输入层维数
*@param n_o 输出层维数
*@param nhl 隐层数
*@param hls 每个隐层的维数
*@param _num_iters 梯度下降迭代次数
*@param _alpha 梯度下降学习率
*/
NeuralNetwork::NeuralNetwork(int n, int n_i, int n_o, int nhl, int *hls, int _num_iters, double _alpha)
{
dataSize = n;
inputSize = n_i;
k = n_o;
n_hidden_layer = nhl;
hidden_layer_size = hls;
num_iters = _num_iters;
alpha = _alpha;
//构造隐层
hidden_layer = new HiddenLayer*[n_hidden_layer];
for (int i = 0; i < n_hidden_layer; ++i)
{
if (i == 0)
{
hidden_layer[i] = new HiddenLayer(inputSize, hidden_layer_size[i]);//第一个隐层以训练数据作为输入
}
else
{
hidden_layer[i] = new HiddenLayer(hidden_layer_size[i - 1], hidden_layer_size[i]);//其他隐层以上一层的输出作为输入
}
}
//输出层,把隐层最后一层学习到的特征作为输入
output_layer = new Softmax(hidden_layer_size[n_hidden_layer - 1], k, dataSize);//最后的softmax层
}step2 训练神经网络
训练神经网络最重要的2步分别是前向传播和反向传播,因此需要为隐层和输出层提供相应的函数。
step2.1 隐层的前向传播和反向传播方法定义
首先看下隐层C++类HiddenLayer的定义:
#ifndef HIDDENLAYER_H
#define HIDDENLAYER_H
/*********隐层使用sigmoid函数作为激活函数*******************/
class HiddenLayer{
public:
HiddenLayer(int n_i, int n_o);
~HiddenLayer();
void forward_propagation(double* input_data);
void back_propagation(double *pdinputData, double *pdnextLayerDelta,
double** ppdnextLayerW, int iNextLayerOutNum, double dlr, int N);
/*********获取类的私有属性**********/
double * getDelta();
double * getOutputData();
int getInputSize();
int getOutputSize();
double** getWeight();
double* getBias();
private:
int inputSize;//输入维数
int outputSize;//输出维数
double** w;//权值
double*b;//bias
//本层前向传播的输出值,作为下一层的输入值
double* output_data;
//反向传播时各层的残差
double* delta;
};
#endif在类HiddenLayer里面有两个很重要的方法:forward_propagation和back_propagation,顾名思义是用于前向传播和反向传播计算的。
//在给定权值和bias的时候,求出每层节点的激活值
void HiddenLayer::forward_propagation(double* pdinputData)
{
#pragma omp parallel for
for (int i = 0; i < outputSize; ++i)
{
//1.得到每个输出节点的输入
output_data[i] = 0.0;
for (int j = 0; j < inputSize; ++j)
{
output_data[i] += w[i][j] * pdinputData[j];
}
output_data[i] += b[i];
//2.输入通过激活函数映射成输出
output_data[i] = sigmoid(output_data[i]);
}
}
//compute gradients for all parameters in the network using the squared error loss function
void HiddenLayer::back_propagation(double *pdinputData, double *pdnextLayerDelta,
double** ppdnextLayerW, int iNextLayerOutNum, double dlr, int N)
{
double* sigma = new double[outputSize];
for (int i = 0; i < outputSize; ++i)
sigma[i] = 0.0;
#pragma omp parallel for
//对于隐层的每个神经元来说,都有自己的输入和输出
//step1 得到误差的响应值
for (int j = 0; j < iNextLayerOutNum; ++j)
{
for (int i = 0; i< outputSize; ++i)
{
sigma[i] += ppdnextLayerW[j][i] * pdnextLayerDelta[j];
}
}
#pragma omp parallel for
//step2 得到本层的残差delta
for (int i = 0; i < outputSize; ++i)
{
delta[i] = sigma[i] * output_data[i] * (1 - output_data[i]);
}
#pragma omp parallel for
//step3 调整本层的权值w
for (int i = 0; i < outputSize; ++i)
{
for (int j = 0; j < inputSize; ++j)
{
w[i][j] += dlr * delta[i] * pdinputData[j];
}
b[i] += dlr * delta[i];
}
delete[] sigma;
}step2.2 输出层的前向传播和反向传播方法定义
由于输出层选择的是Softmax,因此Softmax类的定义可参考之前的博文Softmax回归C++实现,只是此处增加了2个方法。新的Softmax类定义如下:
#ifndef SOFTMAXEGRESSION
#define SOFTMAXEGRESSION
//输出层使用softmax进行分类
class Softmax
{
public:
Softmax(int n_i, int i_o, int);
~Softmax();
void forward_propagation(double* input_data);
void back_propagation(double* input_data, double* label, double lr);
void softmax(double* x);
double predict(double *);
/*********获取类的私有属性**********/
double * getDelta();
double * getOutputData();
int getInputSize();
int getClassNum();
double** getWeight();
double* getBias();
private:
int inputSize;//输入特征数
int k;//类别数
int n_train;//训练样本总数
double** w;//权值
double* b;//bias
double* output_data;//本层前向传播的激活值
//反向传播时所需值
double* delta;//残差
};
#endifSoftmax类的前向传播和反向传播方法定义如下:
//求出每层的激活值
void Softmax::forward_propagation(double* input_data)
{
for (int i = 0; i < k; ++i)
{
output_data[i] = 0.0;
for (int j = 0; j < inputSize; ++j)
{
output_data[i] += w[i][j] * input_data[j];
}
output_data[i] += b[i];
}
softmax(output_data);
}
//反向求导
void Softmax::back_propagation(double* input_data, double* label, double lr)
{
for (int i = 0; i < k; ++i)
{
delta[i] = label[i] - output_data[i];//输出层的error
for (int j = 0; j < inputSize; ++j)
{
w[i][j] += lr * delta[i] * input_data[j] / n_train;
}
b[i] += lr * delta[i] / n_train;
}
}
step2.3 用梯度下降算法训练神经网络
在得到各层相应的前向传播和反向传播方法后,就可以调用NeuralNetwork类的训练方法对整个神经网络进行训练。训练代码如下:
void NeuralNetwork::train()
{
for (int epoch = 0; epoch < num_iters; ++epoch)
{
double e = 0.0;
for (int i = 0; i < dataSize; ++i)//batch gradient descent
{
/**************************前向传播阶段,求出每层的激活值(预测值)******************************************/
for (int n = 0; n < n_hidden_layer; ++n)
{
//===》输入层
if (n == 0) //第一个隐层直接输入数据
{
hidden_layer[n]->forward_propagation(x[i]);
}
//===》隐层
else //其他隐层用前一层的输出作为输入数据
{
hidden_layer[n]->forward_propagation(hidden_layer[n - 1]->getOutputData());
}
}
//===》输出层
//输出层使用最后一个隐层的输出作为输入数据
output_layer->forward_propagation(hidden_layer[n_hidden_layer - 1]->getOutputData());
/**************************反向传播阶段,链式求导******************************************/
//===》输出层
output_layer->back_propagation(hidden_layer[n_hidden_layer - 1]->getOutputData(), y[i], alpha);
//===》隐层
for (int n = n_hidden_layer - 1; n >= 1; --n)
{
//隐层的最后一层
if (n == n_hidden_layer - 1)
{
hidden_layer[n]->back_propagation(hidden_layer[n - 1]->getOutputData(),
output_layer->getDelta(), output_layer->getWeight(), output_layer->getClassNum(), alpha, dataSize);
}
else
{
hidden_layer[n]->back_propagation(hidden_layer[n - 1]->getOutputData(),
hidden_layer[n + 1]->getDelta(), hidden_layer[n + 1]->getWeight(), hidden_layer[n + 1]->getOutputSize(), alpha, dataSize);//以下一层的残差作为输入
}
}
//隐层的第0层
if (n_hidden_layer > 1)
hidden_layer[0]->back_propagation(x[i],
hidden_layer[1]->getDelta(), hidden_layer[1]->getWeight(), hidden_layer[1]->getOutputSize(), alpha, dataSize);
else
hidden_layer[0]->back_propagation(y[i],
output_layer->getDelta(), output_layer->getWeight(), output_layer->getClassNum(), alpha, dataSize);
}
}
}代码测试:
#include <iostream>
#include "NeuralNetwork.h"
using namespace std;
int main()
{ cout << "****mlp****" << endl;
const int ihiddenSize = 2;//隐层数
int phidden[ihiddenSize] = { 100, 100 };//每个隐层的size
int n_train = 16000;//训练样本数
int in_node = 16;//输入维数
int out_node = 26;//类别数
int num_iters = 10000;//迭代次数
double alpha = 0.1;//learning rate
NeuralNetwork neural(n_train, in_node, out_node, ihiddenSize, phidden, num_iters, alpha);
neural.loadData("letter-recognition.data");
neural.train();
cout << "trainning complete..." << endl;
double test_X[11][16] = {
{ 5, 10, 6, 8, 4, 7, 7, 12, 2, 7, 9, 8, 9, 6, 0, 8 },//M
{ 6, 12, 7, 6, 5, 8, 8, 3, 3, 6, 9, 7, 10, 10, 3, 6 },//W
{ 3, 8, 4, 6, 4, 7, 7, 12, 1, 6, 6, 8, 5, 8, 0, 8 },//N
{ 1, 0, 1, 0, 0, 7, 8, 10, 1, 7, 5, 8, 2, 8, 0, 8 },//H
{ 3, 6, 5, 5, 6, 6, 8, 3, 3, 6, 5, 9, 6, 7, 5, 9 },//R
{ 7, 11, 11, 8, 7, 4, 8, 2, 9, 10, 11, 9, 5, 8, 5, 4 }, //X
{ 6, 9, 6, 4, 4, 8, 9, 5, 3, 10, 5, 5, 5, 10, 5, 6 },//P
{ 4, 7, 6, 5, 5, 8, 5, 7, 4, 6, 7, 9, 3, 7, 6, 9 },//Q
{ 2, 8, 4, 6, 2, 12, 2, 4, 3, 11, 2, 10, 3, 6, 3, 9 },//A
{ 3, 9, 5, 7, 3, 8, 9, 4, 1, 6, 12, 8, 2, 10, 0, 8 },//V
{ 2, 4, 3, 3, 2, 5, 10, 3, 5, 10, 9, 5, 1, 10, 3, 6 }//F
};
for (int i = 0; i < 11; i++)
{
char res = neural.predict(test_X[i]) + 'A';
cout << res;
}
getchar();
return 0;
}输出结果:
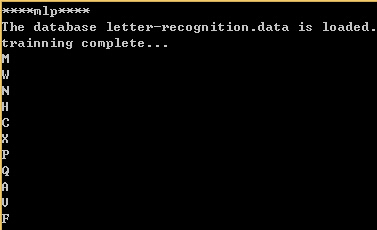
从输出结果来看,把R错分成了C。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









