Linear Regression总结
作者:洞庭之子
微博:洞庭之子-Bing
(2013年11月)
关于linear regression,Andrew Ng老师的课程中介绍了两种方法:gradient descent(梯度下降法)和normal equation,《机器学习实战》中直接使用的normal equation及其改进方法,本文记录对着两种方法的学习笔记。
第一部分,Gradient Descent方法
上一篇博客总结的是logistic regression(http://blog.csdn.net/dongtingzhizi/article/details/15962797),这一篇反过来总结linear regression,实际上这篇应该写在前面的。由于在上一篇中对regression问题的步骤、递归下降方法、向量化(vectorization)等都做了很详细的说明,在这一篇中将不再重复,需要的话可以回过头去看上一篇。
上一篇中介绍的regression问题的常规步骤为:1,寻找h函数(即hypothesis);2,构造J函数(损失函数);3,想办法是的J函数最小并求得回归参数(θ),下面一次看看这些步骤。
(一)h函数
每个训练样本有n个特征,例如Andrew Ng老师的课程中给的房价预测的例子,影响房价的因素有n个,如下图:
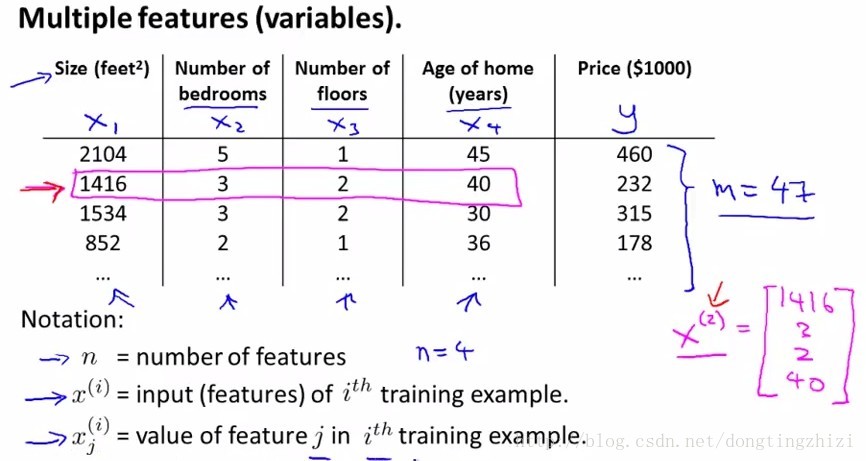
一般表示格式按如下约定,第i条样本的输入x(i):
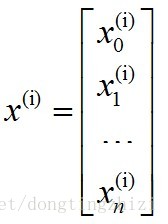
所有训练样本的输入表示为x,输出表示为y:
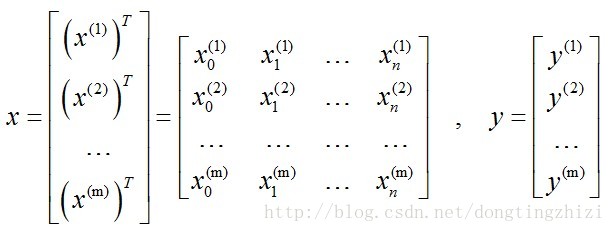
θ就是我们要求的回归参数,因为是线性回归,所以为没个特征x(i)添加一个参数θ(i),所以h函数的形式如下:

为了公式表示方便,将x0设定为1,同时将所有θ表示成向量:
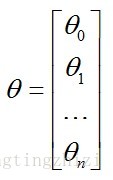
则有:
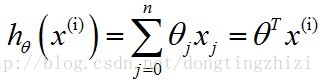 .
.
(二)J函数
linear regression中一般将J函数取成如下形式:
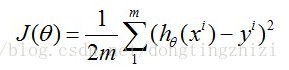
至于为什么取成该式,这里不进行深入的分析和推导,网上有一篇文章《Standford机器学习+线性回归CostFunction和Normal+equation的推导》进行了推导,可供参考。
(三)gradient descent
用梯度下降法求J(θ)的最小值,梯度下降法就是如下的过程(α表示学习率):
对于上面给出的J(θ),有:
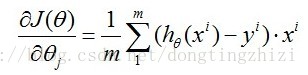
所以θ的迭代公式为:
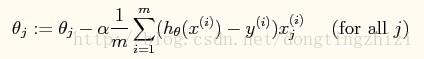
(四)其他问题
1. Feature scaling
Feature scaling可以通俗的解释为:将不同特征的取值转换到差不多的范围内。因为不同特征的取值有可能有很大的差别(几个数量级),例如下图中的x1和x2差别就非常大。这样会带来什么后果呢?从左图中可以看出,θ1-θ2的图形会是非常狭长的椭圆形,这样非常不利于梯度下降(θ1方向会非常“敏感”,或者说来回“震荡”)。进行scaling处理后,不同特征的规模相似,因此右图中的θ1-θ2图形会近似为圆形,这样更加适合梯度下降算法。
scaling也有不同的方法:
(1)例如上图中就是用特征值除以该组特征的最大值;
(2)下图中的mean normalization方法(姑且称为“均值归一化”),即用特征值先减去该组特征的平均值,然后再除以该组特征的最大值;
(3)上面两种方法显然还不是最合理的,下图的底部给出的公式x(i) = (x(i) - u(i)) / s(i),x(i)表示x的第i组特征(例如房屋面积,或者卧室数目等),u(i)表示第i组特征的均值,s(i)表示第i组特征的范围(最大值减最小值)或者标准差。
使用(3)中标准差的方法对前面的训练样本x矩阵进行归一化的代码如下:
2. vectorization
这样,不需要for循环,使用矩阵计算可以一次更新θ矩阵。
3. 关于学习率α
α的选取对于梯度下降法是非常关键的,选取合适的话J(θ)能顺利下降并最终收敛,如果选取不合适的话J(θ)可能下降非常缓慢,也有可能最终发散。
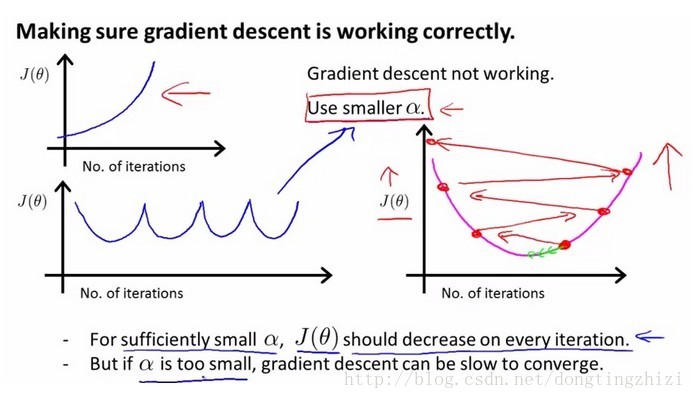
下图是J(θ)随迭代过程顺利下降的情况,图中还提到:可以声明当一次迭代后J(θ)减小的幅度小于某个阈值(如10e-10)时认为已经收敛,此时可以停止迭代过程。
下图是递归下降失败的情况,J(θ)未能随每次迭代顺利下降,说明α太大,当α充分小时,每一步迭代J(θ)都会下降的。所以,此时可以尝试减小α。
但是,当α过于小时,J(θ)会下降的非常缓慢,因此需要迭代更多次数才能达到效果,浪费计算资源。所以要选择合适的α值,太大太小都不合适。一般在训练样本时,多次尝试不同的α值,对比结果(可以绘制出J(θ)迭代的图形)后进行选择。Andrew Ng老师在课程中也给出了α尝试的方法:先选择一个较小的α值,收敛太慢的话以3倍来增加α值。
第二部分,Normal equation方法
因为
gradient descent方法需要迭代很多次是的J(θ)达到最小值求得θ,自然而然的会有一种疑问:能不能不迭代,一次求得所需的θ呢?答案是肯定的,
normal equation就是这样一种方法。关于normal equation,Andrew ng老师的课程中介绍的非常简单,几乎是直接给出了下面的公式。《机器学习实战》中也没有讲具体的推导,也是给出了该公式(P138页)。但是,二者都提到一个基本的数学原理,那就是当J(θ)对所有θj的偏导等于0时,J(θ)取最小值(高等数学中有当导数等于0时函数达到极值)。
《机器学习实战》中(P138页)提到对矩阵(y-Xw)T(y-Xw)求导,得到XT(y-Xw),令其等于零可以解得上面的公式,这里我真心没有明白,求高手解释。
网上的一篇文章《Standford机器学习+线性回归CostFunction和Normal+equation的推导》给出了推导过程,应该是靠谱的。
此时,真心觉得自己的线性代数太弱爆了,急需恶补啊!(等补补线性代数再回过头来看看吧)
正如Andrew ng老师所说,不管对该公式的推导过程理不理解,并不妨碍使用该公式进行Linear Regression处理。
(1)关于non-invertibility
当|XTX|=0时XTX是不可求逆矩阵的,如何使用normal equation呢?下面是Andrew ng老师的课程中给出的:
两种可能的解决方法:1.如果存在冗余的特征(冗余特征间存在线性依赖),去掉冗余特征;2.特征数量太大(m<=n,即样本数小于特征数),应该去掉一些特征或者使用regularization。regularization是一种消除overfitting的方法,Andrew ng老师的课程中有详细的介绍,使用了regularization的normal equation方法就不存在non-invertibility的问题了,貌似就是《机器学习实战》中介绍的局部加权线性规划方法。
《机器学习实战》中甚至介绍了更多的normal equation改进方法:局部加权线性规划,岭回归,lasso,前向逐步回归。功力不够,还没能好好理解,得继续努力啊!
总结
对比一下上面两种方法,下图是Andrew ng老师的课程中给出的:
总结一下二者的优缺点:
(1)gradient descent需要选择一个合适的学习率α,前面讲到过,要寻找一个合适的α的过程时比较繁琐的(绘制J(θ)的收敛趋势图进行对比);
(2)gradient descent需要迭代很多次,而normal equation只需一次计算;
(3)当n(特征数)非常大时,gradient descent没有问题,但是normal equation的效率会非常低。解释一下:normal equation方法使用的是矩阵计算,上面公式中的(XTX)-1是计算一个(n*n)矩阵的逆,时间复杂度是O(n3),所以当n非常大时,效率会非常低。Andrew ng老师说到,当n多大时使用gradient descent多大时使用normal equation,没有一个明确的分界线。当n较小时一般使用normal equation比较快捷方便,一般当n达到1000,000时,应该开始考虑gradient descent;
(4)我觉得还有一点也是比较突出的差别吧,gradient descent需要进行Feature scaling处理,而normal equation不用。














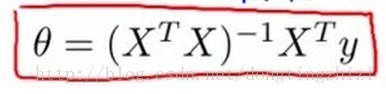

















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









