







- 一直到我刚上大学第一次在黑白控制台里打印出了“Hello World”之前,我都当电脑是一个游戏机,还天真的以为世界上只有windows一个操作系统。
- 当时也是第一次接触了ASCII编码,才知道计算机里的二进制,要转换成人类可理解的内容,还得需要一种人为的规定
- 即对于每个二进制的数字,电脑就按照我们赋予的一对一的规则,在屏幕上显示相应的字符。
- 本文内容七七八八来自课本网络各个角落,,,,,,
ASCII
- 美国信息交换标准编码(American Standard Code Information Interchange)。一开始我竟然愚蠢的认为ASCII后面的II是罗马数字2的意思一直到我看到了英语,,,,,,简直要笑死我自己了哈哈哈
- 查ASCII资料的时候竟是追回到了电报时代,毕竟ASCII算是首个可以流传到今天的编码,而且其诞生于IBM公司忙于研制革命性的OS/360的时代,也恰恰算是计算机差不多真正开始奔跑的时代
莫尔斯电码
- 1837年。美国画家塞缪尔·莫尔斯发明了莫尔斯电码,
- 并于1844年在美国国会的财政支持下,开设了从马里兰州的巴尔地摩到美国首都华盛顿的第一条使用“莫尔斯码”通信的电报线路,是人类数字通信历史上的一个重要的里程碑。
- 莫尔斯码是变长编码,在通信中也加大了接收方阶码的难度,需要操作人员具有很高的技巧和熟练程度。
- 贴一张来自百度的图

博多电传码
- 1874年。法国人埃米尔·博多(Emile Baudot)发明了划时代的博多电传码
- 采用等长编码,这为机器自动编码奠定了基础
- 当时的电传使用多路复用技术,即多跟电线来完成一次通信
- 编码器采用类似钢琴键的五个按键
- 原本2^5=32意味着五位的编码最多可表示32个字符,而27个字母加上十个数字以及数个标点早已超出了32。博多的解决方法是采用了两套32个字符的字符集。第一套主要是字母表,以及一个切换到第二套的符号。第二套主要是十个数字和标点,以及一个切换到第一套的符号。这样除去两个状态转换的符号外,一共可表示的字符就扩大到了62个。
默里码
- 然而博多码确立了五位编码的基础,还没来得及商业化,就被更容易操作的默里码取代
- 1899年,美国农场主唐纳德·默里(Donald Murray)发明了类似标准打字机的电报输入设备,也就是说当想输入一个字母’a’的时候,不必再输入’a’的编码,而只需要按下键盘上的’a’即可。
- 采用的编码方案的基础是博多码,在博多码的基础上根据字符出现的频率改进了编码的方案,因为当时的输出是穿孔纸带,改进后的编码使得高频率的字符可以尽量少的打孔,如字母T仅需要1个孔来表示,而Q则需要4个孔。
ITA-2
- 30年后的1930年代,默里码被CCITT(国际电报电话咨询委员会,国际电信联盟(ITU)的前身)所接纳,并标准化为the International Telegraph Alphabet No. 2(ITA-2),直到1963年

ASCII
- 1963年6月17日,美国标准协会(ASA)的X.34小组成员公布了划时代的美国信息交换标准码ASCII
- 采用7位编码,在ITA-5的基础上发展而来。
- 1963年的版本有过大的缺陷和不完善,比如没有小写字母、某些图形符号混乱,左箭头与下划线混淆,上箭头与’^’符号的定义等问题,这个版本很快被1967年的新ASCII标准所取代
- 细讲起来,1967年才算最终的定案。
- 最初为美国国家标准,后来被国际标准化组织(International Organization for Standardization, ISO)定为国际标准,称为ISO 646标准。
- 由于字节是计算机信息存储与处理的基本单位,而一个ASCII码为7位,但仍总是存储在一个字节里,并将最高位恒置为0。后来为了检测错误,就讲最高位设为奇偶校验位。
- 后来随着计算机硬件的可靠性不断提高,其奇偶检验位也越来越没有必要。
- 增加的128个字符主要是带重音符(法文)、带变音符(德文)的拉丁字母以及制表符。
- 1981年,最初的IBM PC推出时,视讯卡的ROM中就烧有一个提供256个字元的字元集,这也成为IBM标准的一个重要组成部分。
- 这就是最初的IBM字元集,在代码页的概念下为 code page 437,也叫「MS-DOS Latin US」
- 「MS-DOS Latin US」直通车:https://msdn.microsoft.com/en-us/library/cc195060.aspx
- 1985年11月发行的Windows 1.0中,Microsoft没有完全放弃四年前IBM PC上的扩展ASCII,但它已退居第二重要位置。因为遵循了ANSI草案和ISO标准,纯Windows字元集被称作「ANSI字元集」。
- ANSI草案和ISO标准最终成为ANSI/ISO 8859-1-1987,即「American National Standard for Information Processing-8-Bit Single-Byte Coded Graphic Character Sets-Part 1: Latin Alphabet No 1」,通常也简写为「Latin 1」。
- 「Latin 1」直通车:https://msdn.microsoft.com/en-us/library/cc195064.aspx
- 也可以称为EASCII字符集。
- 1987年4月发行的MS-DOS 3.3向IBM PC用户引进了 code page 的概念,Windows也使用此概念。有人译为 内码表 , 个人更喜欢 代码页 。感觉code page更像一本书而不是一张表。
- With the release of PC DOS version 3.3 (and the near identical MS-DOS 3.3) IBM introduced the code page numbering system to regular PC users, as the code page numbers (and the phrase “code page”) were used in new commands to allow the character encoding used by all parts of the OS to be set in a systematic way.
- After IBM and Microsoft ceased to cooperate in the 1990s, the two companies have maintained the list of assigned code page numbers independently from each other, resulting in some conflicting assignments. At least one third-party vendor (Oracle) also has its own different list of numeric assignments. IBM’s current assignments are listed in their CCSID repository, while Microsoft’s assignments are documented within the MSDN. Additionally, a list of the names and approximate IANA (Internet Assigned Numbers Authority) abbreviations for the installed code pages on any given Windows machine can be found in the Registry on that machine (this information is used by Microsoft programs such as Internet Explorer).
- 好吧上面两段来自维基百科。翻译起来实在累,就不打算翻译了。而且个人觉得英文读起来确实蛮有味道,在PC上读的话可以用一些划词翻译的软件来辅助,个人推荐灵格斯。
- 大意就是这个code page的概念被多家公司用,本来用来统一字符编码,结果每家公司都不一样,,,,,,这就十分尴尬了
- 给你们网址自己读一读吧,闲暇之余挺值得消磨时间的 : https://en.wikipedia.org/wiki/Code_page
- 关于code page在查询资料的时候也发现了一些好玩的网站
- http://www.ascii-codes.com/ 一个专门为ASCII建立的网站,十分有趣
- http://www.ibm.com/support/knowledgecenter/ IBM的产品文档,只是我现在还没到达可以直接阅读文档的层次,,,,,,不过还是可以勉强看一下MSDN,对于IBM就不太熟悉了。
- 一点小规律
- 同一个英文字符的大小写的编码差异仅在第六位上,如 ‘A’ 为“01000001”,’a’ 为“01100001”。这样在大小写转换的时候只需要把第六位翻转。
- 对于数字 ‘0’ 到 ‘9’,其ASCII的值依次为“00110000”到“00111001”,前四位均为“0011”,后四位的值也就是 0 到 9,这样在进行转换的时候只需要把ASCII的编码的高四位清0即可。
- ASCII是一个非常可靠的标准。在键盘、视讯显示卡、系统硬体、印表机、字体文件、操作系统和Internet上,其他标准都不如ASCII码流行而且根深蒂固。
十进制数的编码
- 计算机用二进制可以得到很大的好处,而人类已经习惯了用十进制了。所以对于十进制与二进制之间的关系就有特殊的处理方式
字符串形式
- 即每一个十进制的数字被当作一个字符,用一个二进制的编码来表示。如ASCII中“00110000”到“00111001“就用来表示字符 ‘0’ 到 ‘9’。
- 然而这种表示虽然可以实现但实际上却抹杀了数字本身,因为数字纯粹是被当作字符来处理的
- 尽管在ASCII中可以以高四位清零的方式来快速获得数字本身的值,但这又浪费了4位的空间
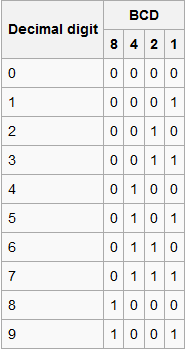
BCD码
- Binary Coded Decimal
- 仅用4位二进制就可以表示1个十进制的数字,这样一个字节就可以表示2位十进制数字
- 主要用途是在十进制和二进制的转换过程中作为中间码。
- 这种编码的方式可以带来很高的精度,因为每一个数字都会被保存下来。
- 这种编码技巧最常用于会计系统的设计里,因为会计制度经常需要对很长的数字串作准确的计算。相对于一般的浮点式记数法,采用BCD码,既可保存数值的精确度,又可免去使电脑作浮点运算时所耗费的时间。
- 分类的话
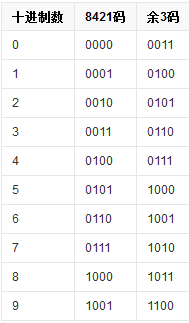
- NBCD(Natural Binary Coded Decimal),也叫8421码。就是对于4 bit,从0000到1001分别来表示数字0到9,其余的用不到。
- “8421”也可以看做是对4 bit的一个权值的赋值,最高位权值为8,最低位权值为1,这也和二进制的内在原理相吻合。
- 其余的按权值不同来分的话,也有诸如2421码、5421、4221、7421码等
- 感觉只需要知道如果是权值的方案,那么权值的设计有很多种就是了。
- 至于每种有什么用处,大概就需要了解发明的时候的特定的环境了吧。
- 而且不同的权值设计,也带来了不同的特性。比如2421码的10个数码中,每个数 n 所对应的二进制编码取反后得到的编码对应的数 m,则有 n + m = 9。称这种特性为“对9的自补”。
- 余3码:8421码每个加3得到。
- 由于余3码在8421的基础上加3之后,把8421没有编制的六个编码平均到了两端,这使得余3码具备了“对9的自补”特性。
- NBCD(Natural Binary Coded Decimal),也叫8421码。就是对于4 bit,从0000到1001分别来表示数字0到9,其余的用不到。
- Gray码,二进制格雷码(Binary Gray Code)简称格雷码,1953年公开的弗兰克·格雷(Frank Gray,18870913-19690523)专利“Pulse Code Communication”而得名。
- 下图是Gray’s patent introduces the term “reflected binary code”,【From Wikipedia】
- 特点是相邻数字之间的二进制编码只有一位不同。
- 当时是为了通讯,即在数/模转换器将二进制转换成模拟信号的时候,如果改变了的数字的二进制编码有多位不同的话,就会产生很大的尖峰电流脉冲,比如8421下3的“0011”到4的“0100”就有3位要改变。而Gray码的特点保证了相邻数位之间的差距只有1位,这使得Gray变得更为可靠。
- 维基通道:https://en.wikipedia.org/wiki/Gray_code
- “BCD码”维基通道

EBCDIC
- Extended Binary Coded Decimal Interchange Code
- 在IBM System/360问世之前,IBM曾采用一种6位的BCD码的变种来表示字符和数字
- 后来System/360的设计师决定将6位的BCD码扩展为8位的BCD码来表示更多的字符,就设计了新的编码方案,称为“扩展的BCD交换码”,即EBCDIC
- EBCDIC was devised in 1963 and 1964 by IBM and was announced with the release of the IBM System/360 line of mainframe computers.
- 维基通道:https://en.wikipedia.org/wiki/EBCDIC
- 8位的EBCDIC的高四位为“区(Zone)”,低四位为“数(Digit)”。
- 通过检查区位值,可以直接判断字符是否属于某个字符范围
- 英文字母的大小写转换也同样只需要翻转一位即从高位数的第2位。
Unicode
- 从ASCII中A所代表的American来看就知道,ASCII只是美国为自己国家打造的字符集
- 而每个国家的语言不同,所需要的字符也不同
- 其次在不同的平台上,字符集的实现也有各自的标准
- 以上问题如果不处理好,将使得计算机之间的信息交换变得麻烦
- 你即必须要知道对方是用的那种字符集,你才能理解对方发的一串串二进制代码究竟是什么意思。
- 而一旦放宽了限制,我相信字符集将出现N多种,以至于无法管理。
- 另外如果你想像我现在一样写一篇中英文混杂的文章,那么传统的字符编码要么只能编码英文要么只能编码中文,对于多语言混杂就无能为力了
- Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
字符集与字符编码方式
- 字符集:对每个我想编码的字符,我分配给它一个唯一的数值,用来建立数值和字符之间的一一对应的关系。
- ASCII可以认为是一个字符集,它把128个字符一一对应到了0-127个数值,只不过ASCII只分配了128个字符而已,对于美国可以用,对于其他国家就不见得了。
- Unicode**为每个语言每个字符都分配了一个唯一的数值**,这样就可以兼容多语言、多平台
- 字符编码方式:对于每个字符所对应的唯一的数值,我采用某种方式来组织成二进制的形式,并保证各个字符之间的编码是可区分的,以此来在计算机内进行存储、处理、传输等等操作。
- 就ASCII,对于每个字符所对应的数值来说,我只需要把这个数值转换成二进制,就可以存储在计算机里了,而且每个字符完全可以用一个字节存储下来
- 对于Unicode来说,由于Unicode为太多太多的字符分配了唯一的数值,这也导致了数值非常大
- 首先把数值直接转换成二进制是可以的,只不过这时候一个字符所需要的空间就不止是一字节了,而是两字节甚至四字节
- 显然直接把数值转换成二进制的这种编码方法不太适合英语,我原本存一个字母用一个字节就好了,现在却要用两个字节,这样就比原来多一倍的空间。不行不行太浪费了。所以对于Unicode来说,如何把数值转换到二进制编码来进行存储,就有一种专门的转换方案
- Unicode Translation Format(UTF)。UTF的设计初衷主要是想节省空间,节省的空间又主要是想解决传输数据时数据量过大的问题。比如一篇英文文章用Unicode的直接编码会比ASCII多占一倍,传输的时候也需要传输多一倍的数据量。
Unicode与ISO 10646(UCS)
- 历史上, 有两个独立的, 创立单一字符集的尝试. 一个是国际标准化组织(ISO) 的 ISO 10646 项目, 另一个是由(一开始大多是美国的)多语言软件制造商组成的协会组织的 Unicode 项目
- 幸运的是, 1991年前后, 两个项目的参与者都认识到, 世界不需要两个不同的单一字符集. 它们合并双方的工作成果, 并为创立一个单一编码表而协同工作. 两个项目仍都存在并独立地公布各自的标准, 但 Unicode 协会和 ISO/IEC JTC1/SC2 都同意保持 Unicode 和 ISO 10646 标准的码表兼容, 并紧密地共同调整任何未来的扩展.
- 这二者的产物一个事ISO10646也叫UCS,一个就是Unicode,只不过二者互相兼容,也就是说对于同一个字符,二者均分配了同样的数值来对应。
- 目前Unicode对应于UCS-2,即分配的数值大小都在2^16=65536之内,使得每个数值都可以直接用2字节的二进制编码来保存
- 这种使用16位编码空间的Unicode字符构成了基本多语言平面(Basic Multilingual Plane,简称BMP)
- 这里提到了Unicode的语言平面的概念,一个平面对应了16位二进制可表示的范围
- 0000~1FFF之间的8192个码点用于表示拉丁文、阿拉伯文、希伯来文、古埃及文、古斯拉夫文、希腊文、非洲文、东南亚等地区的文字,这部分又称字母表,大概是都属于字母体系
- 2000~2FFF之间的4096个码点用于表示货币符号和各种数学符号,又称为符号表
- 3000~3FFF之间的4096个码点用于表示汉文、日文、韩文的拼音字母及其标点符号
- 4000~DFFF之间的40960个码点用于统一汉文、日文、韩文和印度文字符的表示
- E000~EFFF之间的4096个码点用于扩展编码
- F000~FFFF之间的4096个码点用于保留编码
- 这种使用16位编码空间的Unicode字符构成了基本多语言平面(Basic Multilingual Plane,简称BMP)
- 最新的Unicode又定义了16个辅助平面,来表示更多的字符,这也与UCS-4保持一致,理论上可以表示2^31=2 147 483 648个字符。每个字符也就需要4个字节的二进制编码来保存
- 目前Unicode对应于UCS-2,即分配的数值大小都在2^16=65536之内,使得每个数值都可以直接用2字节的二进制编码来保存
- 虽然分配的数值相同,但是考虑到每个字符占用的空间过大,二者又有自己的编码方式。
- Unicode就有UTF-8、UTF-16等等编码方式
- UCS有UCS-2、UCS-4的编码格式
- 对于一些细节方面的内容,可以参考二者的维基百科
Unicode与UTF
- Unicode中每个字符分配的唯一数值称为“码点”
- 每个“码点”(数值)又将以特定的方式编制成二进制代码
- UTF-8 编码
- 变长编码。既然英文字母嫌2字节太长,那我还用1个字节来表示你呗。至于其余的编码,我有特殊的手段
- 对于127以内的字符,直接用单字节来表示,且最高位为0。
- 对于0080~07FF以内的字符,采用双字节编码。高字节的前三位为110,低字节的前两位为10,其余的16-5=11位刚好用来存放16位二进制数值的低11位。
- 对于0800~FFFF的字符,用三字节的方式来编码。高字节前四位为1110,中字节和低字节的前两位为10,其余的24-8=16位刚好用来存放16二进制数值。
- 看表~~
- 解码的时候
- 如果一个字节的最高位为0,则下一个字符是用一个字节编码的
- 如果前三位为110,则下一个字符是用二字节编码的
- 如果前四位为1110,则下一个字符是用三字节编码的
- 10用来表示当前字节是某个字符编码的后续字节
- UTF-16编码使用2个字节对一个字符编码,对于UCS-2中的字符(65536之内)可以直接进行编码,对于UCS-4的字符可以采用变长编码的方式来支持

其他资源
- Unicode官网:http://www.unicode.org/
- 几篇我认为还不错的文章
- 这篇涉及到了编程时要考虑的char等问题,慢慢啃完还是有些收获的 https://www.douban.com/note/18722189/
- 这篇颇为有趣,开篇涉及到了中文编码 : http://my.oschina.net/liting/blog/470021?p=1
- 这篇主要讲了Unicode与UCS的区别 http://www.cnblogs.com/zhcncn/articles/3035561.html
中文编码
- 对于汉字来说,编码要比英文复杂得多:一个汉字就是一个字符。汉字简直太多了,,,,,,光字典里我记得好像就6万多,,,,,,
- 而且在一篇中文文章里常常会包含英文符号,更不用说各种各样的数学符号、标点符号等等,,,,,,
- 目前,用于存储的汉字编码和用于输入的汉字编码是不同的
- 而且计算机对汉字的处理是由软件来实现,CUP只提供对英文的直接处理。
- 如果看过上面提到的一篇涉及到中文编码的博客,那么对GB2312、GBK、GB18030应该有比较熟悉的认识了
汉字输入码
- 计算机的键盘是为输入英文而设计的,要想输入中文就必须建立中文汉字与键盘按键的对应规则。
- 这个规则就被称为汉字输入编码
- 常见的有:
- 五笔字型码
- 微软拼音码
- 国际区位码
GB2312
- 1980年颁布的GB2312规定了3755个最常用汉字和3008个较常用汉字的编码。
- 6763个汉字被分成若干个区,每个区包含94个汉字
- 一个汉字用两个字节表示
- 首字节指明所在区
- 尾字节指明区内位置
- GB2312是兼容ASCII的,还记得ASCII的最高位恒为0吗,这也就使得两个字节表示的汉字可以通过最高位为1来与一个字节表示的ASCII字符区别开来
- 在windows中的代码页为CP936
GBK
- GBK 是 GB2312的扩展 ,除了兼容GB2312外,它还能显示繁体中文,还有日文的假名
- GBK国标扩展。GB2312国标。
- 扩充方法是,原先GB2312要求两个字节的最高位都为1,现在允许后一个字节的最高位为1,反正有前一个字节就知道这两个字节都是为一个中文字符服务的
- GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
GB18030
- 简单的来说就是对GBK的进一步扩充
- GB18030-2000版本在GBK基础上增加了CJK统一汉字扩充A的汉字
- GB18030-2005在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。
- GB18030在windows中的代码页为CP54936
- CJK:CJK Unified Ideographs
- 中日韩统一表意文字
- 与ISO 10646(UCS)及Unicode标准内赋予相同编码,即其中的从0x4E00到 0x9FA5 的连续区域包含了 20902 个来自中国(包括台湾)、日本、韩国的汉字,称为 CJK (Chinese Japanese Korean) 汉字。
- CJK 是GB2312-80等字符集的超集。
- 算是东拼西凑总算是写完了,,,,,,期间对字符编码也有了更深入的理解,,,,,,顺便保存了好多文章到印象笔记中,只供闲暇时阅读打发时间了。
- 不过还有其他打发时间的方法/净是娱乐罢了














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









