






运行作业的方式通常有两种,一种是通过Job的submit()方法来提交任务,另一种是通过waitForCompletion()(如果作业没有提交就提交作业,然后一直等待作业执行完成)。
mapred.job.tracker决定了执行的方法:如果这个配置属性被设为local,那么就使用本地作业运行器,这个运行器使作业运行在单个jvm上,设计它的目的是在小数据集上运行、测试MapReduce项目;如果这个配置被设为host:port形式,这个属性值就被解释为jobTracker地址,运行器就把作业提交到这个地址的jobtracker。
在hadoop2.0有一个新的mapreduce框架被引入了,只要通过设置mapreduce.framework.name属性值,相应的框架就可以执行了,属性值有三种local(用于本地作业运行器),classic(用于老的mapreduce框架),yarn(新框架)。
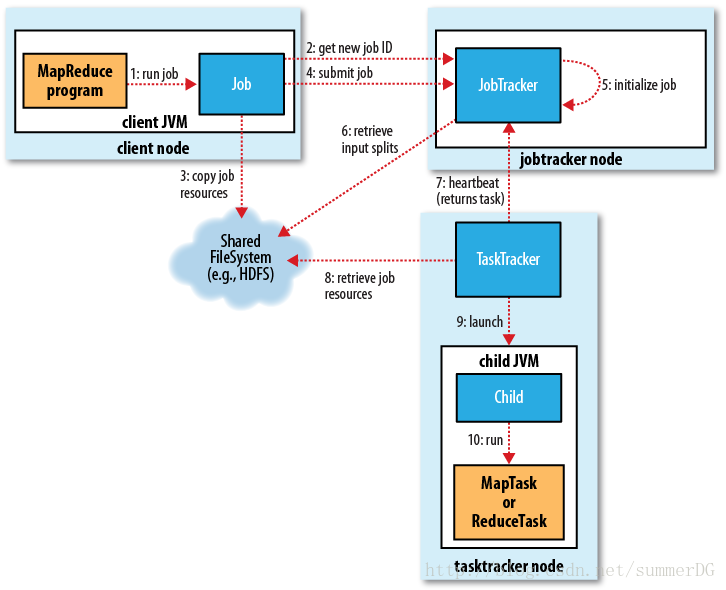
经典框架:
客户端:用于提交作业
jobtracker:协调作业的运行,jobtracker是一个java应用程序,主类是JobTracker
tasktracker:运行作业被划分后的任务,tasktracker是一个java应用程序,主类是TaskTracker
分布是文件系统(HDFS),用于在其他实体间共享作业文件。
作业提交:
看一下Job的summit()方法,我们就知道其过程了
public void submit() throws IOException, InterruptedException,
ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
// Connect to the JobTracker and submit the job
connect();
info = jobClient.submitJobInternal(conf);
super.setJobID(info.getID());
state = JobState.RUNNING;
}创建一个JobClient(第三版中是JobSummitter,但我用的是1.2.1版本,又改回到了JobClient)实例来调用submitJobInternal,这个方法才真正要开始做正事了,我们一会再具体讲这个函数。
waitForCompletion()则是轮询作业进度(每个一秒查询一次),如果和上次报告的进度不同就向控制台报告进度,作业成功完成,就显示作业计数器,否则就把引起作业失败的错误打印到控制台
1282 public boolean waitForCompletion(boolean verbose
1283 ) throws IOException, InterruptedException,
1284 ClassNotFoundException {
1285 if (state == JobState.DEFINE) {
1286 submit(); //这里提交任务
1287 }
1288 if (verbose) {
1289 monitorAndPrintJob();
1290 } else {
1291 // get the completion poll interval from the client.
1292 int completionPollIntervalMillis =
1293 Job.getCompletionPollInterval(cluster.getConf());
1294 while (!isComplete()) {//轮询是否完成
1295 try {
1296 Thread.sleep(completionPollIntervalMillis);
1297 } catch (InterruptedException ie) {
1298 }
1299 }
1300 }
1301 return isSuccessful();
1302 }
作业提交进程是由submitJobInternal完成的:
public
RunningJob submitJobInternal(final JobConf job
) throws FileNotFoundException,
ClassNotFoundException,
InterruptedException,
IOException {
/*
* configure the command line options correctly on the submitting dfs
*/
...
JobID jobId = jobSubmitClient.getNewJobId();
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
jobCopy.set("mapreduce.job.dir", submitJobDir.toString());
...
// Check the output specification
if (reduces == 0 ? jobCopy.getUseNewMapper() :
jobCopy.getUseNewReducer()) {
org.apache.hadoop.mapreduce.OutputFormat<?,?> output =
ReflectionUtils.newInstance(context.getOutputFormatClass(),
jobCopy);
output.checkOutputSpecs(context);
} else {
jobCopy.getOutputFormat().checkOutputSpecs(fs, jobCopy);
}
jobCopy = (JobConf)context.getConfiguration();
// Create the splits for the job
FileSystem fs = submitJobDir.getFileSystem(jobCopy);
int maps = writeSplits(context, submitJobDir);
jobCopy.setNumMapTasks(maps);
...
// Write job file to JobTracker's fs
FSDataOutputStream out =
FileSystem.create(fs, submitJobFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));
...
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, jobCopy.getCredentials());
status = jobSubmitClient.submitJob(
jobId, submitJobDir.toString(), jobCopy.getCredentials());
...
}源码比想象中的长,那我们只看一下重点
JobID jobId = jobSubmitClient.getNewJobId();进去第一件事就是获取jobId,用到了jobSubmitClient对象,jobSubmitClient对应的类是JobSubmissionProtocol的实现之一(目前有两个实现,JobTracker和LocalJobRunner),由此可判断出jobSubmitClient对应的类要么是JobTracker,要么是LocalJobRunner。那作业是提交到JobTracker去,还是在本地执行?可能就是看这个jobSunmitClient初始化时得到的是哪个类的实例了,我们可以稍稍的先往后看看,你会发现submitJobInternal最后用了
status = jobSubmitClient.submitJob(
jobId, submitJobDir.toString(), jobCopy.getCredentials())
来提交作业,再稍稍看看JobTracker和LocalJobRunner的submitJob实现,看来确实是这么回事。好,那我们就先跳回去看看这个jobSubmitClient是如何初始化的。在JobClient的init中我们可以发现jobSubmitClient的初始化语句:
public void init(JobConf conf) throws IOException {
String tracker = conf.get("mapred.job.tracker", "local");
tasklogtimeout = conf.getInt(
TASKLOG_PULL_TIMEOUT_KEY, DEFAULT_TASKLOG_TIMEOUT);
this.ugi = UserGroupInformation.getCurrentUser();
if ("local".equals(tracker)) {
conf.setNumMapTasks(1);
this.jobSubmitClient = new LocalJobRunner(conf);
} else {
this.rpcJobSubmitClient =
createRPCProxy(JobTracker.getAddress(conf), conf);
this.jobSubmitClient = createProxy(this.rpcJobSubmitClient, conf);
}
}原来是跟conf中的mapred.job.tracker属性有关,如果你没设置,那默认得到的值就是local,jobSubmitClient也就会被赋予LocalJobRunner的实例。平时,我们开发时一般都只是引用lib里面的库,不引用conf文件夹里的配置文件,这里就能解释为什么我们直接Run as Java Application时,作业被提交到Local去运行了,而不是Hadoop Cluster中。
由于现在的水平有限,作业提交的内容暂时只深入到这里,可以看一下这篇博文,介绍的很详细,但不同的版本实现的api不会完全相同。
2、检查作业的输出说明。例如:没有指定输出目录或者输出目录已经存在就不提交,把错误抛回给mapreduce程序。
3、计算作业的输入分片
4、将运行作业所需的资源(包括作业jar文件,配置文件和计算所得的输出分片)复制到jobtracker的文件系统中,这个文件系统是在一个以作业id命名的目录下变,也就是我们先前代码
Path submitJobDir = new Path(jobStagingArea, jobId.toString());创建的目录路径
这段代码就很好的展现了这一过程:
// Write job file to JobTracker's fs
FSDataOutputStream out =
FileSystem.create(fs, submitJobFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));5、最后就是通过调用Jobtracker的submitJob()方法来告知jobtracker作业准备执行。
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, jobCopy.getCredentials());
status = jobSubmitClient.submitJob(
jobId, submitJobDir.toString(), jobCopy.getCredentials());作业初始化(译):
Jobtracker接收到一个对submitJob()的响应后,它会把作业放入一个内部队列,作业调度器会对它进行调度并初始化。初始化包括创建一个对象来表示正在运行的作业,这个对象会封装任务、记录信息,从而跟踪任务的状态和进度。
想要创建运行的任务列表,作业调度器首先要从共享文件系统检索由客户端计算的输入分片,然后为每个分片创建一个map任务。要创建的reduce任务的数量由mapred.reduce.tasks属性值决定,并通过setNumReduceTasks方法来设定(该方法是通过属性值设定的),调度器创建相应个数的reduce任务运行,任务此时被赋予一个id。
除了map和reduce任务,还有两个任务被创建了:一个作业建立任务,一个作业清理任务。这两个任务由tasktracker运行,并且 在map任务运行前建立作业,在reduce任务执行完后清理作业。我们还为作业配置了一个OutputCommitter来决定要运行的代码,默认情况下是 FileOutputCommitter。对于作业建立任务,它将会为作业创建一个输出目录,并给任务输出创建一个临时工作空间,对于作业清理任务,它会把临时工作空间删除掉。
任务分配(译):
Tasktrackers会运行一个简单的循环来周期性地给jobtracker发送一个“heartbeat”方法响应。“heartbeat”告诉tasktracker现在还在运行(还活着),而且“heartbeat”同时还是tasktracker和jobtracker的信息通道。作为“heartbeat”的一部分,tasktracker将会指明它是否已经准备运行新任务,如果是,jobtracker会分配一个任务给tasktracker,jobrtacker通过“heartbeat”的返回值与tasktracker通信。
在jobtracker为tasktracker选择任务前,jobtracker必须选择一个作业,从而从这个作业中选择任务。调度算法很复杂,默认方法是简单地维护一个作业优先级列表。选择好一个作业后,就可以选择作业了。
Tasktracker有固定数量的任务槽以供map和reduce任务使用,这些任务槽是独立设置的。例如:一个tasktracker也许会被配置成同时运行两个map任务和两个reduce任务(精确的数字依赖于tasktracker的核的数目和内存大小)。在一个给定的任务范围内,默认的调度器会在填满reduce任务槽之前先填满map任务槽。所以如果tasktracker拥有空map任务槽,那么jobtracker将会先选择一个map任务;否则才会选择一个reduce任务。
要选择一个reduce任务,jobtracker仅需要从待运行的reduce任务列表中选择下一个就好,因为不需要考虑本地化数据。对于一个map任务,jobtracker会考虑tasktracker的网络位置,并选取一个离tasktracker尽可能近的任务。最佳情况就是,该任务是本地化数据的,也就是说对应分片正好也在这个节点上。或者,任务可能是本地机架上的:对应分片在同一个机架上,而不是同个节点上。还有一些任务即使不是本地化数据的也不是本地机架的,那么只能从不同的机架上检索他们的数据了。
执行任务(译):
现在tasktracker已经被分配了一个任务了,下一步就是运行这个任务。首先,tasktracker会从共享文件系统中复制作业包到本tasktracker文件系统。它还会从分布式缓存中复制应用需要的文件到本地硬盘。然后,它会为该任务建立一个工作目录,减压jar包的内容到该目录。最后,它会建立一个TaskRunner实例来运行该任务。
TaskRunner会建立一个新的JVM来运行每个任务,从而使用户定义的map和reduce方法产生的bug不会影响tasktracker(例如,导致tasktracker崩溃或挂起)。但是,可以在任务之间重利用JVM。
子进程会通过umbilical接口与父进程进行通信。这样可以通知父进程任务的进度(每隔1秒,直到任务完成)。
每个任务都有建立和清除行为,这些行为会运行在和任务同样的JVM上,而且这些行为由作业的OutputCommitter决定。清理行为用来提交任务,在基于文件的作业的情况下,意味着其输出将会被写入到与任务对应的位置。这个提交协议确保了在推测执行的时候,重复任务(推测执行的概念)只有一个会被提交,其余的都中止。
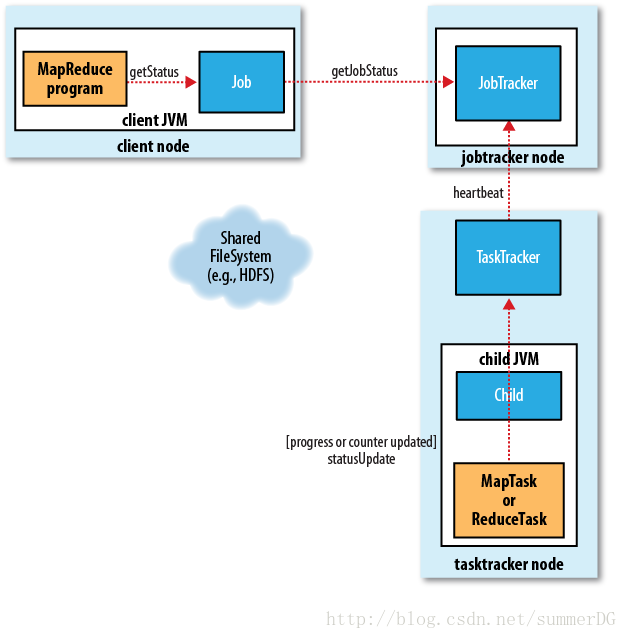
进度与状态更新(译)
当一个任务正在运行,它可以跟踪其进度,也就是任务的完成比例。对于map任务,这是已处理输入数据的比例。对于reduce任务,它是一个更复杂一点,但系统仍然可以估算reduce输入被处理的比例。为此,它把总进度分为三部分,对应到shuffle的三个阶段。例如,如果任务已经执行了reducer一半的输入,那么任务进度就是5/6.因为已经完成了复制与排序阶段(各占1/3),并且已近完成了reduce阶段的一半(1/6)。
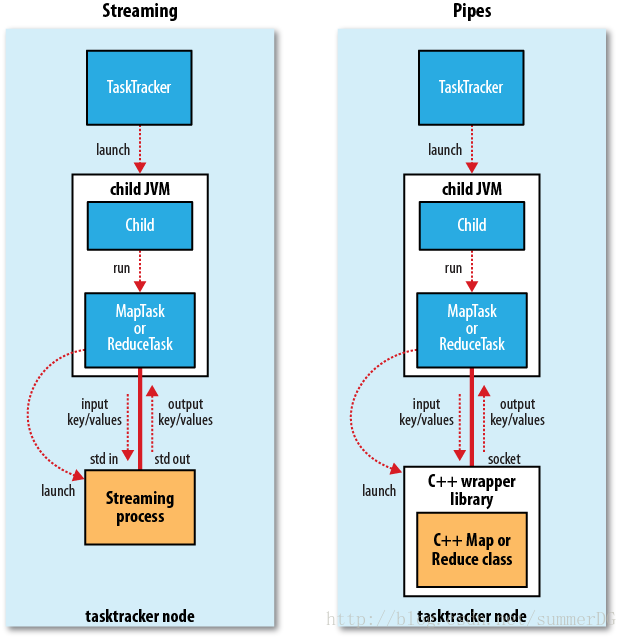
Streaming和Pipes(译)
Streaming和Pipes都是运行特殊的map和reduce任务来运行用户提供的可执行程序,并与其进行通信。
Streaming任务会利用标准输入输出流与进程通信。另一方面,Pipes任务监听socket并发送该环境的一个端口号给c++进程,这样在开始时,c++进程就建立了一个与父java Pipes任务的持久化socket链接。
两种情况下,java进程都会在任务执行时把输入键值对发送给外部进程,由外部进程运行用户定义的map和reduce方法,然后把输出键值对传回给java进程。从tasktracker来看,这好像是在子进程中运行了map和reduce代码。
作业完成(译):
Jobtracker收到最后一个任务(这是一个特殊的作业清理任务)的完成通知后,辨别作业状态改为“成功”。然后当作业查询状态的时候,就会知道作业已完成,然后打印信息通知用户,返回waitForCompletion()。作业统计与计数值会打印到控制台。
Jobtracker还会发送一个http作业通知(如果配置了的话)。可以通过job.end.notifucation.url属性来配置。
最后,jobtracker清理掉他的工作状态,叫tasktracker也做一样的工作(如清空中间输出)。
YARN框架:
YARN框架主要是将jobtracker的工作分为单独的实体,从而弥补经典框架的扩展性短板。jobtracker主要负责作业调度和任务进度监视。
YARN将这两个责任分配给两个独立的守护进程:一个是资源管理器(resource manager),用于管理进群上资源的使用,另一个是应用管理器(application master),用于管理集群上应用的生命周期。设计思想就是,application master与resource manager协商集群资源的分配(资源是由一组container来描述的,每一个container都有一定的内存),然后在这些container上运行特定的应用进程,这些container被node manager监视,以确保该应用不会使用额外的资源。 NodeManager 是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报。
和jobtracker相比,应用的每一个实例都有一个分配的application master,它运行在应用程序的持续时间内。application master用来调节map和reduce任务的运行。
事实上,mapreduce仅仅是YARN应用的一种类型,这里还有其他YARN应用,如分布式shell,它可以在在集群的一组node上运行一个脚本。YARN设计的亮点在于不同的YARN应用共存于同样的集群上。
此外,用户甚至可以在相同的YARN集群上运行不同版本的MapReduce,这样可以让更新的MapReduce更便于管理。
YARN上的实例:
客户端:提交MapReduce作业
YARN资源管理器(resource manager),调度进群上的计算资源的分配。
YARN节点管理器(node manager),启动并监视进群上机器的计算容器(container)。
MapReduce应用管理器(application master),调度MapReduce作业上运行的任务,application master和MapReduce任务都运行在容器中(由resource manager计划
,并由node manager管理)。
分布式文件系统。
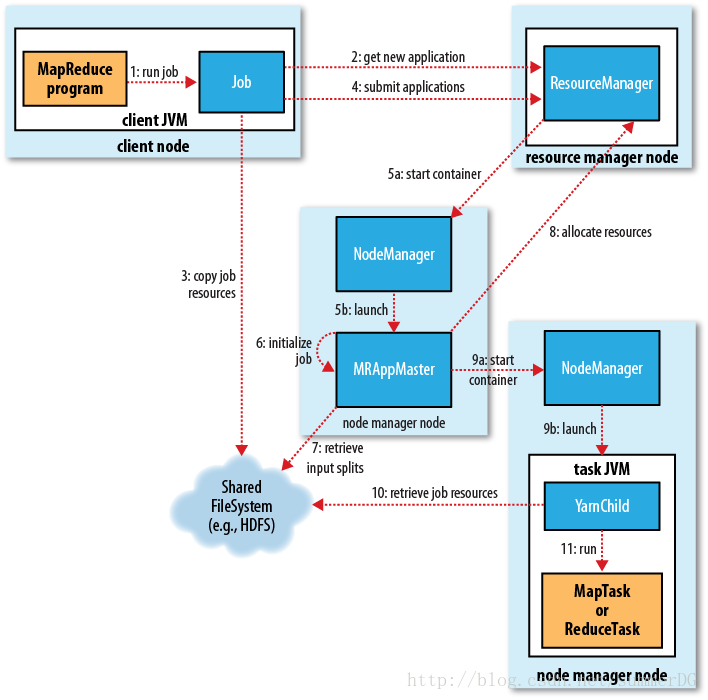
作业提交(译):
在YARN中,作业提交和MapRduce1中所用的api相同。YARN中有个ClientProtocol接口,这个接口在mapreduce.framework.name设置为yarn的时候被激活。提交过程和经典的实现方案很像。新的jobID是由resource manager检索出来的,而不是jobtracker,只是以YARN的命名方式,它是一个应用ID。客户端检查作业的输出规范,计算输入分片(虽然还可以在集群上计算分片,yarn.app.mapreduce.am.compute-splits-in-cluster设置),复制作业资源(包括作业包,配置和分片信息)到HDFS。最后,作业通过调用submitApplication被提交到resource manager。
作业初始化(译):
当resource manager接收到作业的submitApplication()的呼叫,它就会把这个请求传给调度器。调度器分配一个container和resource manager,然后在node manager的管理下启动application master进程。
MapReduce作业的application master是一个java应用程序,它的主类是MRAppMaster。他会通过创建很多记录对象(bookkeeping object)跟踪作业进度的方式来初始化作业,同时它会接收作业的进度和完成情况报告。接下来,application master会从共享文件系统检索由客户端上计算的输入分片。然后Application master会为每个分片创建一个map任务对象,和一些reduce任务对象(数量由mapreduce.job.reduces属性决定)。
Application master接下来做的事情是决定如何运行任务(任务构成MapReduce作业)。如果作业很小,那么application master会选择在同一个JVM(application master所在JVM)上运行这个任务。与在单个节点上顺序运行这些任务相比,如果application master判断分配的开销,以及在新container上运行任务的开销超过了并行所能带来的好处,那么才会在同一个JVM上运行这些任务(与MapReduce1不同,MapReduce1中多个小作业是不会在单个tasktracker上运行的)。这种作业被称做,以uber任务运行的作业。
什么才算是小作业呢?默认情况下,小作业就是只有一个reducer,最多10个mapper,输入量小于一个HDFS块的大小的作业。(这些值是可以通过设定mapreduce.job.ubertask.maxmaps、mapreduce.job.ubertask.maxreduces、mapreduce.job.ubertask.maxbytes的值来改变。)还可以没有uber作业(把mapreduce.job.ubertask.enable设定为false)。在任何任务运行前,作业创建方法就被调用创建了作业输出目录。MapReduce1中这个方法是在一个特定的任务(由tasktracker运行的)中调用的,而在YARN中,这个方法是直接由application master调用的。
任务分配(译):
如果作业不能以uber任务运行,那么application master就会从resource manager请求足够数量的container(能满足作业上所有map和reduce任务)。所有的请求都会搭载在“heartbeat”,这些信息包括每个map任务的数据位置,尤其是主机号和输入分片所在的机架。调度器利用这些信息来做调度(类似于jobtracker的调度器)。调度器会尽量把任务放在相应数据所在结点,但是如果不行,调度器就会把任务放在同一机架(和数据不在同一节点)上。
这些请求还会指定任务的内存需求。默认情况下,map和reduce任务会被分配1024MB的内存,但这可以通过mapreduce.map.memory.mb 和 mapreduce.reduce.memory.mb来设定。
这种内存分配不同于MapReduce1,在MapReduce1上,tasktracker有固定数量的任务槽(在集群配置时设定),每个任务都会运行在单独的任务槽里。任务槽有允许的最大内存,对于集群来说,它还是固定的,这样会导致在任务只使用少量内存时(因为等待其他任务不能使用空闲内存)内存的浪费,还会导致作业不能完成而失败的问题,因为没有足够的内存去正确的运行因此无法完成。
YARN中,资源更加细粒度了,所以这两个问题就可以避免了。特别是,应用可以请求最大分配量和最小分配量之间的任意大小的内存,但这必须是最小分配量的整数倍。默认的内存分配是特定调度器完成的,对于容量调度器,默认最小分配量为1024MB(由yarn.scheduler.capacity.maximum-allocation-mb设定)。因此,作业能请求从1到10G任意大小的内存(必须是整数GB,调度器会计算出最接近的整数值),可以通过适当的设定mapreduce.map.memory.mb和mapreduce.reduce.memory.mb来改变最小分配量。
任务执行(译):
一旦任务通过resource manager调度器分配到了一个container,这个application master就会与node manager联系来启动这个container。任务由一个java应用执行,这个应用的主类是YarnChild。在application master运行任务前,它会把任务需要的数据本地化,这些数据包括作业配置和jar文件,还有分布式缓存的相关文件。最后application master会运行map和reduce任务。
在MapReduce1中tasktracker会为任务酝酿新的JVM,出于这个原因,YarnChild运行在一个专用的JVM上来将用户代码与长期运行的系统守护进程隔离开。和MapReduce不同的是,YARN不支持JVM重用,所以每个任务运行在新的JVM上。
Streaming 和 Pipes工作方式和MapReduce1相同。
进度与状态更新(译):
在YARN下运行时,任务会向application master来报告它的进度和状态,application master会有一个对作业的整体了解。与MapReduce1相比,进度更新流从子进程通过tasktracker到达jobtracker聚集。客户端每秒轮询application master(可以通过mapreduce.client.progressmonitor.pollinterval来改变轮询的间隔时间)来接收进度更新,然后显示给用户。
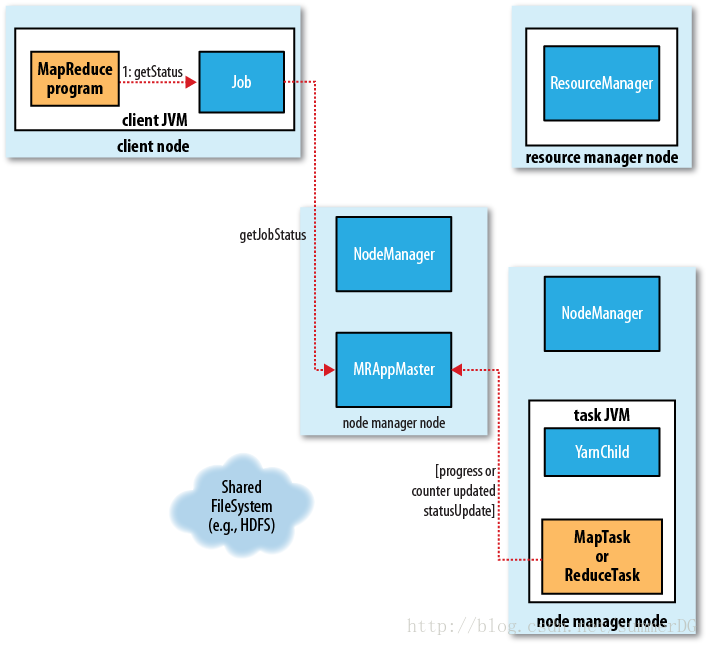
作业完成(译):
每隔5秒客户端会通过waiForCompletion()检查作业是否完成,这个轮间隔可以通过mapreduce.client.completion.pollinterval属性设置。
作业完成通知还支持http回调的方式(像MapReduce1),在MapReduce2中,application master启动回调函数。
作业完成后,application master和任务container会清理掉工作状态,OutputCommitter的作业调用清理方法。作业信息由作业历史服务器打包以供用户查看。
这篇博客我只在MapReduce1的作业提交深入源码讲了一下,至于YARN,由于本人用的是1.2.1版本,所以没有相关代码,其他翻译的内容,如果有问题还请网友指出来。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









