







Chap1 初始hadoop
- MapReduce比较适合以批处理方式处理需要分析整个数据集的问题,尤其是动态分析。
- MapReduce对非结构化或半结构化数据非常有效,因为它是中处理数据时才对数据进行解释。即MapReduce输入的键和值并不是数据固有的属性,而是由分析数据的人来选的。
- MapReduce是一种线性可伸缩编程模型,我们需要写map函数和reduce函数,每个函数定义一个键值对集合到另一个键值对集合的映射。这些函数不必关注数据集机器所用集群的大小,可以原封不动地应用于小规模数据集或者大规模数据集。且随着数据的增长,运行速度呈线性增长。
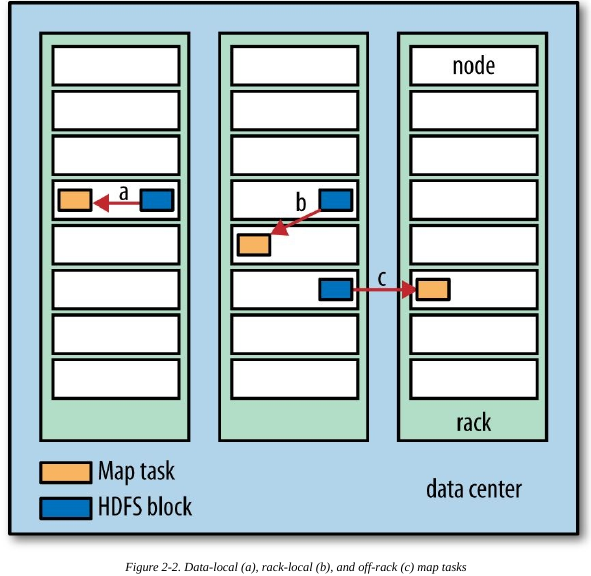
- MapReduce 尽量在计算节点上存储数据,以实现数据的本地快速访问,数据本地化特性是MapReduce的核心特征。
- 有了MapReduce ,程序员不必操心系统部分失效的问题,因为它自己的系统实现能够检测到并重新执行那些失败的map任务或reduce任务。
正因为采用的是无共享框架,MapReduce才能实现失败检测,各个任务之间彼此独立,因此任务的执行顺序无关紧要。
Chap 2 关于MapReduce
Data Flow ##
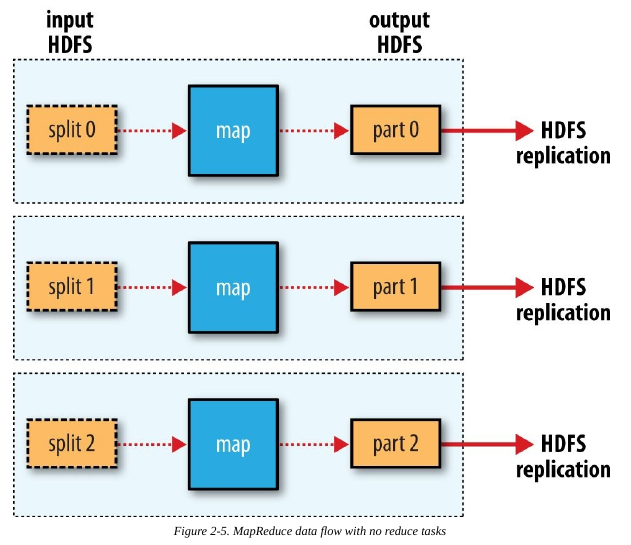
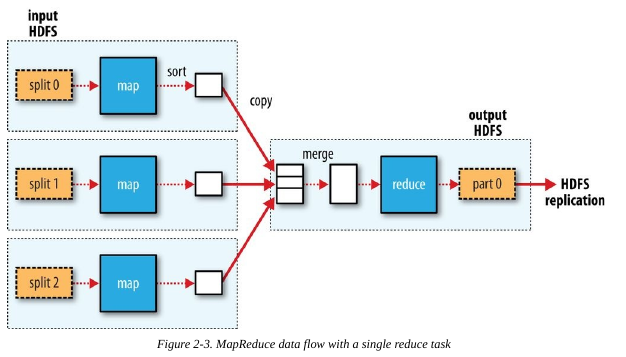
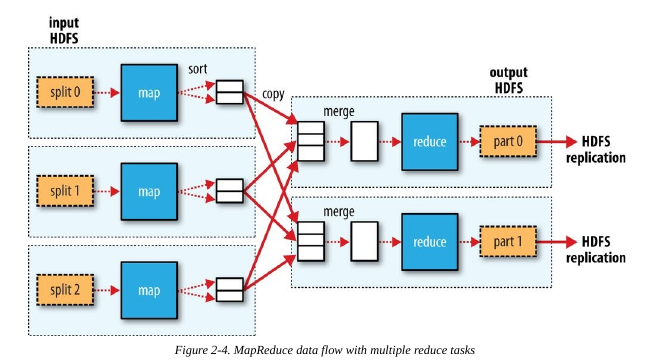
一个MapReduce job是一个客户端希望执行的工作单元,包括输入数据,MapReduce程序和配置信息。Hadoop把job分割成tasks即map task和reduce task。这些tasks由YARN调度并运行在集群的节点上,如果一个task失败了,它将自动调到其他节点重新运行。Hadoop把一个MapReduce job输入数据分割成固定大小的片段称为输入片段,Hadoop为每个片段创建map task.
每一片数据的处理时间要小很多,但是也不能分太多片,通常一片数据的大小为一个HDFS block的大小(默认128MB).
hadoop试图在数据本地进行计算,reduce的输入通常是所有map的输出,没有数据本地性。
MapReduce的数据流
Combiner Functions
用户可以指定一个合并函数处理map的输出,并成为reduce的输入,但是合并函数不是MapReduce的标配,hadoop并不能保证调用多少次合并函数。
指定合并函数
job.setCombinerClass(MyCombiner.class)Hadoop Streaming
Hadoop提供了MapReduce的API,允许使用非JAVA的其他语言写自己的map和reduce函数。Streaming天生适用于文本处理,map的输入数据通过标准输入流传递给map函数,最后将结果写到标准输出。
Chap 3 Hadoop分布式文件系统
HDFS设计
- 超大文件
- 流式数据访问
一次写入、多次读取 - 大量小文件
HDFS的概念
HDFS上的文件被分为多个块,作为独立的存储单元,HDFS中小于一个块大小的文件不会占据整个块的空间。
块的大小不易太大,map任务通常一次只处理一个块中的数据,如果任务数太少速度就会慢。
显示块信息
hadoop fsck / -files -blocksnamenode和datanode
namenode管理文件系统的命名空间,维护文件系统树及整颗树内所有文件和目录,这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。
datanode也记录着每个该文件中各个块所在的数据节点信息,但不永久保存块的位置信息,因为这些信息会在系统启动时由数据节点重建。
客户端代表用户通过与namenode和datanode交互访问整个文件系统
联邦HDFS
Hadoop2.x允许添加namenode实现扩展,每个namenode管理部分命名空间。
从HDFS url读取数据
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
//每个java虚拟机只能调用一次
}
public static void main(String[] args) throws Exception {
InputStream in = null;
try {
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}通过FileSystem API读取数据
获取FileSystem对象的几个工厂方法
public static FileSystem get(Configuration conf) throws IOException
//返回默认文件系统conf/core-site.xml中指定的
public static FileSystem get(URI uri, Configuration conf) throws IOException
public static FileSystem get(URI uri, Configuration conf, String user)
throws IOExceptionpublic class FileSystemCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
//open方法获取文件的输入流
IOUtils.copyBytes(in, System.out, 4096, false);
www.it-ebooks.info } finally {
IOUtils.closeStream(in);
}
}
}FSDataInputStream对象
FileSystem对象中的open()方法返回的是FSDataInputStream对象,它支持随机访问,可以从流的任意位置读取数据。
使用FSDataInputStream对象的seek方法输出两次文本:
public class FileSystemDoubleCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
FSDataInputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(0); // go back to the start of the file
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}写入数据
public FSDataOutputStream create(Path f) throws IOException
public FSDataOutputStream append(Path f) throws IOException
public interface Progressable {
public void progress();
}//用于传递回调接口public class FileCopyWithProgress {
public static void main(String[] args) throws Exception {
String localSrc = args[0];
String dst = args[1];
InputStream in = new BufferedInputStream(new FileInputStream(localSrc));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst), conf);
OutputStream out = fs.create(new Path(dst), new Progressable() {
public void progress() {
System.out.print(".");
}
});
IOUtils.copyBytes(in, out, 4096, true);
}
}
Typical usage:
% hadoop FileCopyWithProgress input/docs/1400-8.txt
hdfs://localhost/user/tom/1400-8.txt
.................目录
FileSystem类提供了一个创建目录的方法
public boolean mkdirs(Path f) throws IOException显示一组Hadoop目录的的文件信息
public class ListStatus {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path[] paths = new Path[args.length];
for (int i = 0; i < paths.length; i++) {
paths[i] = new Path(args[i]);
}
FileStatus[] status = fs.listStatus(paths);
Path[] listedPaths = FileUtil.stat2Paths(status);
for (Path p : listedPaths) {
System.out.println(p);
}
}
}文件模式匹配
Hadoop为文件通配提供了两个方法
public FileStatus[] globStatus(Path pathPattern) throws IOException
public FileStatus[] globStatus(Path pathPattern, PathFilter filter)
throws IOExceptionPathFilter用于匹配排除正则表达式的路径
public class RegexExcludePathFilter implements PathFilter {
private final String regex;
public RegexExcludePathFilter(String regex) {
this.regex = regex;
}
public boolean accept(Path path) {
return !path.toString().matches(regex);
}删除数据
FileSystem的delete()方法可以永久删除数据
public boolean delete(Path f, boolean recursive) throws IOExceptionnamenode会告诉客户端每个块中最佳的datanode并让客户端直接连接到该datanode检索数据。namenode只响应块位置请求,不需要读取数据。
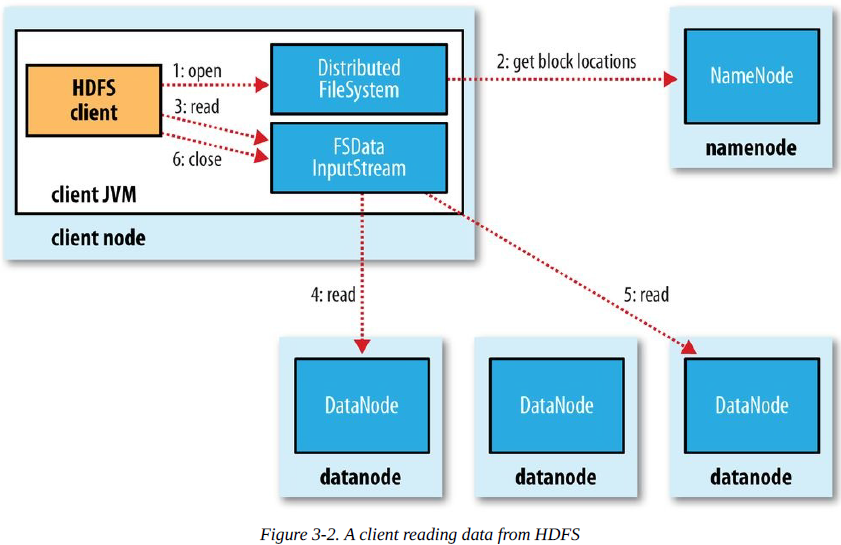
HDFS提供一个方法来使所有缓存与数据节点强行同步,即对FSDataOutputStream调用sync()方法,保证新写入的文件对所有新的reader()均可见。
FileOutputStream out = new FileOutputStream(localFile);
out.write("content".getBytes("UTF-8"));
out.flush(); // flush to operating system
out.getFD().sync(); // sync to disk
assertThat(localFile.length(), is(((long) "content".length())));
Closing a file in HDFS performs an implicit hflush(), too:
Path p = new Path("p");
OutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.close();
assertThat(fs.getFileStatus(p).getLen(), is(((long) "content".length())));通过Flume和Sqoop导入数据
后期补上
通过distcp并行复制
两个HDFS集群之间传输数据
hadoop distcp hdfs://namenode1/foo hdfs://namenode2/barChap 4 Hadoop IO
HDFS完整性
客户端在读取数据块时会验证校验和
数据压缩
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
//Map输出压缩
conf.setCompressMapOutput(true);
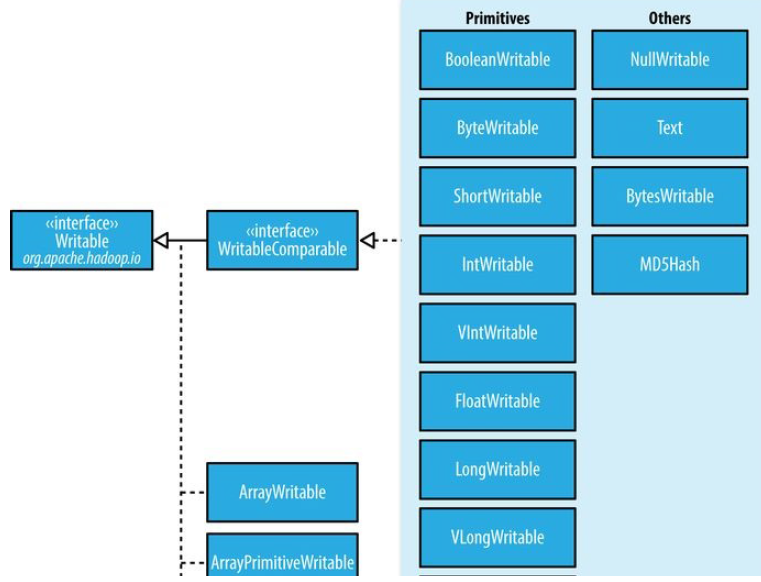
conf.setMapOutputCompressorClass(GzipCodec.class);Writable接口
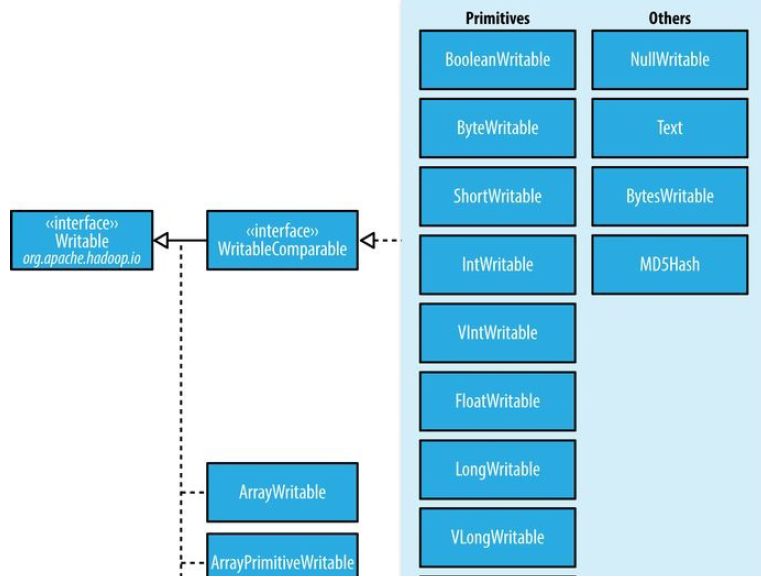
Writable接口定义了两个方法:一个将其状态写到DataOutput二进制流,另一个从DataInput二进制流读取状态:
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}
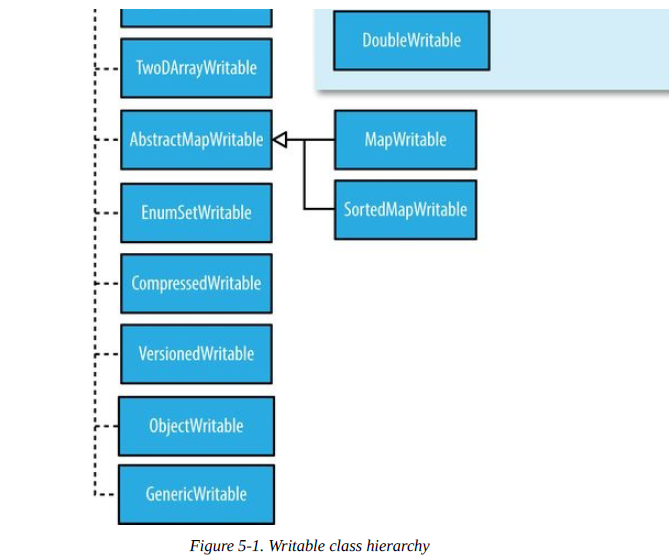
Text类型
5 ObjectWritable和GenericWritable
ObjectWritable是对Java基本类型(String,enum,Writable,null)的一个通用封装。
6 Writable集合类
ArrayWritable, ArrayPrimitiveWritable, TwoDArrayWritable, MapWritable,
SortedMapWritable, 和 EnumSetWritable.
实现定制的Writable集合
import java.io.*;
import org.apache.hadoop.io.*;
public class TextPair implements WritableComparable<TextPair> {
private Text first;
private Text second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
@Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
@Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
}
@Override
public boolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
public String toString() {
return first + "\t" + second;
}
@Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {
return cmp;
}
return second.compareTo(tp.second);
}
}
SequenceFile
SequenceFile为二进制键/值对提供了一个持久数据结构。它也可以作为小文件的容器。
SequenceFile的写操作:
写一个SequenceFile:
public class SequenceFileWriteDemo {
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks",
"Seven, eight, lay them straight",
"Nine, ten, a big fat hen"
};
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path,
key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}
SequenceFile的读操作:
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable)
ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable)
ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}
第5章 MapReduce应用开发
5.1用于配置的API
一个Configuration类的实例代表配置属性及其取值的一个集合。Configuration从资源(XML文件)中读取其属性
Configuration conf = new Configuration();
conf.addResource("configuration-1.xml");
assertThat(conf.get("color"), is("yellow"));
辅助类GenericOptionsParser,Tool和ToolRunner
比较方便的是实现Tool接口,通过ToolRunner来运行程序,ToolRunner内部调用GenericOptionsParser.
public class ConfigurationPrinter extends Configured implements Tool {
static {
Configuration.addDefaultResource("hdfs-default.xml");
Configuration.addDefaultResource("hdfs-site.xml");
Configuration.addDefaultResource("yarn-default.xml");
Configuration.addDefaultResource("yarn-site.xml");
Configuration.addDefaultResource("mapred-default.xml");
Configuration.addDefaultResource("mapred-site.xml");
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
for (Entry<String, String> entry: conf) {
System.out.printf("%s=%s\n", entry.getKey(), entry.getValue());
}
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new ConfigurationPrinter(), args);
System.exit(exitCode);
}
}
第六章 MapReduce的工作机制
6.1作业的提交
运行作业的两种方法:
Job对象的submit()方法和waitForCompletion()(用于提交以前没有提交过的作业)
经典的MapReduce工作机制:
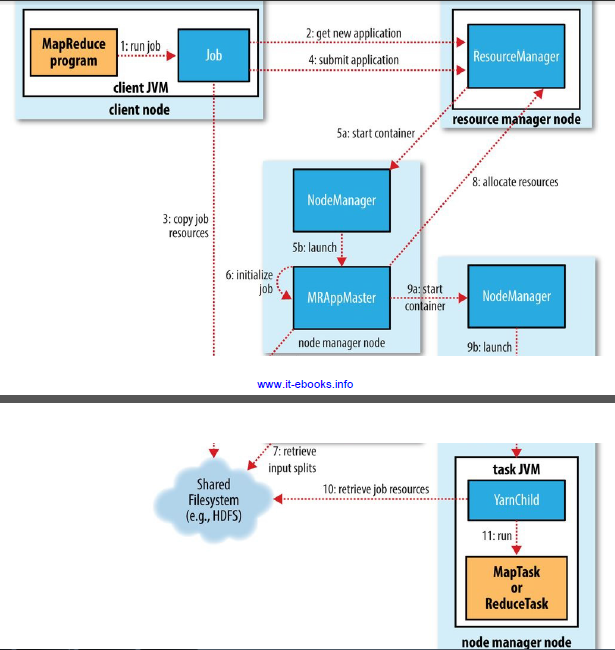
6.2作业的初始化
当JobTracker接收到对其submitJob方法的调用后,会把次调用放入一个内部队列中,交由作业调度器(job scheduler)进行调度,并对其进行初始化。初始化包括创建一个表示正在运行作业的对象,用于封装任务和记录信息,以便跟踪任务的状态和进程。调度器首先获取输入分片,为每个分片创建一个map任务。
6.3 任务的分配
TaskTracker运行一个简单的循环定期发送“心跳”给jobtracker,tasktracker会指明自己是否已经准备好运行新的任务
6.4 任务的执行
Step 1:从共享文件系统把作业JAR文件复制到tasktracker所在的文件系统,实现JAR文件本地化,同时tasktracker将应用程序所需要的全部文件从分布式缓存复制到本地磁盘。
Step 2:tasktracker为任务新建一个本地工作目录,并把JAR文件中的内容解压到这个文件夹下。
Step 3:tasktracker新建一个TaskRunner实例来运行该任务。TaskRunner启动一个新的JVM来运行每个任务,以便用户定义的map和reduce函数的任何软件问题都不会影响到tasktracker。
6.5 进度和状态的更新
MapReduce作业是长时间运行的批量作业,
6.6作业的完成
当jobtracker收到作业最后一个任务已完成的通知后,便把作业的状态设置为“成功”
6.3作业的调度
公平调度器:让每个用户公平共享集群能力。支持抢占机制
容量调度器:集群由很多队列组成,这些队列可能是层次结构,每个队列分配有一定容量,每个队列内根据FIFO方式调度。
6.4 shuffle和排序
MapReduce确保每个reducer的输入都是按键排序的。系统执行排序的过程称为shuffle.
6.4.1 Map端
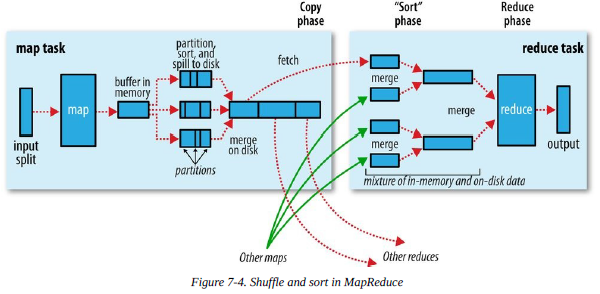
每个map任务都有一个环形缓冲区用于存储任务输出看,在默认情况下,缓冲区大小为100MB,一旦达到阈值,一个后台线程开始把内容溢出(spill)到磁盘。
在写磁盘之前,线程首先根据数据reducer把数据划分成相应的分区。在每个分区中后台线程按键进行内排序,如果有combiner,它就在排序后的输出上运行。任务完成之前,溢出文件被合并成一个已分区且已排序的输出文件。
压缩map输出设置mapred.compress.map.output=true.
Reducer通过HTTP方式得到输出文件的分区。
6.4.2 reduce端
Map输出文件位于运行map任务的tasktracker的本地磁盘, 只要有一个map任务的map输出完成,reduce任务就开始复制其输出。复制完所有map输出后,reduce任务进入排序阶段,这个阶段将合并map输出,维持其顺序排序,这是循环进行的。比如,如果有50个map输出,而合并因子是10,合并进行5趟,最后有5个中间文件,这5个中间文件将直接输入到reduce函数而省略一趟合并。
6.5任务的执行
推测执行:在一个作业的所有任务都启动后,对“拖后腿”的任务启动推测任务,“拖后腿”的任务和推测任务后完成的将会被终止。
第七章MapReduce的类型与格式
1 FileInputFormat类
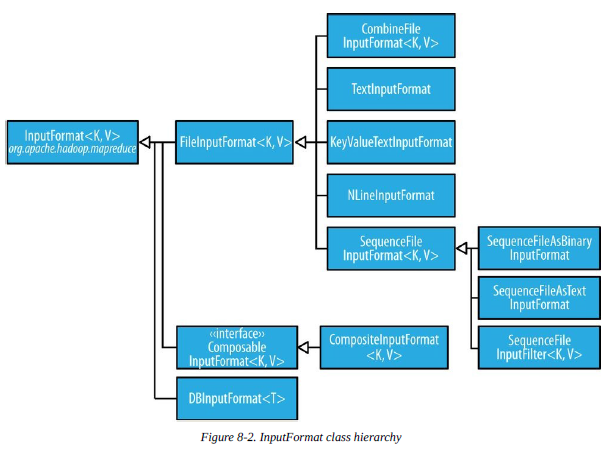
2 FileInputFormat输入路径
public static void addInputPath(Job job, Path path)
public static void addInputPaths(Job job, String commaSeparatedPaths)
public static void setInputPaths(Job job, Path… inputPaths)
public static void setInputPaths(Job job, String commaSeparatedPaths)
3 FileInputFormat类的输入分片
FileInputFormat只分割大文件,即超过HDFS块的大小。
4 小文件与CombineFileInputFormat
CombineFileInputFormat把多个文件打包到一个分片中以便每个mapper可以处理更多的数据。
2 文本输入
1 TextInputFormat
<偏移量,记录>
2 KeyValueTextInputFormat
<分隔符前,分隔符后>
3 NLineInputFormat
固定分片大小的TextInputFormat
输出格式
第八章 MapReduce特点
计数器
public class MaxTemperatureWithCounters extends Configured implements Tool {
enum Temperature {
MISSING,
MALFORMED
}
static class MaxTemperatureMapperWithCounters
extends Mapper<LongWritable, Text, Text, IntWritable> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
int airTemperature = parser.getAirTemperature();
context.write(new Text(parser.getYear()),
new IntWritable(airTemperature));
} else if (parser.isMalformedTemperature()) {
System.err.println("Ignoring possibly corrupt input: " + value);
context.getCounter(Temperature.MALFORMED).increment(1);
} else if (parser.isMissingTemperature()) {
context.getCounter(Temperature.MISSING).increment(1);
}
// dynamic counter
context.getCounter("TemperatureQuality", parser.getQuality()).increment(1);
}
}
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(MaxTemperatureMapperWithCounters.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MaxTemperatureWithCounters(), args);
System.exit(exitCode);
}
}














 1521
1521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









