







 本文介绍了Spark ML的基础,强调DataFrame和Dataset在机器学习中的作用,特别是DataFrame/Dataset API和功能操作,如聚合、字符串处理等。文章还以Binarizer为例解析了特征处理,并指出自定义UDF在ML feature中的重要性。
本文介绍了Spark ML的基础,强调DataFrame和Dataset在机器学习中的作用,特别是DataFrame/Dataset API和功能操作,如聚合、字符串处理等。文章还以Binarizer为例解析了特征处理,并指出自定义UDF在ML feature中的重要性。
Spark ML 是基于DataFrame/ Dataset进行机器学习API的开发,随着Spark 2.0的发展,Dataset将成为主流,会逐步取代RDD、DataFrame,当然这个取代只是在Dataset实现已有RDD、DataFrame的API,大家以后就可以用Dataset的API来实现计算逻辑,所以大家不用担心之前学会的RDD、DataFrame没有用处。
博主一般喜欢从源码的角度来看问题和分析问题,也许不太适合你们的口味,所以请大家见谅。
1.1 DataFrame/Dataset
首先看下DataFrame/Dataset的API。
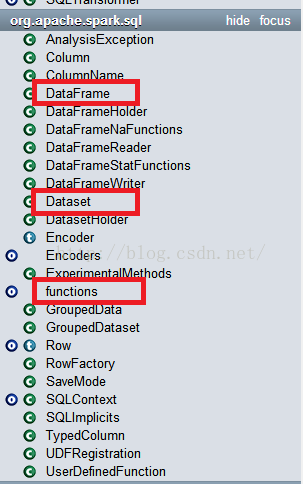
DataFrame/Dataset都是在org.apache.spark.sql,因为都是结构化的数据,所以都是从sql这里来的,具体怎么创建DataFrame和Dataset就不细说了,比较简单的事情。
对于大家平常工作中,重点关注:DataFrame、Dataset、functions这三个的API接口,基本上都能满足大家的工作需要。DataFrame/Dataset的API类似于RDD的,大家可以去看下。对于functions的API大家要重点关注,这里面包括:聚合操作函数、集合操作函数、时间日期函数、数学函数、排序函数、字符串处理函数等等,可支持的函数太多,大家一定要好好细看。
综合上所述,还是写几个实例代码,要不大家就得吐槽我了。
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.functions._
case
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









