






1、数据完整性
IO操作过程中难免会出现数据丢失或脏数据,数据传输得量越大出错得几率越高。校验错误最常用得办法就是传输前计算一个校验和,传输后计算一个校验和,两个校验和如果不相同就说明数据存在错误,比较常用得错误校验码是CRC32.
hdfs数据完整性
hdfs写入的时候计算出校验和,然后每次读的时候再计算校验和。要注意的一点是,hdfs每固定长度就会计算一次校验和,这个值由io.bytes.per.checksum指定,默认是512字节。因为CRC32是32位即4个字节,这样校验和占用的空间就会少于原数据的1%。1%这个数字在hadoop中会经常看到。以后有时间会整理一份hadoop和1%不得不说的故事。
datanode在存储收到的数据前会校验数据的校验和,比如收到客户端的数据或者其他副本传过来的数据。想一下前面的文章hadoop深入研究:(三)——hdfs数据流中客户端写入数据到hdfs时的数据流,在管道的最后一个datanode会去检查这个校验和,如果发现错误,就会抛出ChecksumException到客户端。
客户端从datanode读数据的时候一样要检查校验和,而且每个datanode还保存了检查校验和的日志,客户端的每一次校验都会记录到日志中。
除了读写操作会检查校验和以外,datanode还跑着一个后台进程(DataBlockScanner)来定期校验存在在它上面的block,因为除了读写过程中会产生数据错误以外,硬件本身也会产生数据错误,比如说位衰减(bit rot)。
如果客户端发现有block坏掉呢,会怎么恢复这个坏的块,主要分几步:
1.客户端在抛出ChecksumException之前会把坏的block和block所在的datanode报告给namenode
2.namenode把这个block标记为已损坏,这样namenode就不会把客户端指向这个block,也不会复制这个block到其他的datanode。
3.namenode会把一个好的block复制到另外一个datanode
4.namenode把坏的block删除掉
如果出于一些原因在操作的时候不想让hdfs检查校验码,在调用FileSystem的open方法前调用setVerityCheckSum方法,并设为为false即可,命令行下可以使用-ignoreCrc参数。
实现
LocalFileSystem继承自ChecksumFileSystem,已经实现了checksum功能,,checksum的信息存储在与文件名同名的crc文件中,发现错误的文件放在bad_files文件夹中。如果你确认顶层系统已经实现了checksum功能,那么你就没必要使用LocalFileSystem,改为用RowLocalFileSystem。可以通过更改fs.file.impl=org.apache.hadoop.fs.RawLoacalFileSystem全局指定,也可以通过代码直接实例化。
Configuration conf=...FileSystem fs=new RawLocalFileSystem();fs.initialize(null, conf);如果其他的FileSystem想拥有checksum功能的话,只需要用ChecksumFileSystem包装一层即可:
FileSystem rawFs=...FileSystem checksummedFs=new ChecksumFileSystem(fs){} ;2、文件格式
1. SequenceFile
SequenceFile的文件结构如下:
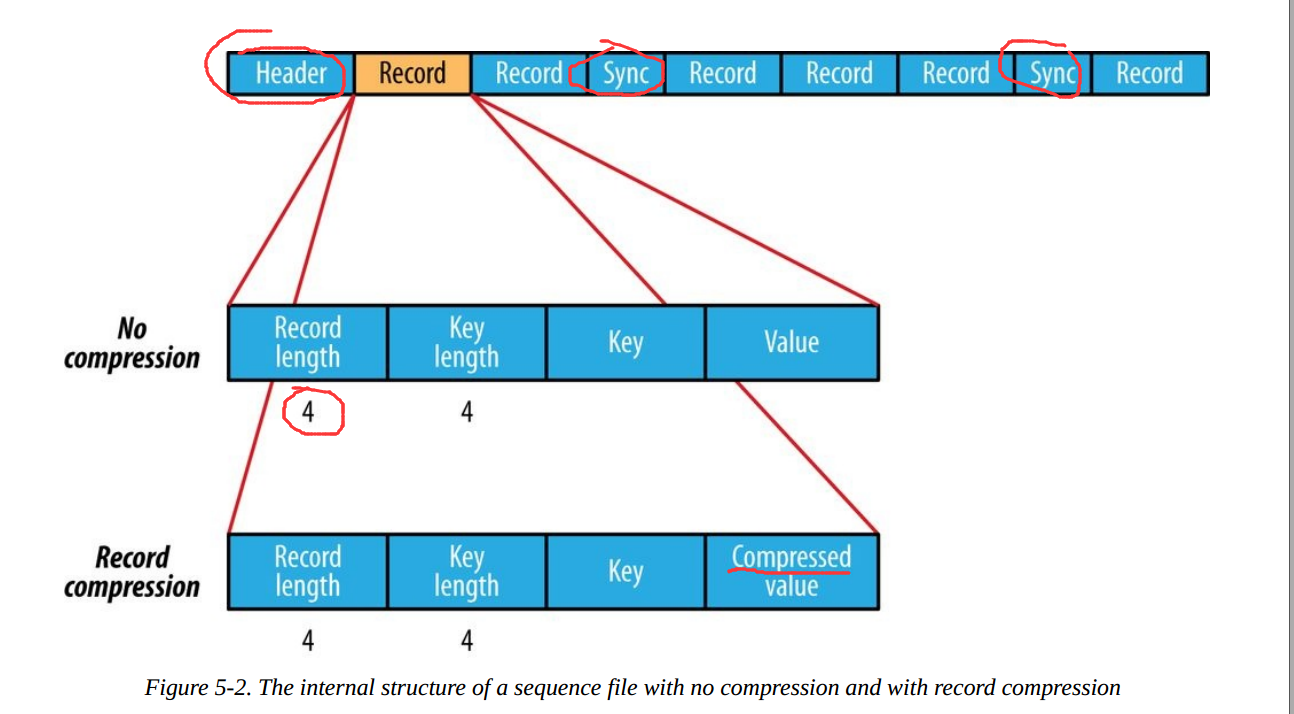
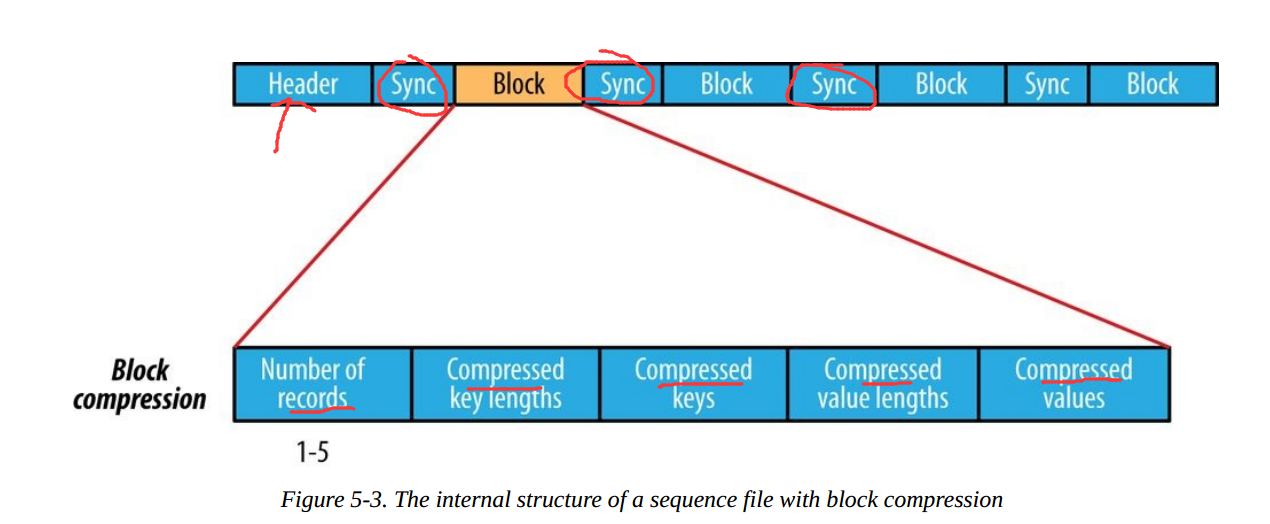
根据是否压缩,以及采用记录压缩还是块压缩,存储格式有所不同:
-
不压缩:
按照记录长度、Key长度、Value程度、Key值、Value值依次存储。长度是指字节数。采用指定的Serialization进行序列化。 -
Record压缩:
只有value被压缩,压缩的codec保存在Header中。 -
Block压缩:
多条记录被压缩在一起,可以利用记录之间的相似性,更节省空间。Block前后都加入了同步标识。Block的最小值由io.seqfile.compress.blocksize属性设置。
2. MapFile
MapFile是SequenceFile的变种,在SequenceFile中加入索引并排序后就是MapFile。索引作为一个单独的文件存储,一般每个128个记录存储一个索引。索引可以被载入内存,用于快速查找。存放数据的文件根据Key定义的顺序排列。
MapFile的记录必须按照顺序写入,否则抛出IOException。
MapFile的衍生类型:
- SetFile:特殊的MapFile,用于存储一序列Writable类型的Key。Key按照顺序写入。
- ArrayFile:Key为整数,代表在数组中的位置,value为Writable类型。
- BloomMapFile:针对MapFile的get()方法,使用动态Bloom过滤器进行优化。过滤器保存在内存中,只有带key值存在的时候,才会调用常规的get()方法,真正进行读操作。
Hadoop体系下面向列的文件包括RCFile,ORCFile,Parquet的。Avro的面向列版本为Trevni。
3. RCFile
Hive的Record Columnar File,这种类型的文件先将数据按行划分成Row Group,在Row Group内部,再将数据按列划分存储。其结构如下:
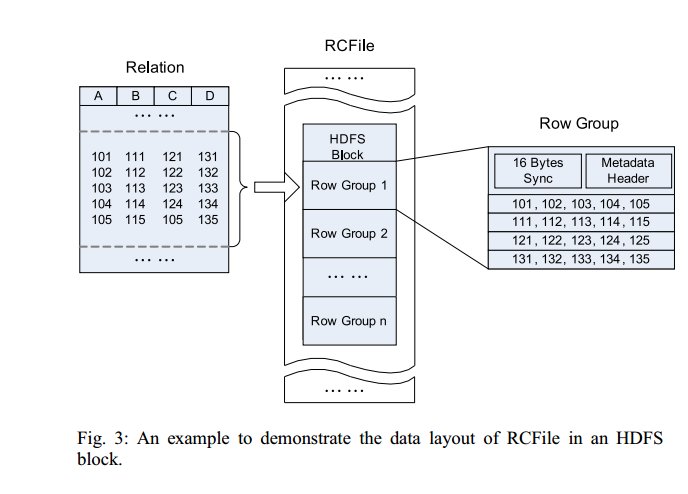
相比较于单纯地面向行和面向列:
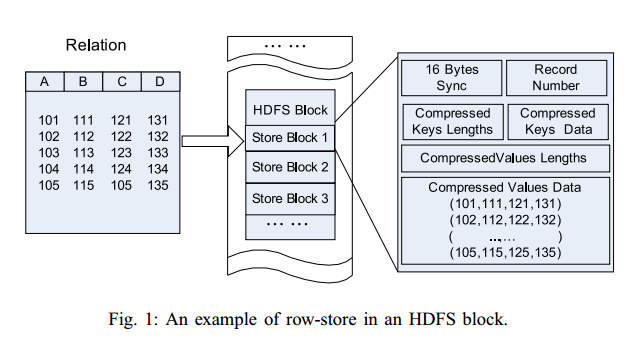
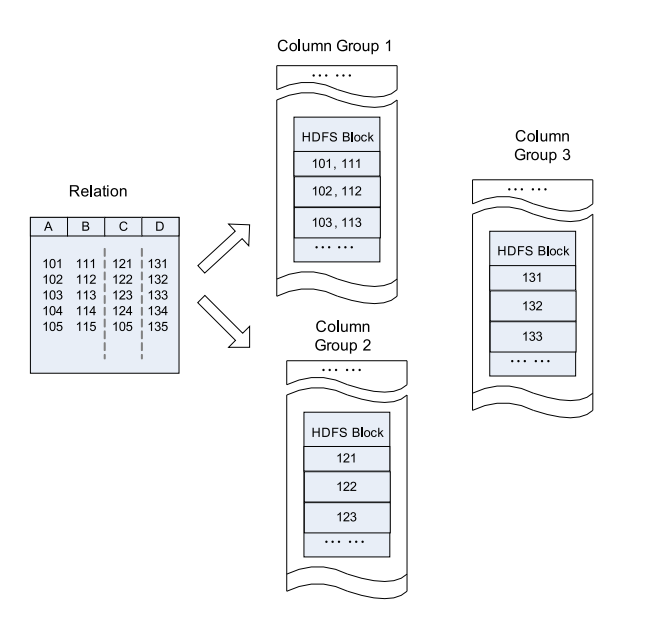
更详细的介绍参考RCFile论文。
4. ORCFile
RCFile(Optimized Record Columnar File)提供了一种比RCFile更加高效的文件格式。其内部将数据划分为默认大小为250M的Stripe。每个Stripe包括索引、数据和Footer。索引存储每一列的最大最小值,以及列中每一行的位置。
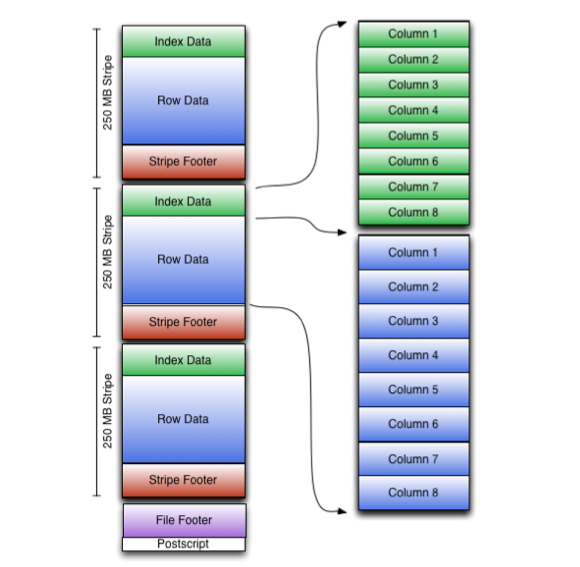
在hive中,如下命令用于使用ORCFile:
- 1
- 2
- 3
5. Parquet
一种通用的面向列的存储格式,基于Google的Dremel。特别擅长处理深度嵌套的数据。
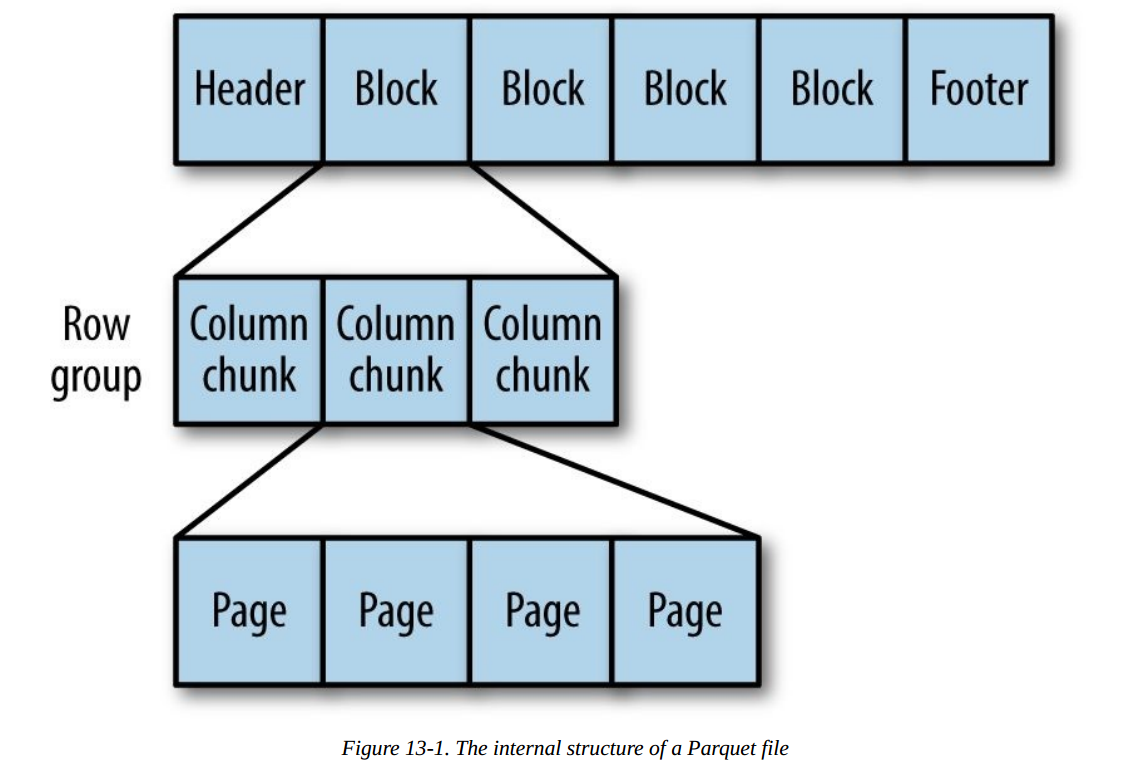
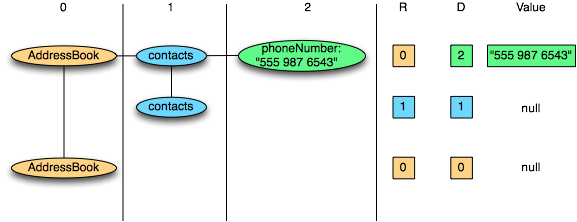
对于嵌套结构,Parquet将其转换为平面的列存储,嵌套结构通过Repeat Level和Definition Level来表示(R和D),在读取数据重构整条记录的时候,使用元数据重构记录的结构。下面是R和D的一个例子:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3、压缩和解压
Hadoop 作为一个较通用的海量数据处理平台,每次运算都会需要处理大量数据,我们会在 hadoop 系统中对数据进行压缩处理来优化磁盘使用率,提高数据在磁盘和网络中的传输速度,从而提高系统处理数据的效率。在使用压缩方式方面,主要考虑压缩速度和压缩文件的可分割性。综合所述,使用压缩的优点如下:
1. 节省数据占用的磁盘空间;
2. 加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度。
Hadoop 对于压缩格式的是自动识别。如果我们压缩的文件有相应压缩格式的扩展名(比如 lzo,gz,bzip2 等)。Hadoop 会根据压缩格式的扩展名自动选择相对应的解码器来解压数据,此过程完全是 Hadoop 自动处理,我们只需要确保输入的压缩文件有扩展名。
Hadoop 对每个压缩格式的支持, 详细见下表:
| 压缩格式 | 工具 | 算法 | 扩展名 | 多文件 | 可分割性 |
|---|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | 不 | 不 |
| GZIP | gzip | DEFLATE | .gzp | 不 | 不 |
| ZIP | zip | DEFLATE | .zip | 是 | 是,在文件范围内 |
| BZIP2 | bzip2 | BZIP2 | .bz2 | 不 | 是 |
| LZO | lzop | LZO | .lzo | 不 | 是 |
性能对比
Hadoop 下各种压缩算法的压缩比,压缩时间,解压时间见下表:
表 2. 性能对比
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
LZO-bset | 8.3GB | 2GB | 4MB/s | 60.6MB/s |
LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
因此我们可以得出:
1) Bzip2 压缩效果明显是最好的,但是 bzip2 压缩速度慢,可分割。
2) Gzip 压缩效果不如 Bzip2,但是压缩解压速度快,不支持分割。
3) LZO 压缩效果不如 Bzip2 和 Gzip,但是压缩解压速度最快!并且支持分割!
这里提一下,文件的可分割性在 Hadoop 中是很非常重要的,它会影响到在执行作业时 Map 启动的个数,从而会影响到作业的执行效率!
所有的压缩算法都显示出一种时间空间的权衡,更快的压缩和解压速度通常会耗费更多的空间。在选择使用哪种压缩格式时,我们应该根据自身的业务需求来选择。
下图是在本地压缩与通过流将压缩结果上传到 BI 的时间对比。
使用方式
MapReduce 可以在三个阶段中使用压缩。
1. 输入压缩文件。如果输入的文件是压缩过的,那么在被 MapReduce 读取时,它们会被自动解压。
2.MapReduce 作业中,对 Map 输出的中间结果集压缩。实现方式如下:
1)可以在 core-site.xml 文件中配置,代码如下
图 2. core-site.xml 代码示例

2)使用 Java 代码指定
conf.setCompressMapOut(true); conf.setMapOutputCompressorClass(GzipCode.class);
最后一行代码指定 Map 输出结果的编码器。
3.MapReduce 作业中,对 Reduce 输出的最终结果集压。实现方式如下:
1)可以在 core-site.xml 文件中配置,代码如下
图 3. core-site.xml 代码示例

2)使用 Java 代码指定
conf.setBoolean(“mapred.output.compress”,true); conf.setClass(“mapred.output.compression.codec”,GzipCode.class,CompressionCodec.class);
最后一行同样指定 Reduce 输出结果的编码器。
4、序列化


 外部集合的比较器
外部集合的比较器
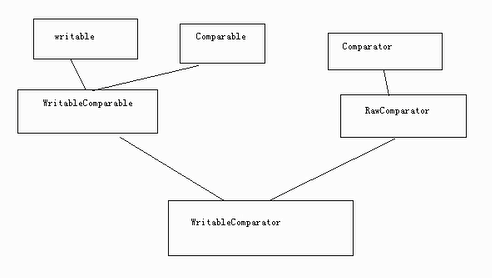
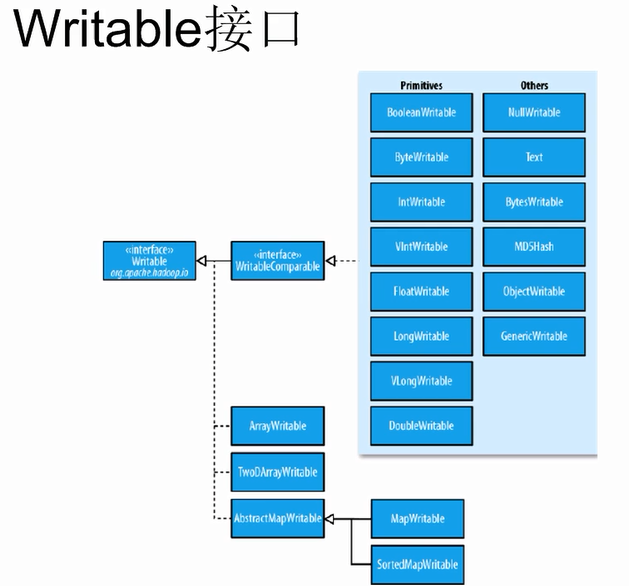


import java.io.DataInput;import java.io.DataInputStream;import java.io.DataOutput;import java.io.DataOutputStream;import java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.io.WritableComparable;public class TestWritableComparable {public static void main(String[] agrs) throws Exception{Student s = new Student("li",20,"man");FileOutputStream fout = new FileOutputStream(new File("/usr/local/test.txt"));DataOutputStream out = new DataOutputStream(fout);s.write(out);fout.close();out.close();Student s1 = new Student();FileInputStream fin = new FileInputStream(new File("/usr/local/test.txt"));DataInputStream in = new DataInputStream(fin);s1.readFields(in);System.out.println(s1.toString());}}class Student implements WritableComparable<Student>{private Text name = new Text();private IntWritable age = new IntWritable();private Text sex = new Text();@Overridepublic String toString() {return "Student [name=" + name + ", age=" + age + ", sex=" + sex + "]";}public Student() {super();}public Student(String name, int age, String sex) {super();this.name = new Text(name);this.age = new IntWritable(age);this.sex = new Text(sex);}public Text getName() {return name;}public void setName(Text name) {this.name = name;}public IntWritable getAge() {return age;}public void setAge(IntWritable age) {this.age = age;}public Text getSex() {return sex;}public void setSex(Text sex) {this.sex = sex;}@Overridepublic void readFields(DataInput in) throws IOException {name.readFields(in);age.readFields(in);sex.readFields(in);}@Overridepublic void write(DataOutput out) throws IOException {name.write(out);age.write(out);sex.write(out);}@Overridepublic int compareTo(Student o) {int result = 0;if((result = name.compareTo(o.getName())) != 0){return result;}if((result = age.compareTo(o.getAge())) != 0){return result;}if((result = sex.compareTo(o.getSex())) != 0){return result;}return result;}}














 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









