







HDFS的IO流操作
1 HDFS文件上传
@Test
public void putFileToHDFS() throws URISyntaxException, IOException, InterruptedException {
//1.获取对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop02:9000"), conf, "code1997");
//2.获取输入流
FileInputStream fis = new FileInputStream(new File("e:/hadoop-2.7.2.tar.gz"));
//3.获取输出流
FSDataOutputStream fos = fs.create(new Path("/hadoop-2.7.2.tar.gz"));
//4.流的对拷
IOUtils.copyBytes(fis,fos,conf);
//5.关闭资源
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
2 HDFS文件下载
大文件下载下来也是完整的。
@Test
public void getFIleFromHDFS() throws URISyntaxException, IOException, InterruptedException {
//1.获取对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop02:9000"), conf, "code1997");
//2.获取输入流
FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.2.tar.gz"));
//3.获取输出流
FileOutputStream fos = new FileOutputStream("e:/hadoop-2.7.2.tar.gz.part");
//4.流的对拷
IOUtils.copyBytes(fis, fos, conf);
//5.关闭资源
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
3 定位读取
3.1 读取第一块
/**
* 定位读取文件:因为大文件是被分块切分的开的,读取第一块128m。
*/
@Test
public void readFileSeek1() throws URISyntaxException, IOException, InterruptedException {
//1.获取对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop02:9000"), conf, "code1997");
//2.获取输入流
FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.2.tar.gz"));
//3.获取输出流
FileOutputStream fos = new FileOutputStream("e:/hadoop-2.7.2.tar.gz.part1");
//4.流的对拷:只拷贝128M
byte[] buffer = new byte[1024];
for (int i = 0; i < 1024 * 128; i++) {
fis.read(buffer);
fos.write(buffer);
}
//5.关闭资源
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
3.2 读取剩下的
/**
* 定位读取文件:读取第二块文件
*/
@Test
public void readFileSeek2() throws URISyntaxException, IOException, InterruptedException {
//1.获取对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop02:9000"), conf, "code1997");
//2.获取输入流
FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.2.tar.gz"));
//3.指定读取的起点:从128m开始进行读取
fis.seek(1024*1024*128);
//4.获取输出流
FileOutputStream fos = new FileOutputStream("e:/hadoop-2.7.2.tar.gz.part2");
//5.流的对拷:只拷贝128M
IOUtils.copyBytes(fis, fos, conf);
//6.关闭资源
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
3.3 文件验证
我们发现下载下来的文件确实是128m和60m的,但是需要我们将他们拼接起来,才知道是不是完整的,我们想要的文件。

win10中使用指令:
type hadoop-2.7.2.tar.gz.part2 >> hadoop-2.7.2.tar.gz.part1

修改part1的后缀:hadoop-2.7.2.tar.gz,然后使用软件查看压缩预览
发现是和之前的软件是同一个。
4 写数据流程
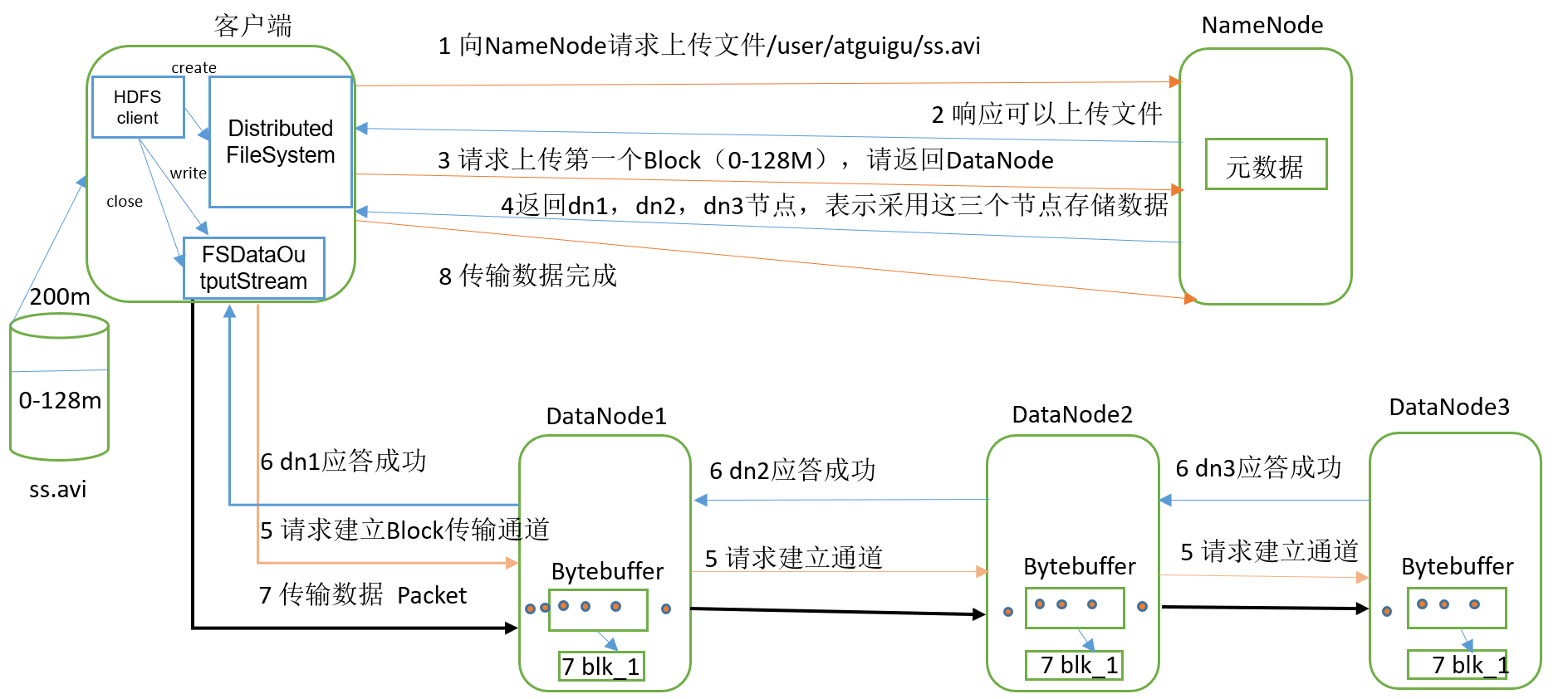
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。















 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









