







 本文深入解读ParseNet论文,探讨如何通过全局上下文增大感受野以提升语义分割效果。研究发现,全局池化能有效增强感受野,而早融合与晚融合在L2正则化后表现相似。L2范数层用于解决不同层特征融合时的尺度问题,其思想与BN层相仿。
本文深入解读ParseNet论文,探讨如何通过全局上下文增大感受野以提升语义分割效果。研究发现,全局池化能有效增强感受野,而早融合与晚融合在L2正则化后表现相似。L2范数层用于解决不同层特征融合时的尺度问题,其思想与BN层相仿。
导言
其实图像语义分割和目标检测如果对比起来看到话,基本上是一样的任务。目标检测需要定位目标并找到最准确的框,而语义分割是把目标分割出来。由此可见,语义分割是比目标检测更困难的任务。有时候并不需要分割出目标,只需要框出来就可以了,比如行人检测,就不一定要把它分割出来,所以目标检测的算法用途也很广泛。如果对比目标检测和语义分割的论文的话,基本上是面对着相似的问题。ParseNet和SSD是同一个作者做的,也有很多相似之处。
ParseNet论文题目就说出了它是使用了更大的感受野这个特点。
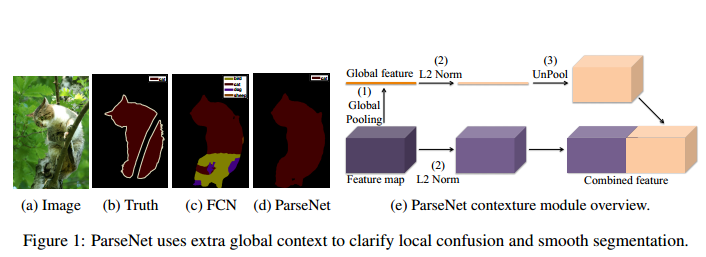
Global Context
作者用一个滑动的噪声去干扰输入图像,观察网络的输出,用来探测一个网络的有效感受野具体有多大。这是个不错的想法,因为论文大都是以核等参数反推出感受野,但是真正有效的感受野到底有多大呢?作者实验发现,理论上VGG的fc7应该有 404×404
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









