




 本文结合《统计学习方法》对机器学习进行深入理解,阐述了机器学习的本质、对象、目的和方法,包括监督、半监督与无监督学习,并详细解释了监督学习中的联合概率分布与输入输出空间的概念,旨在提供对机器学习全面而清晰的认识。
本文结合《统计学习方法》对机器学习进行深入理解,阐述了机器学习的本质、对象、目的和方法,包括监督、半监督与无监督学习,并详细解释了监督学习中的联合概率分布与输入输出空间的概念,旨在提供对机器学习全面而清晰的认识。
机器学习方法概论1
在看论文的时候会遇到很多关于机器学习算法方面的内容,由于专业跨越的缘故,遇到后心中其实并没有系统的知识,只是一个一个算法的去学习,这样做的可以解决当时的一些困惑,但是过久了后遇到同样的问题同样会有点模糊,我想是因为心中并没有对其深入理解以及心中并没有系统的概括吧,所以一多了就混乱了。下面我结合李航《统计学习方法》第一章的内容,对机器学习进行自己的理解和梳理。
机器学习其实就是统计学习,是概率论、统计学、信息论、计算理论、最优化理论及计算机科学等多个邻域的交叉学科。我非常喜欢赫尔伯特-西蒙(Herbert A. Simon)对学习的定义:“如果一个系统能够执行某个过程改进它的性能,这就是学习”。那么统计学习就是计算机系统通过运用数据及统计方法提高系统性能的机器学习。统计学习的对象是数据,关于数据的基本假设是同类数据(具有某种共同性质的数据,如网页数据、文本数据、图像数据等)具有一定的统计规律性,这是统计学习的前提。由于它们具有统计规律行,所以可以用概率统计方法来加以处理,比如,可以用随机变量描述数据中的特征,用概率分布描述数据的统计规律。统计学习的目的就是对数据进行预测和分析,特别是对未知的新数据进行预测和分析。统计学习的方法有:监督学习(supervised learning)、非监督学习(unsupervised learning)、半监督学习(semi-supervised learning)和强化学习(reinforcement learning)等。这里好像只有强化学习的概念比较模糊,其它的几中学习都在一些文章中接触过这些概念。所谓的监督、半监督与无监督,我的理解就是给定的训练数据样本(学习样本)是否带有输出的类别信息,有就是监督,一部分有一部分没有就是半监督,完全没有就是无监督。大家看到的一些算法大多都是监督学习,也是研究最广泛、最传统的方法。半监督学习邻域,国内的周志华老师是这方面的泰斗,周老师文章讲解的也都通俗易懂。我在《半监督学习》有一定的介绍,在传统的监督学习中,学习器通过对大量有标记的(labeled)训练例进行学习,从而建立模型用于预测未见示例的标记。这里的“标记”(label)是指示例所对应的输出,在分类问题中标记就是示例的类别,而在回归问题中标记就是示例所对应的实值输出。随着数据收集和存储技术的飞速发展,收集大量未标记的(unlabeled)示例已相当容易,而获取大量有标记的示例则相对较为困难,因为获得这些标记可能需要耗费大量的人力物力。事实上,在真实世界问题中通常存在大量的未标记示例,但有标记示例则比较少,尤其是在一些在线应用中这一问题更加突出。显然,如果只使用少量的有标记示例,那么利用它们所训练出的学习系统往往很难具有强泛化能力;另一方面,如果仅使用少量“昂贵的”有标记示例而不利用大量“廉价的”未标记示例,则是对数据资源的极大的浪费。因此,在有标记示例较少时,如何利用大量的未标记示例来改善学习性能已成为当前机器学习研究中最受关注的问题之一,半监督学习就是在这样的一种环境中而产生的。这里所总结的也是针对传统的监督学习而言,李航在《统计学习方法》中也是针对监督学习做的讲解。这段主要讲了统计学习的对象(数据)、目的(预测和分析未知新数据)和方法(监督、半监督、无监督等)。
在监督学习中,将输入所有可能取值的集合称为输入空间,将输出所有可能的取值称为输出空间,输入空间与输出空间可以是有限元素的集合,也可以是整个欧式空间,两者可以是同一个空间也可以是不同的空间,但通常输出空间远远小于输入空间。
每个具体的输入是一个实例(instance),通常由特征向量(feature vector)表示。所有特征向量存在的空间称为特征空间(feature space),特征空间的每一维对应一个特征。比如说特征向量是n维的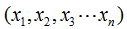
![]() ,表示有n个特征,那么特征空间也是n维的,每一维对应于一个特征。在计算机视觉目标检测与跟踪中经常将目标用特征向量表示。在监督学习过程中,将输入与输出看作是定义在输入(特征)空间与输出空间上的随机变量取值,输入、输出变量用大写字母表示,习惯上输入变量写作X,输出变量写作Y,输入、输出变量所取的值用小写字母表示。输入变量与输出变量均为连续的预测问题就是回归,回归按照输入变量的个数分为一元回归和多元回归,按照输入变量与和输出变量之间的关系类型又分为线性回归和非线性回归(这里都只是提概念,具体又有很多内容可讲了);输出变量为有限个离散变量的预测问题就是分类,输入与输出均为变量序列的预测问题就是标注,监督学习是从训练数据(training data)集合中学习模型,对测试数据(test data)进行预测,注意:训练数据时由输入(特征向量)与输出对组成的,不是仅仅只有输入,输入与输出组的对也就是样本(sample)。我在以前的潜意思中就一直以为样本就是输入,其实是不对的,是输入与输出一起。
,表示有n个特征,那么特征空间也是n维的,每一维对应于一个特征。在计算机视觉目标检测与跟踪中经常将目标用特征向量表示。在监督学习过程中,将输入与输出看作是定义在输入(特征)空间与输出空间上的随机变量取值,输入、输出变量用大写字母表示,习惯上输入变量写作X,输出变量写作Y,输入、输出变量所取的值用小写字母表示。输入变量与输出变量均为连续的预测问题就是回归,回归按照输入变量的个数分为一元回归和多元回归,按照输入变量与和输出变量之间的关系类型又分为线性回归和非线性回归(这里都只是提概念,具体又有很多内容可讲了);输出变量为有限个离散变量的预测问题就是分类,输入与输出均为变量序列的预测问题就是标注,监督学习是从训练数据(training data)集合中学习模型,对测试数据(test data)进行预测,注意:训练数据时由输入(特征向量)与输出对组成的,不是仅仅只有输入,输入与输出组的对也就是样本(sample)。我在以前的潜意思中就一直以为样本就是输入,其实是不对的,是输入与输出一起。
监督学习假设输入和输出的随机变量X和Y遵循联合概率分布P(X,Y),P(X,Y)表示分布函数或分布密度函数。注意,在学习的过程中,假定这一联合概率分布函数存在,但对学习系统而言,联合概率分布的具体定义是未知的。之前假设数据存在一定的统计规律,X和Y具有联合概率分布的假设就是监督学习关于数据的基本假设。联合概率分布这里我觉得并非是我们简单理解为二维随机变量的分布。设E是一个随机试验,它的样本空间是S={e}。设X=X(e)和Y=Y(e)是定义在S上的随机变量,由它们构成的一个向量(X,Y),叫做二维随机向量或二维随机变量。如果将二维随机变量(X,Y)看成是平面上随机点的坐标,那么分布函数F(x,y)在(x,y)处的函数值就是随机点(X,Y)落在以点(x,y)为顶点而位于该点左下方的无穷矩形域内的概率。而监督学习中的联合分布输入X和输入Y可以并非在同一空间,其次变量X和变量Y也只是在宏观上看作是二维的,X可能是一个特征向量。这里我还继续引用找到的资料继续啰嗦一下,Vamei的一篇博客《概率论07联合分布》里有一个例子,一个随机变量是从样本空间到实数的映射。然而,所谓的映射是人为创造的。从一个样本空间,可以同时产生多个映射。比如,我们的实验是连续三次投硬币,样本空间为{hhh, hht, hth, thh, htt, tht, tth, ttt}; h为正面,t为反面。在同一样本空间上,我们可以定义多个随机变量,比如:X--投掷为正面的总数,可以取值0,1,2,3; Y--最后一次出现负面的总数,可以取值0,1; Z--将正面记为10,负面记为5,第一次与第三次取值的差,可以有5, -5, 0; 这三个随机变量可以看作一个有三个分量的矢量。所以定义在同一样本空间的多随机变量,是一个从样本空间到矢量的映射.如果样本空间中每个结果出现的概率相等。而样本空间中共有8个结果,那么个每个结果的出现的概率都是1/8。据此,我们可以计算X和Y的联合概率,比如:P(X=0,Y=1)=P({ttt})=1/8,联合概率可以看做两个事件同时发生时的概率。所以监督学习的联合概率分布只能是借助其含义来说明,即输入与输出同时发生的概率,但又不能简单的看作是一个二维随机变量的分布。
监督学习的目的在于学习一个
由输入到输出的映射
,这一映射由模型来表示,学习的目的就在于找到最好的这样的模型。监督学习的模型可以是概率模型或非概率模型,由
条件概率
P(Y|X)或
决策函数
Y=f(X)表示,传统的算法都是在基于解这两种模型的基础上进行的。
模型的假设空间
包含所有可能的条件概率分布或决策函数。由于公式比较难编辑,这里就直接把《统计学习方法》中的一些公式在这里说明了。



















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









