







1.Elasticsearch概述
Elasticsearch是一个分布式、高性能、高可用、可伸缩的搜索和分析系统。
以下是来自百度的介绍:
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。因此我们利用Elasticsearch来解决所有这些问题以及可能出现的更多其它问题。
2.概念
cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
shards
代表索引分片,ES可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
recovery
代表数据恢复或叫数据重新分布,ES在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
river
代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
gateway
代表ES索引快照的存储方式,ES默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个ES集群关闭再重新启动时就会从gateway中读取索引备份数据。ES支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon3的s3云存储服务。
discovery.zen
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)
3 什么是搜索
百度:我们比如说想找寻任何的信息的时候,就会上百度去搜索一下,比如说找一部自己喜欢的电影,或者说找一本喜欢的书,或者找一条感兴趣的新闻(提到搜索的第一印象)
垂直搜索(站内搜索)
互联网的搜索: 电商网站,招聘网站,新闻网站,各种app
IT系统的搜索:OA软件,办公自动化软件,会议管理,日程管理,项目管理,员工管理,搜索“张三”,“张三儿”,“张小三”;有个电商网站,卖家,后台管理系统,搜索“牙膏”,订单,“牙膏相关的订单”
搜索,就是在任何场景下,找寻你想要的信息,这个时候,会输入一段你要搜索的关键字,然后就期望找到这个关键字相关的有些信息
搜索,就是在任何场景下,找寻你想要的信息,这个时候,会输入一段你要搜索的关键字,然后就期望找到这个关键字相关的有些信息。
4.如果用数据库做搜索会怎样?
做软件开发的话,或者对IT、计算机有一定的了解的话,都知道,数据都是存储在数据库里面的,比如说电商网站的商品信息,招聘网站的职位信息,新闻网站的新闻信息,等等吧。所以说,很自然的一点,如果说从技术的角度去考虑,如何实现如说,电商网站内部的搜索功能的话,就可以考虑,去使用数据库去进行搜索。
1、比方说,每条记录的指定字段的文本,可能会很长,比如说“商品描述”字段的长度,有长达数千个,甚至数万个字符,这个时候,每次都要对每条记录的所有文本进行扫描,懒判断说,你包不包含我指定的这个关键词(比如说“牙膏”)
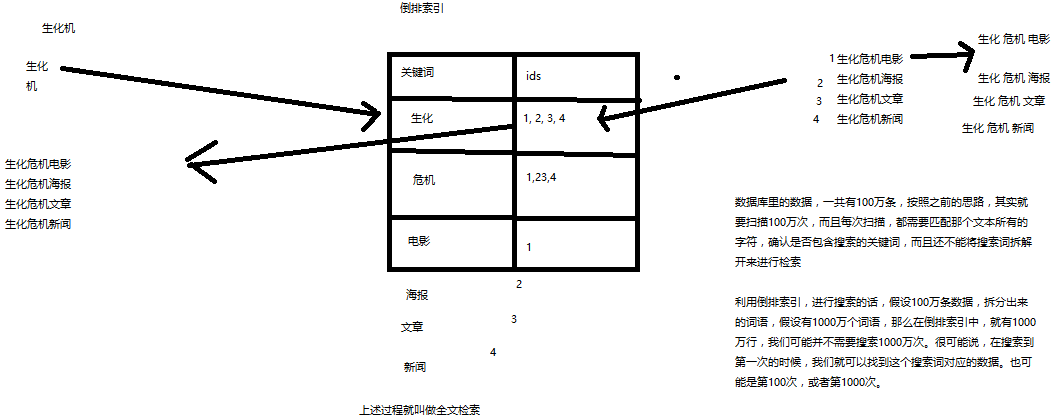
2、还不能将搜索词拆分开来,尽可能去搜索更多的符合你的期望的结果,比如输入“生化机”,就搜索不出来“生化危机”
用数据库来实现搜索,是不太靠谱的。通常来说,性能会很差的。
5、什么是全文检索和Lucene?
(1)全文检索,倒排索引
(2)lucene,就是一个jar包,里面包含了封装好的各种建立倒排索引,以及进行搜索的代码,包括各种算法。我们就用java开发的时候,引入lucene jar,然后基于lucene的api进行去进行开发就可以了。用lucene,我们就可以去将已有的数据建立索引,lucene会在本地磁盘上面,给我们组织索引的数据结构。另外的话,我们也可以用lucene提供的一些功能和api来针对磁盘上额。
6、什么是Elasticsearch
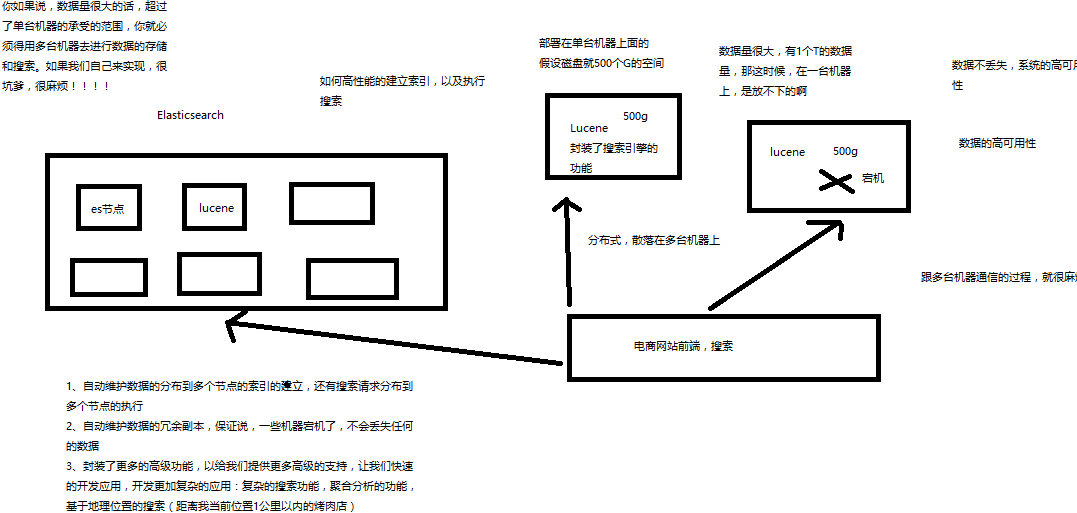
Elasticsearch的好处:
1、自动维护数据的分布到多个节点的索引的建立,还有搜索请求分布到多个节点的执行。
2、自动维护数据的冗余副本,一些机器宕机了,不会丢失任何的数据。
3、封装了更多的高级功能,以给我们提供更多高级的支持。让我们快速的开发应用,开发更加复杂的应用:复杂的搜索功能,聚合分析的功能,基于地理位置的搜索(距离我当前位置1公里内的烤肉店)
7、什么是distributed document store
Elasticsearch在跑起来以后,其实起到的第一个最核心的功能,就是一个分布式的文档数据存储系统。ES是分布式的。文档数据存储系统。文档数据,存储系统。
文档数据:es可以存储和操作json文档类型的数据,而且这也是es的核心数据结构。
存储系统:es可以对json文档类型的数据进行存储,查询,创建,更新,删除,等等操作。其实已经起到了一个什么样的效果呢?其实ES满足了这些功能,就可以说已经是一个NoSQL的存储系统了。
围绕着document在操作,其实就是把es当成了一个NoSQL存储引擎,一个可以存储文档类型数据的存储系统,在操作里面的document。
es可以作为一个分布式的文档存储系统,所以说,我们的应用系统,是不是就可以基于这个概念,去进行相关的应用程序的开发了。
什么类型的应用程序呢?
(1)数据量较大,es的分布式本质,可以帮助你快速进行扩容,承载大量数据
(2)数据结构灵活多变,随时可能会变化,而且数据结构之间的关系,非常复杂,如果我们用传统数据库,那是不是很坑,因为要面临大量的表
(3)对数据的相关操作,较为简单,比如就是一些简单的增删改查,用我们之前讲解的那些document操作就可以搞定
(4)NoSQL数据库,适用的也是类似于上面的这种场景
举个例子,比如说像一些网站系统,或者是普通的电商系统,博客系统,面向对象概念比较复杂,但是作为终端网站来说,没什么太复杂的功能,就是一些简单的CRUD操作,而且数据量可能还比较大。这个时候选用ES这种NoSQL型的数据存储,比传统的复杂的功能务必强大的支持SQL的关系型数据库,更加合适一些。无论是性能,还是吞吐量,可能都会更好。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











