






可能前面的几篇博客太偏理论了,班上同学都说看不懂,因此还是决定写写偏应用的东西。因为只看过图像处理和NLP相关的内容,因此就让班上同学选择下想看哪一个。最后服从大流选择写有关Deep Learning在图像处理方面的一些内容。在此也特别谢谢电子科技大学10级信安一班各位的支持,真的是特别想你们,同样也谢谢计算智能实验室的各位基友们。好,现在就开始之后的几篇关于图像处理的内容。因为现在Deep Learning关于图像处理的应用主要是通过卷积神经网络(Convolutional Neural Networks,CNN)来实现的,当然根据不同的问题需要对模型做出一些不同的改变。但万变不离其宗,只要将基本的CNN原理搞懂了,那么理解起其他的模型来就很快了。因此,我们先来讨论下基本的CNN模型,之后再结合具体的问题来介绍不同的变体,可能就会与试验结合的比较紧密了。
首先,我们来对CNN的整体结构有个大致的印象。
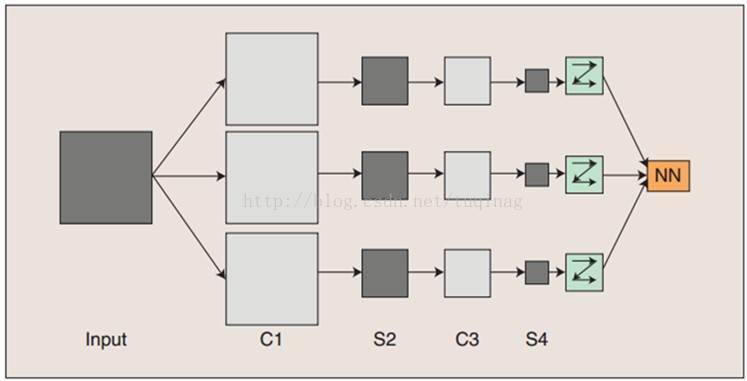
其中,C表示的是卷积层的意思,其主要作用是提取出图片中的特征,对图片能够起到一定的降维作用。S表示的是下采样层,其主要作用是对图片进行降维,同样能够使得模型针对图片具有较好的旋转、平移、放缩的不变性。这一点在图像处理中还是十分重要的。一般情况下,我们主要使用的下采样方法是池化方法,所以之后我们会主要针对池化方法进行讨论。从上图中,我们可以看到,卷积操作和池化操作是交替进行的,这只是在基本的CNN中是这样的,针对不同的问题,可能会需要对两种操作的顺序进行一定的调整。仔细观察上图,可能有些人会问为什么会有多列的神经网络?我们可以这样来理解,对于一个卷积操作,它只会提取图片中的一种特征,当我们的数据量很大时,一种特征肯定是远远不够的。因此,我们需要借助不同的卷积操作(不同的卷及操作就是使用不同的参数而已)来提取图像中的不同的特征,所以就会有多列的神经网络产生。最后综合这些不同的特征来得到最后的分类器。根据我们对于CNN的大体上的介绍,其主要有两个关键的操作,卷积和池化,因此之后就对这两种操作进行详细的介绍。
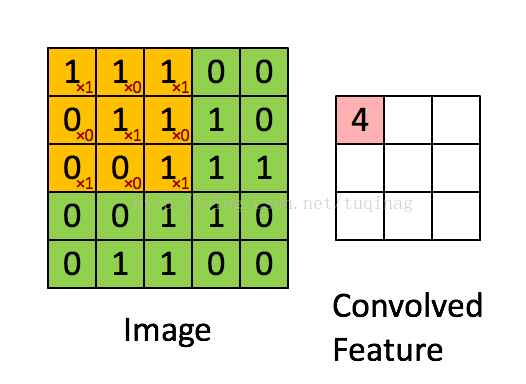
首先是对于卷积的概念,这是我认为是在CNN中最重要的概念,没有之一,CNN的成功我觉得还是主要是卷积的功劳。卷积的核心就是局部感受野的概念。试想,对于一个100X100的图像,如果一个神经元要对其进行全连接,则会有10^4个参数,这还只是一个神经元的参数,深度模型神经元个数那么多,参数的个数是不能接受的。如果引入局部感受野的概念之后呢,如果我们定义局部感受野的大小为10X10。这里我们还要引入卷积的另一个重要概念,就是参数共享。其含义是,对于一张图片进行卷积操作,每个感受野所使用的参数都是相同的。这样,在引入局部感受野后,模型的参数就降为了10^2,有效降低了模型参数的个数。引入一张图来说明下该过程:

接下来就介绍下卷积的数学定义,对于每一个卷积层都是针对其前一层的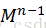
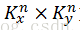
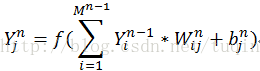
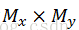
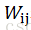
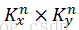


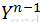
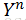
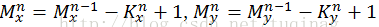
这里的激活函数是scaled双曲正切函数:
在一张图片上,对于filter的使用,有点像滑动窗口的概念,会产生重叠。一般情况下只会移动一个像素,但根据不同的问题,移动的长度也会有所不同。还有比较重要的一点是,如果两个相邻的卷积层之间的feature map(就相当于是卷积)数目并不相同(池化层是不会对feature map的数目进行任何更改的),则可以认为是之后一层的feature map是由之前一层的feature map组合而成。至于是如何进行组合的,在具体的模型中会有不同的做法。我感觉已经无数次提到了具体问题具体的做法了,但实际上确实如此,Deep Learning太过于庞大,导致里面小的trick太多了,或许每一个对于模型的提升也许并不明显,但将它们结合起来,或许会取得不错的效果。我觉得,这也是为什么,总是那几个大牛才能发出质量特别高的文章,因为这些小的trick并不会在他们的文章中被提及,即使采用相同的模型也不能达到他们相同的效果。
卷积的概念就差不多介绍完了,接下来就是池化的内容,这个就比较简单了。 池化层的输出结果是一个大小为
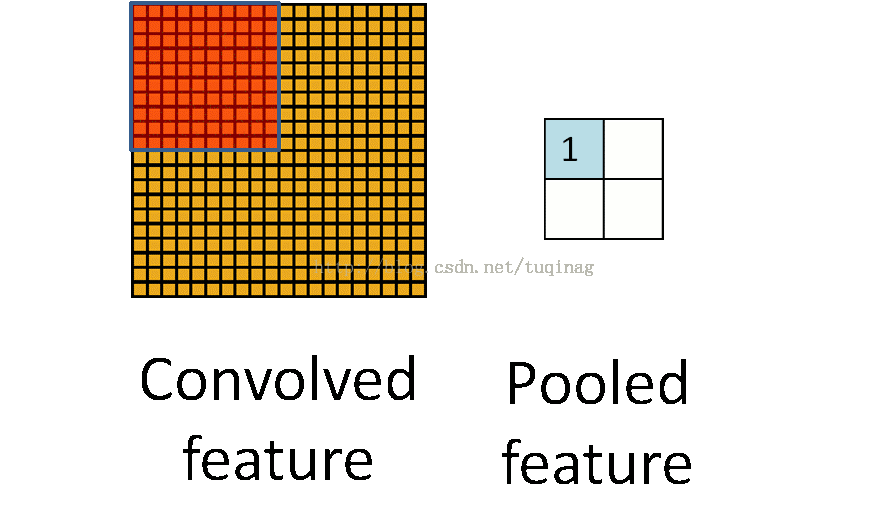
注意到,之前我们说的是取最大的激活值,对于池化操作来说,其实有平均池化和最大池化两种方式可以选择。平均池化,顾名思义,就是取矩形区域中激活值的平均值来代表这个区域。试验证明,最大池化方法可以导致更快的收敛、能够选择到更好的具有不变性的特征,以及能够更好的提高模型的泛化能力。因此,最大池化是用的很频繁的,还有很多关于最大池化的扩展。还有一点,前面我们提到池化区域一般来说是不重叠的,这与感受野是不同的。但在某些情况下,也可以使它重叠,那么就与感受野是一样的了。说了这么多,让人感受到,任何事物并不是一成不变的。
卷积层中感受野的大小以及池化层中池化区域的大小都需要被精心的选择,以保证在最后一个卷积层每一个map在经历池化过程之后都会被降到1个像素点,或者是最后一个卷积层在经历池化之后连接到一个全连接层以产生一个一维的特征向量。整个模型的最后一层通常是全连接层,对于每一个分类来说都会有一个输出。在输出层中,通常会使用一个softmax激活函数,这样,对于每一个类别,都只会有一个神经元处于激活状态,这就表示了输入就是属于这个类别的。
在介绍完卷积和池化这两大操作后,其实已经可以对CNN模型有比较好的理解了。但还有很重要的一点没有介绍就是,建立模型之后,又应该如何对模型进行学习呢? 主要还是利用BP算法来对网络进行调参,下面就主要来讲BP算法调参的具体过程。
对于输出层,目标函数为
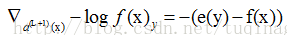
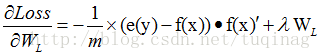
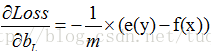
卷积层的下一层为池化层,求卷积层的误差敏感项。假设卷积层的大小为4X4,池化区域的大小为2X2,那么池化层的大小为2X2.假设池化层的误差敏感值为:
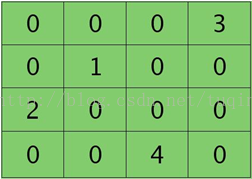
池化层的下一层为卷积层,求池化层的误差敏感项。假设第l层(池化层)有N个特征,第l+1层(卷积层)有M个特征,由第l+1层中第j个核对第l层中第i个核的误差敏感项的计算方法为: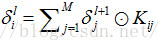
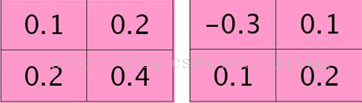
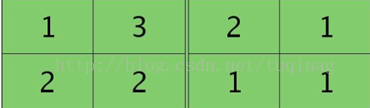

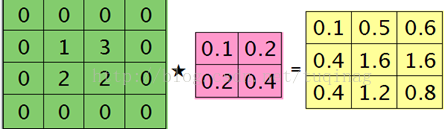

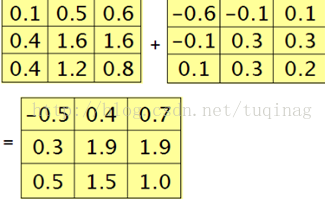
在计算时,需要对核函数进行旋转180度这一关键操作,在matlab中,在函数内部已经默认执行了这一操作,我们就不需要再做了。
计算各层之间权值与偏置的增量:
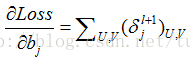
对CNN的介绍就到此为止了,之后呢,会针对不同的问题,讨论下CNN的一些变形,包括如何将其使用在时序性数据中。这周,更了两篇,下周回家,国庆放假就算了,刚好。















 4697
4697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









