







 卷积神经网络(CNN)是专为图像识别设计的网络,模仿人类视觉处理过程。与BPNN相比,CNN在处理图像时更高效,参数较少。CNN的核心是卷积操作,通过卷积核对图像进行扫描,提取特征。权重共享机制降低了计算量,卷积层的输出称为特征平面,表示图像中符合特征的程度。
卷积神经网络(CNN)是专为图像识别设计的网络,模仿人类视觉处理过程。与BPNN相比,CNN在处理图像时更高效,参数较少。CNN的核心是卷积操作,通过卷积核对图像进行扫描,提取特征。权重共享机制降低了计算量,卷积层的输出称为特征平面,表示图像中符合特征的程度。
卷积神经网络(Convolutional Neural Network)是一个专门针对图像识别问题设计的神经网络。它模仿人类识别图像的多层过程:瞳孔摄入像素;大脑皮层某些细胞初步处理,发现形状边缘、方向;抽象判定形状(如圆形、方形);进一步抽象判定(如判断物体是气球)。

CNN与BPNN的异同
如果了解BPNN的框架,那么更容易理解CNN了。本文从CNN与BPNN的异同点出发,分析CNN的结构。首先相同点是CNN与BPNN一样都是神经网络,含有多层神经元,每层神经元到下层都有权重相连,误差传导也是反向的模式。
CNN与BPNN的区别在于CNN是在BPNN的基础上针对图像识别问题进行了优化。设想一下,如果给定一个照片,用BPNN训练会有什么后果?假设照片是RGB照片(含有R、G、B三个通道,每个像素点的值是0-255),用BPNN其实也可以训练。首先要把它展开成一个很长的一维数组,因为BPNN的输入只能是一维的。假如照片是500*500(已经很小了),那么展开以后就是500*500*3=750000的输入长度,即使隐含层只有一层,且该层只有一个神经元,从输入层到隐含层的权重也需要750000个,参数太多了无法估计。那么如何精简参数呢?
特征抽取
回忆BPNN,每一层在做的实际上是抽取特征,权重就表示了特征。CNN的特征抽取没有那么简单,需要有两个部件:卷积、池化。
卷积
卷积是CNN的核心,是用卷积核扫描图像,得到相应的特征。卷积核可以理解成过滤器(或图像扫描器、特征扫描器、局部感受野)。这里先不涉及到卷积的具体操作,只介绍卷积的简单概念。在BPNN中,前后层神经元的连接是“全连接”,即每个神经元都与前一层所有神经元相连,而卷积是每个神经元只与上一层的一部分神经元相连。
可以想象这么一个场景,公司根据地域分为西北区、西南区、华东区、华南区等销售区域,现进行大规模人员调整,各区域的业务人员全部撤换掉。新老员工面临工作交接,BPNN的做法是老员工排成一行,新员工排成一行,不分地域,老员工要和每个新员工交接,新员工也要和每个老员工交接,这样效率十分低下(西北地区的老员工和华南地区的新员工实际上没什么好交接的);而CNN是按照各大销售区域排队,西北地区的老员工站在一起,华东地区的老员工站在一起,下一层负责各个区域的新员工也按照负责区域站好,各个区域内部的新老员工交接即可。
这样做有两个好处:
1. 从仿生的角度来说,CNN对于处理图像或上例中区域等矩阵问题更加高效。人的视觉神经元不需要对全部图像感知,只需要对局部感知即可(举个不恰当的例子,我们看某个物体的时候,人眼接收到的画面其他部分就虚化了)。距离较远的元素,相关性比较弱。
2. 从计算的角度来说,卷积使得参数大大减小,计算量大大下降。假如有100个销售区域(事实上图像远大于100,例如上述的500*500像素的例子),每个销售区域老员工有100名,新员工也有100名,那么BPNN就需要10000*10000=1亿次交接。而如果按照销售区域交接,每个新员工只和对应区域的100名老员工交接,那么需要10000*100=100万次,是以前的1%,进一步,卷积中存在“权值共享”,即下一层神经元A所负责的区域虽然和B负责的区域不一样,但是他们的参数是一样的。对应到上边的例子中,虽然各个区域具体的业务不一样,但是交接的模式大致相同,假设只有客户名单、业务进度两项内容。那么统一开个会就好了,参数实际上只有100*2=200个,是以前的五十万分之一。
下图展示了BPNN全连接和CNN局部连接的区别,假如图形是1000*1000,有1百万个隐藏神经元,那么BPNN需要1000*1000*1000000=10^12个权重,即10^12个参数,而CNN里每个隐藏层神经元负责100个上一层神经元,并且这100个权重的值是共用的,那么实际只有这100个参数

以上只是对卷积感性的认识,即卷积更适合处理图像、区域这种二维矩阵问题,好处有两个:更高效、参数大大减小。
下面介绍卷积的具体实现方式,从两个方面理解:计算方法与训练结果。希望大家理解其他神经网络也从这两个方面理解,第一是冷冰冰的计算方法,第二是依照这种计算方法,输入大量样本训练收敛以后,神经网络里部件所代表的实际意义。就像仿生学一样,所有部件实际都有生物学意义。
①从计算方法上观察,卷积运算并无神秘之处(记得高数中也有卷积的概念),例如原始图像大小是7*7,卷积核大小是3*3,首先卷积核与原始图像左上角前三行前三列对应位置数字相乘求和,得到一个数作为最终结果矩阵的第一行第一列,然后卷积核向右移动一个单位,与原始图像前三行第2、3、4列对应位置数字相乘求和,得到一个数作为最终结果矩阵的第一行第二列,以此类推。想象成一个放大镜在一个报纸上从上往下、从左往右扫描,每次扫描都得到一个结果,最终会得到一个矩阵。
有个动图很好地展示了这个过程http://cs231n.github.io/assets/conv-demo/index.html
动图在原始矩阵周围加了一圈0作为pad,不影响理解。原始图像是三个通道(RGB),这里有两个3*3卷积核,分别是Filter W0和Filter W1,每个卷积核都有对应的三个通道,因此每个卷积核是3*3*3的张量。不同通道的卷积核与对应通道的原始图像做卷积,三个通道相加作为最终矩阵的值。每个卷积核都会生成一个矩阵,这里也叫特征平面。再经过激活函数如ReLU即可传到下一层。
②从训练结果上分析,如果将大量图片作为训练集,最终卷积核会训练成提取的特征,例如识别汽车,那么卷积核可能是车身,可能是轮胎的形状等,卷积核与原始图像做卷积操作,那么符合卷积核特征的部分,得到的结果也比较大。
例如卷积核被训练成老鼠的背侧(黄框所示的曲线)
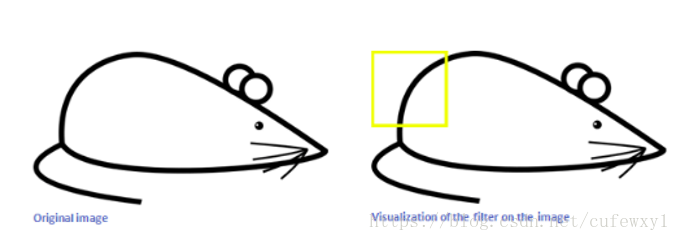
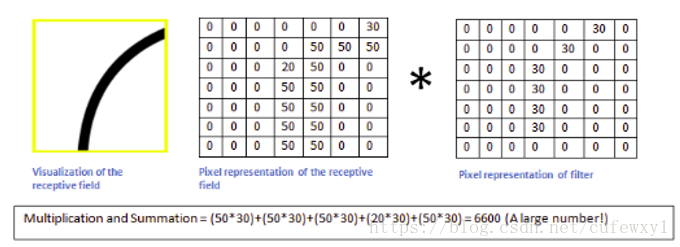
当卷积核移动到对应位置的时候,得到卷积的结果是很大的
反之当卷积核移动到鼠头的位置,卷积结果就很小了
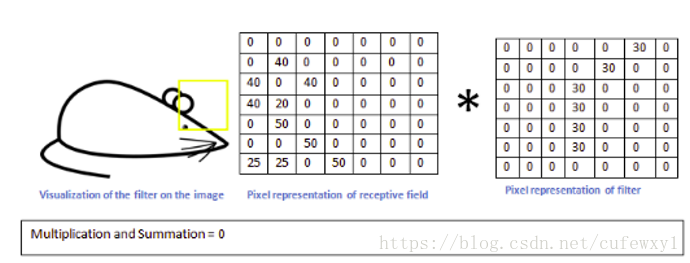
因此符合卷积核特征的区域,值比较大,经过激活函数往下一层传播;而不符合卷积特征的区域,值比较小,往下传播的程度就有限了。卷积后的结果很好地表征了符合特征的程度,这也是为什么卷积后得到的矩阵被称为特征平面的原因。
从训练结果上也能解释卷积要设置权重共享机制的原因——比如要识别一个曲线的特征,那么不管在图像的什么位置,只要扫描到有这个特征就好了。正如用放大镜看报,只用一个放大镜就好了,在报纸不同区域使用不同放大镜是没必要的。
此外,可以将卷积操作的输入输出展开,以更好理解卷积操作的高效性。想象一个矩阵,例如4*4的输入,卷积核为3*3,输出是2*2的矩阵。

将4*4矩阵展开为16维向量,输出矩阵展开为4维向量,如(x00,x01,x02,x03,x10,x11,x12,x13,x20,x21,x22,x23,x30,x31,x32,x33)
那么卷积实际上是这样的稀疏矩阵

将上面的矩阵与向量转置相乘,得到四个数。
第一项为w00*x00+w01*x01+w02*x02+w10*x10+w11*x11+w12*x12+w20*x20+w21*x21+w22*x22,这正是卷积操作的第一个值。同理,第二、三、四项结果也是一致的。
可以看到上边的矩阵有很多0,是很稀疏的,这就是卷积操作高效计算的秘密。
参考资料:
1. https://www.zhihu.com/question/39022858/answer/194996805
2. http://cs231n.github.io/assets/conv-demo/index.html
3. https://www.zhihu.com/question/52668301

















 6101
6101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









