







MNIST数据集
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片,每一张图片对应一个label(即该图片中的数字)。
MNIST的训练数据集(mnist.train)有60000张图片,测试数据集有10000张图片。每一张图片包含28X28个像素点,可以通过一个长度为28x28 = 784的数组来表示这张图片:

MNIST数据集的下载地址 ,其中包含四个文件,分别是train-labels-idx1-ubyte, train-images-idx3-ubyte, t10k-images-idx3-ubyte, t10k-images-idx3-ubyte .数据格式如下:
TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
#The labels values are 0 to 9.
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
#Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).
TEST SET LABEL FILE (t10k-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 10000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
#The labels values are 0 to 9.
TEST SET IMAGE FILE (t10k-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 10000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
#Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).数据下载与预处理
数据预处理过程把训练集图片转化成一个 [55000, 784]的矩阵,其中55000表示图片个数,784表示每个图片的28*28维像素,将[0, 255]像素值转化到[0, 1]区间,如下图所示。

训练集label用一个 [55000, 10]的矩阵表示,每一个label对应一个10维的one hot vector,label对应维的元素值是1,其余为0。 如下图所示,例如label=3 可用 [0,0,0,1,0,0,0,0,0,0]表示.
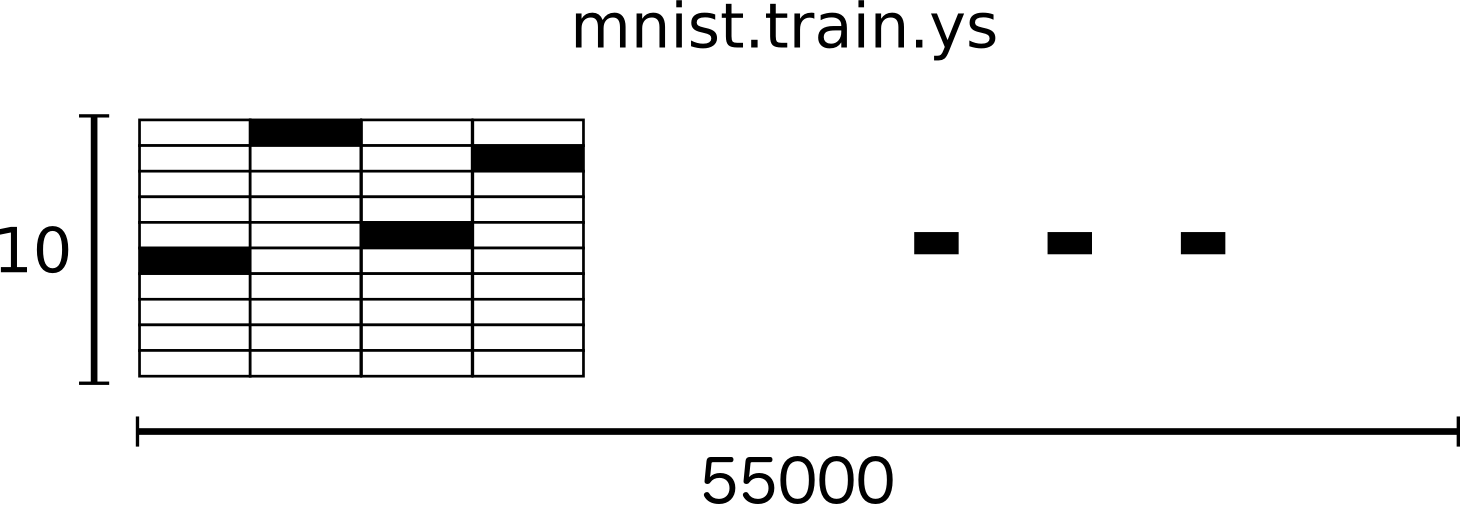
同理,测试集图片用一个 [10000, 784]矩阵表示,测试集label用一个 [10000, 10]矩阵表示
通过如下python源代码可以自动下载和安装这个数据集, 代码下载地址
# input_data.py
#!/usr/bin/env python
"""Functions for downloading and reading MNIST data."""
import gzip
import os
from six.moves.urllib.request import urlretrieve
import numpy
SOURCE_URL = 'http://yann.lecun.com/exdb/mnist/'
def maybe_download(filename, work_directory):
"""Download the data from Yann's website, unless it's already here."""
if not os.path.exists(work_directory):
os.mkdir(work_directory)
filepath = os.path.join(work_directory, filename)
if not os.path.exists(filepath):
filepath, _ = urlretrieve(SOURCE_URL + filename, filepath)
statinfo = os.stat(filepath)
print('Succesfully downloaded', filename, statinfo.st_size, 'bytes.')
return filepath
def _read32(bytestream):
dt = numpy.dtype(numpy.uint32).newbyteorder('>')
return numpy.frombuffer(bytestream.read(4), dtype=dt)
def extract_images(filename):
"""Extract the images into a 4D uint8 numpy array [index, y, x, depth]."""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
magic = _read32(bytestream) #读取前四个字节所表示的magic number
if magic != 2051: #图片文件的magic number = 2051
raise ValueError(
'Invalid magic number %d in MNIST image file: %s' %
(magic, filename))
num_images = _read32(bytestream) #读取接下来4个字节作为图片数目.[60000] for train,[10000] for test
#每一张图片包含28X28个像素点,即rows=[28],cols=[28]
rows = _read32(bytestream)
cols = _read32(bytestream)
buf = bytestream.read(rows * cols * num_images)
data = numpy.frombuffer(buf, dtype=numpy.uint8) #将buf转化为1维数组
data = data.reshape(num_images, rows, cols, 1) #改变数组形状:(60000, 28, 28, 1)for train, (10000, 28, 28, 1)for test
return data
def dense_to_one_hot(labels_dense, num_classes=10):
"""Convert class labels from scalars to one-hot vectors."""
num_labels = labels_dense.shape[0]
index_offset = numpy.arange(num_labels) * num_classes
labels_one_hot = numpy.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
def extract_labels(filename, one_hot=False):
"""Extract the labels into a 1D uint8 numpy array [index]."""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
magic = _read32(bytestream) #读取前四个字节所表示的magic number
if magic != 2049: #label文件的magic number = 2049
raise ValueError(
'Invalid magic number %d in MNIST label file: %s' %
(magic, filename))
num_items = _read32(bytestream) #读取接下来4个字节作为label数目.[60000] for train,[10000] for test
buf = bytestream.read(num_items)
labels = numpy.frombuffer(buf, dtype=numpy.uint8)
if one_hot:
return dense_to_one_hot(labels) #转化为one_hot形式,即每个label由一个10维向量表示,label对应的维度为1,其余为0
return labels
class DataSet(object):
def __init__(self, images, labels, fake_data=False):
if fake_data:
self._num_examples = 10000
else:
assert images.shape[0] == labels.shape[0], (
"images.shape: %s labels.shape: %s" % (images.shape,
labels.shape))
self._num_examples = images.shape[0]
# Convert shape from [num examples, rows, columns, depth]
# to [num examples, rows*columns] (assuming depth == 1)
assert images.shape[3] == 1
images = images.reshape(images.shape[0],
images.shape[1] * images.shape[2]) #把28*28的数组展开成一个28x28 = 784维向量
# Convert from [0, 255] -> [0.0, 1.0].
images = images.astype(numpy.float32)
images = numpy.multiply(images, 1.0 / 255.0) #将像素值转化到[0.0, 1.0]
self._images = images
self._labels = labels
self._epochs_completed = 0
self._index_in_epoch = 0
@property
def images(self):
return self._images
@property
def labels(self):
return self._labels
@property
def num_examples(self):
return self._num_examples
@property
def epochs_completed(self):
return self._epochs_completed
def next_batch(self, batch_size, fake_data=False):
"""Return the next `batch_size` examples from this data set."""
if fake_data:
fake_image = [1.0 for _ in xrange(784)]
fake_label = 0
return [fake_image for _ in xrange(batch_size)], [
fake_label for _ in xrange(batch_size)]
start = self._index_in_epoch
self._index_in_epoch += batch_size
if self._index_in_epoch > self._num_examples:
# Finished epoch
self._epochs_completed += 1
# Shuffle the data
perm = numpy.arange(self._num_examples)
numpy.random.shuffle(perm)
self._images = self._images[perm]
self._labels = self._labels[perm]
# Start next epoch
start = 0
self._index_in_epoch = batch_size
assert batch_size <= self._num_examples
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
def read_data_sets(train_dir, fake_data=False, one_hot=False):
class DataSets(object):
pass
data_sets = DataSets()
if fake_data:
data_sets.train = DataSet([], [], fake_data=True)
data_sets.validation = DataSet([], [], fake_data=True)
data_sets.test = DataSet([], [], fake_data=True)
return data_sets
TRAIN_IMAGES = 'train-images-idx3-ubyte.gz' #训练集图像的文件名
TRAIN_LABELS = 'train-labels-idx1-ubyte.gz' #训练集label的文件名
TEST_IMAGES = 't10k-images-idx3-ubyte.gz' #测试集图像的文件名
TEST_LABELS = 't10k-labels-idx1-ubyte.gz' #测试集label的文件名
VALIDATION_SIZE = 5000
local_file = maybe_download(TRAIN_IMAGES, train_dir) #下载训练集的图像,返回图像文件所在目录
train_images = extract_images(local_file)
local_file = maybe_download(TRAIN_LABELS, train_dir) #下载训练集的label
train_labels = extract_labels(local_file, one_hot=one_hot)
local_file = maybe_download(TEST_IMAGES, train_dir) #下载测试集的图像,返回图像文件所在目录
test_images = extract_images(local_file)
local_file = maybe_download(TEST_LABELS, train_dir) #下载测试集的label
test_labels = extract_labels(local_file, one_hot=one_hot)
#取训练集中的前5000张图片作为验证集
validation_images = train_images[:VALIDATION_SIZE]
validation_labels = train_labels[:VALIDATION_SIZE]
train_images = train_images[VALIDATION_SIZE:]
train_labels = train_labels[VALIDATION_SIZE:]
data_sets.train = DataSet(train_images, train_labels)
data_sets.validation = DataSet(validation_images, validation_labels)
data_sets.test = DataSet(test_images, test_labels)
return data_setssoftmax简介
在 softmax回归中,我们解决的是多分类问题(相对于 logistic 回归解决的二分类问题),y 可以取 k 个不同的值(而不是 2 个)。因此,对于训练集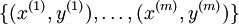
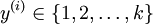
对于给定的测试输入 x,我们想用假设函数针对每一个类别j估算出概率值 p(y=j | x)。也就是说,我们想估计 x 的每一种分类结果出现的概率。因此,我们的假设函数将要输出一个 k 维的向量(向量元素的和为1)来表示这 k 个估计的概率值。 具体地说,我们的假设函数 h_{θ}(x) 形式如下:
其中,

为了方便起见,我们同样使用符号 θ 来表示全部的模型参数。在实现Softmax回归时,将 θ用一个 k ×(n+1) 的矩阵来表示会很方便,该矩阵是将 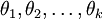
θ =
关于softmax的详细介绍
手写数字识别
参数训练时,需要将input_data.py与以下代码放在同一目录下
需要说明的是,本文的softmax模型仅计算x与θ的内积,并没有把其当成幂指数求值
模型训练和预测代码如下:
#!/usr/bin/env python
import tensorflow as tf
import numpy as np
import input_data
def init_weights(shape):
return tf.Variable(tf.random_normal(shape, stddev=0.01))
def model(X, w):
return tf.matmul(X, w) # notice we use the same model as linear regression, this is because there is a baked in cost function which performs softmax and cross entropy
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #读入数据
#mnist.train.images是一个55000 * 784维的矩阵, mnist.train.labels是一个55000 * 10维的矩阵
trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
X = tf.placeholder("float", [None, 784]) # create symbolic variables
Y = tf.placeholder("float", [None, 10])
w = init_weights([784, 10]) # 模型权重
py_x = model(X, w)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(py_x, Y)) # 计算py_x与Y的交叉熵
train_op = tf.train.GradientDescentOptimizer(0.05).minimize(cost) #通过步长为0.05的梯度下降算法求参数
predict_op = tf.argmax(py_x, 1) # 预测阶段,返回py_x中值最大的index
# Launch the graph in a session
with tf.Session() as sess:
# you need to initialize all variables
tf.initialize_all_variables().run()
for i in range(100):
for start, end in zip(range(0, len(trX), 128), range(128, len(trX)+1, 128)):#minibatch,每128个数据为一个batch
sess.run(train_op, feed_dict={X: trX[start:end], Y: trY[start:end]})
#test
print(i, np.mean(np.argmax(teY, axis=1) ==
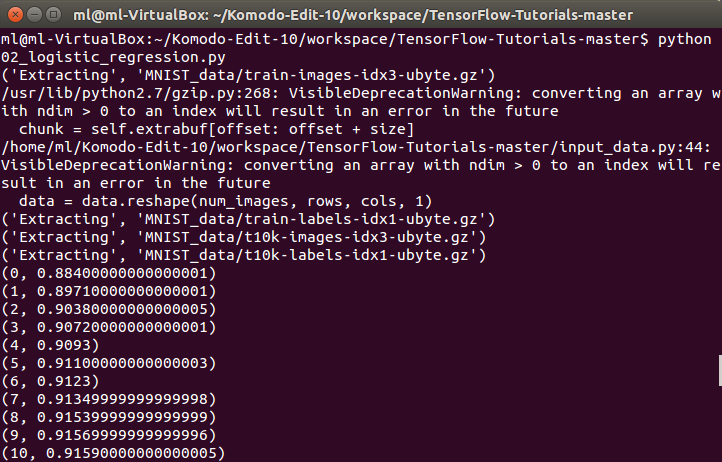
sess.run(predict_op, feed_dict={X: teX})))进行100轮迭代训练,每轮训练结束后,在测试集验证当前模型对数字识别的准确率,程序运行结果如下图,
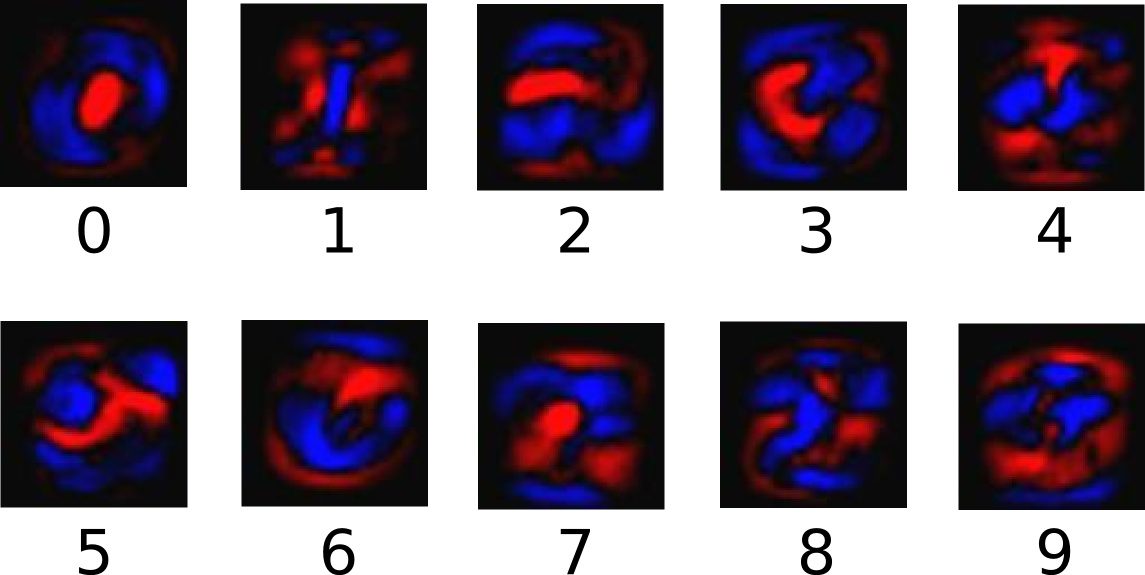
官网文档中的这张图非常直观的展示了参数训练的结果。每张图像可看作一个28×28的参数矩阵,其中红色区域代表负数权值,蓝色区域代表正数权值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









