Autoencoder
autoencoder是一种无监督的学习算法,主要用于数据的降维或者特征的抽取,在深度学习中,autoencoder可用于在训练阶段开始前,确定权重矩阵
W
的初始值。
神经网络中的权重矩阵W可看作是对输入的数据进行特征转换,即先将数据编码为另一种形式,然后在此基础上进行一系列学习。然而,在对权重初始化时,我们并不知道初始的权重值在训练时会起到怎样的作用,也不知道在训练过程中权重会怎样的变化。因此一种较好的思路是,利用初始化生成的权重矩阵进行编码时,我们希望编码后的数据能够较好的保留原始数据的主要特征。那么,如何衡量码后的数据是否保留了较完整的信息呢?答案是:如果编码后的数据能够较为容易地通过解码恢复成原始数据,我们则认为
W
较好的保留了数据信息。
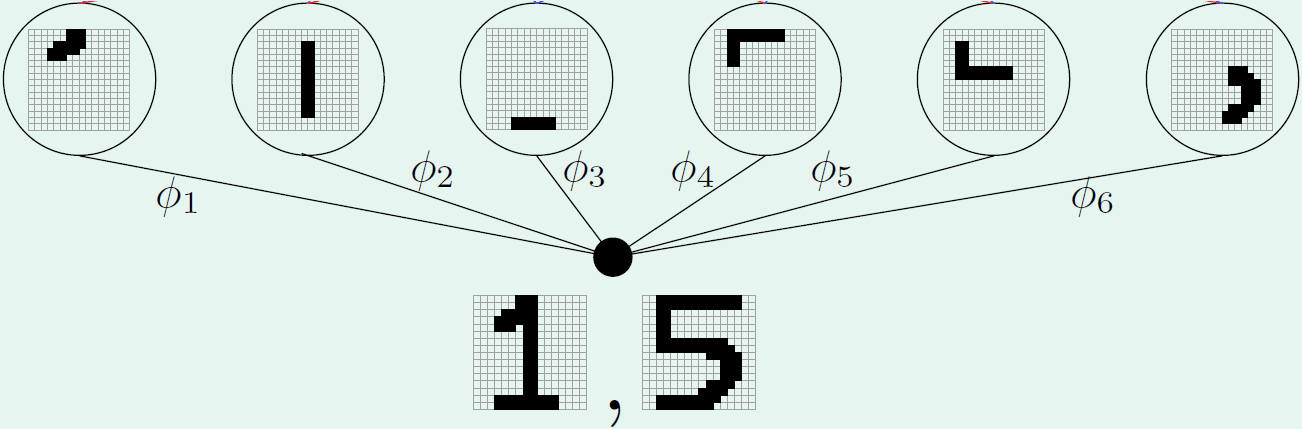
例如下图所示,将手写数字图片进行编码,编码后生成的 ϕ1,
ϕ2
,
ϕ3
,
ϕ4
,
ϕ5
,
ϕ6
较完整的保留了原始图像的典型特征,因此可较容易地通过解码恢复出原始图像。
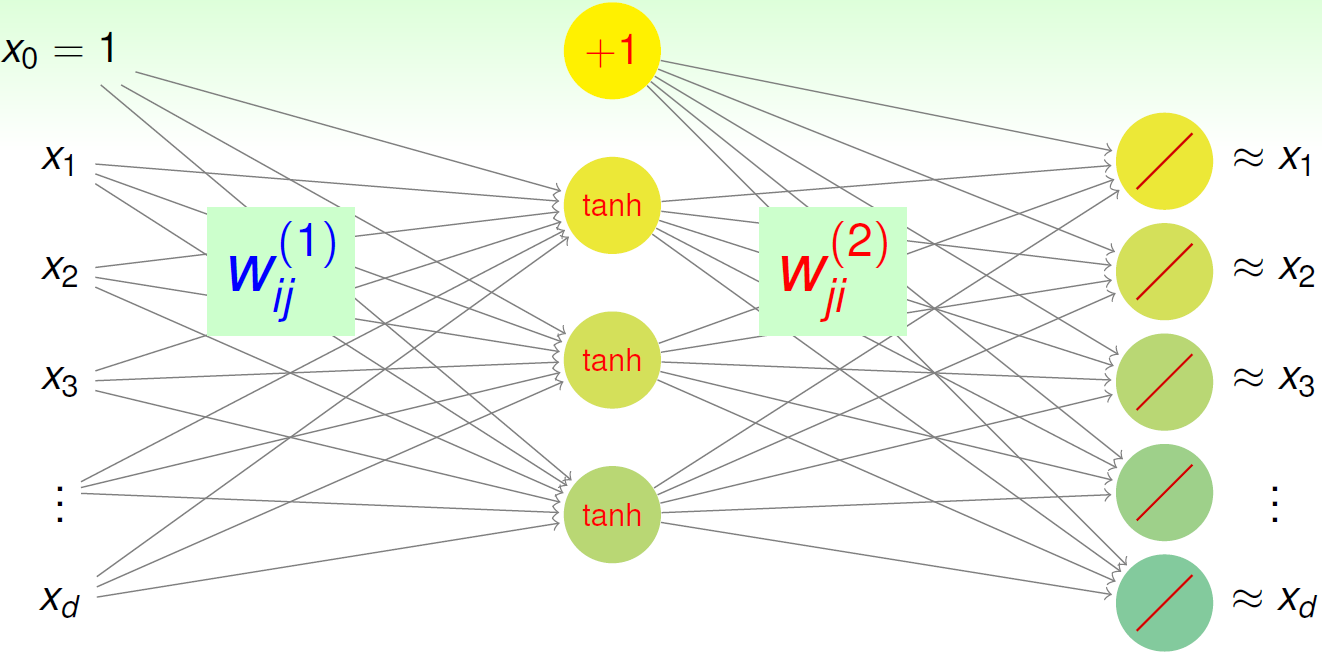
autoencoder通过神经网络进行预训练,从而确定
W
的初始值。其目标是让输入值等于输出值。如下图所示:首先用W对输入进行编码,经过激活函数后,再用
WT
进行解码,从而使得
h(x)≈x
。该过程可以看作是对输入数据的压缩编码,将高维的原始数据用低维的向量表示,使压缩后的低维向量能保留输入数据的典型特征,从而能够较为方便的恢复原始数据。需要注意的是:这里增加了一个约束条件,即在对数据进行编码和解码时,使用的是同一个参数矩阵
W
<script type="math/tex" id="MathJax-Element-98">W</script>。该约束可看作是一种regularization,用于减少参数的个数,控制模型的复杂度。
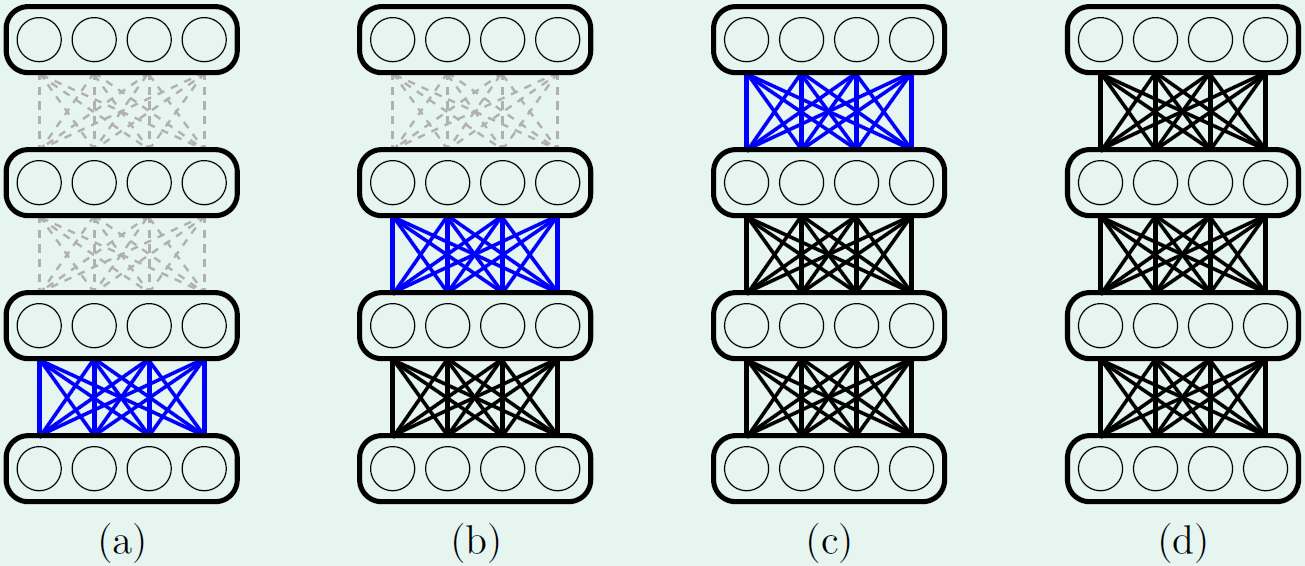
对于多层神经网络的参数初始化问题,我们可以依次对每一层进行autoencoder。如下图所示,具体做法是首先按照上述方法确定第一层的权重参数,然后固定第一层的参数,对第二层的参数进行训练,以此类推,直到得到所有权重值。























 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









