







上篇博文访问的网络资源是我新建的简单的index.jsp页面,实际工作中我们常常会访问一些网站的资源,比如在一些网站爬虫一些数据等。
本篇博文就简单访问一个博客吧,看看有什么问题。按照我们上一篇博文的介绍,写出下面的代码:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.zip.GZIPInputStream;
import java.io.*;
public class TestURLConnection1 {
public static void main(String[] args) {
StringBuffer strBuffer = new StringBuffer();
HttpURLConnection httpURLConnection = null;
InputStream inputStream = null;
BufferedReader rufferedReader = null;
try {
URL serverUrl = new URL("http://blog.csdn.net/u010248330/article/details/68926199");
httpURLConnection = (HttpURLConnection) serverUrl.openConnection();
System.out.println("请求url的响应状态码:"+httpURLConnection.getResponseCode());
//状态码200是请求成功
if (HttpURLConnection.HTTP_OK == httpURLConnection.getResponseCode()) {
inputStream = httpURLConnection.getInputStream();
rufferedReader = new BufferedReader(new InputStreamReader(
inputStream,"utf-8"));
String str = null;
while ((str = rufferedReader.readLine()) != null) {
strBuffer.append(str);
strBuffer.append("\r\n");
}
System.out.println(strBuffer);
}
}catch(Exception e) {
e.printStackTrace();
}finally{
httpURLConnection.disconnect();
//这里把相关的流也关闭吧,我这里就不写了
}
}
}
实验结果:

我们看到返回的状态码是403,访问被禁止了,说明服务器不允许我们的访问,这是怎么回事呢?
我们用浏览器去访问这个博客地址,看看相关的网络信息,主要关注请求的头信息。
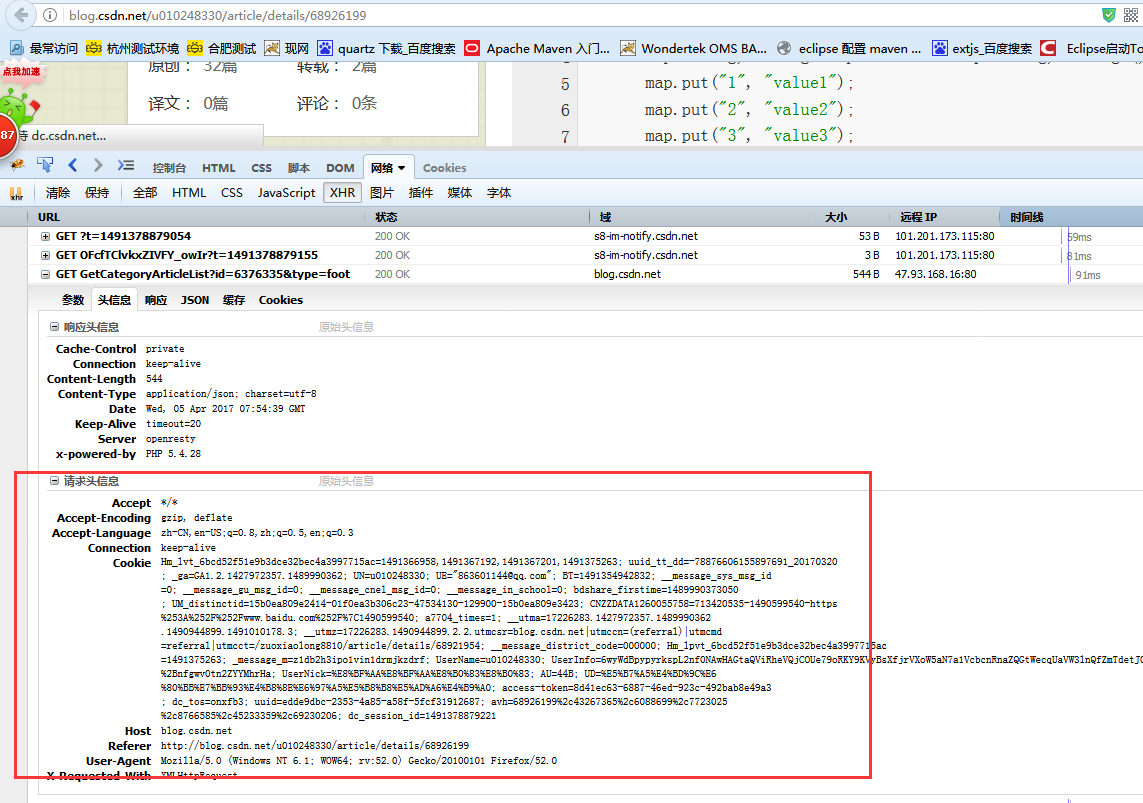
从上面图我们应该知道了问题的所在了,这说明我们代码中没有设置相关的请求头信息,博客那边的服务器拒绝了我们的请求,现在我们在代码中利用上一篇博客介绍的方法设置相关的请求头信息看一下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.zip.GZIPInputStream;
import java.io.*;
public class TestURLConnection2 {
public static void main(String[] args) {
StringBuffer strBuffer = new StringBuffer();
HttpURLConnection httpURLConnection = null;
InputStream inputStream = null;
BufferedReader rufferedReader = null;
try {
URL serverUrl = new URL("http://blog.csdn.net/u010248330/article/details/68926199");
httpURLConnection = (HttpURLConnection) serverUrl.openConnection();
//设置请求的头信息
httpURLConnection.setRequestProperty("Accept-charset", "utf-8");
httpURLConnection.setRequestProperty("Accept", "text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01");
httpURLConnection.setRequestProperty("Accept-Encoding", "gzip, deflate");
httpURLConnection.setRequestProperty("Accept-Language", "zh-CN,en-US;q=0.8,zh;q=0.5,en;q=0.3");
httpURLConnection.setRequestProperty("Connection","keep-alive");
httpURLConnection.setRequestProperty("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0");
System.out.println("请求url的响应状态码:"+httpURLConnection.getResponseCode());
//状态码200是请求成功
if (HttpURLConnection.HTTP_OK == httpURLConnection.getResponseCode()) {
inputStream = httpURLConnection.getInputStream();
rufferedReader = new BufferedReader(new InputStreamReader(
inputStream,"utf-8"));
String str = null;
while ((str = rufferedReader.readLine()) != null) {
strBuffer.append(str);
strBuffer.append("\r\n");
}
System.out.println(strBuffer);
}
}catch(Exception e) {
e.printStackTrace();
}finally{
httpURLConnection.disconnect();
//这里把相关的流也关闭吧,我这里就不写了
}
}
}
再看输出结果:

从上的图可以看出,对于我们的url请求,服务器是给我们返回了数据,那怎么都乱码了呢?
我们打印一下响应的内容的编码信息:System.out.println("服务器响应的内容的编码格式:"+httpURLConnection.getContentEncoding());我们可以看到编码格式是gzip格式,而我们只是用inputStream流去接收数据,并没有解码,所以导致了上面出现的乱码,那怎么解决呢?
我们在java.util.zip包下有一个类GZIPInputStream,可用于解码:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.zip.GZIPInputStream;
import java.io.*;
public class TestURLConnection3 {
public static void main(String[] args) {
StringBuffer strBuffer = new StringBuffer();
HttpURLConnection httpURLConnection = null;
InputStream inputStream = null;
BufferedReader rufferedReader = null;
//用于解码
GZIPInputStream gzin = null;
try {
URL serverUrl = new URL("http://blog.csdn.net/u010248330/article/details/68926199");
httpURLConnection = (HttpURLConnection) serverUrl.openConnection();
//设置请求的头信息
httpURLConnection.setRequestProperty("Accept-charset", "utf-8");
httpURLConnection.setRequestProperty("Accept", "text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01");
httpURLConnection.setRequestProperty("Accept-Encoding", "gzip, deflate");
httpURLConnection.setRequestProperty("Accept-Language", "zh-CN,en-US;q=0.8,zh;q=0.5,en;q=0.3");
httpURLConnection.setRequestProperty("Connection","keep-alive");
httpURLConnection.setRequestProperty("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0");
System.out.println("请求url的响应状态码:"+httpURLConnection.getResponseCode());
//状态码200是请求成功
if (HttpURLConnection.HTTP_OK == httpURLConnection.getResponseCode()) {
inputStream = httpURLConnection.getInputStream();
System.out.println("服务器响应的内容的编码格式:"+httpURLConnection.getContentEncoding());
//转码
gzin = new GZIPInputStream(inputStream);
rufferedReader = new BufferedReader(new InputStreamReader(
gzin,"utf-8"));
String str = null;
while ((str = rufferedReader.readLine()) != null) {
strBuffer.append(str);
strBuffer.append("\r\n");
}
System.out.println(strBuffer);
}
}catch(Exception e) {
e.printStackTrace();
}finally{
httpURLConnection.disconnect();
//这里把相关的流也关闭吧,我这里就不写了
}
}
}
实验结果:

这下就完美解决这个问题了。当然我们可以在代码中这样判断一下,再作转换,这样更严谨:
if (httpURLConnection.getContentEncoding().equals("gzip"))
在这里我就不改了。














 4170
4170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









