







共享存储器(shared memory)是可以被同一个线程块中所有线程访问的可读写存储器,生存期是线程块的生命期。
下面有矩阵乘法来说明共享存储器的相关知识。
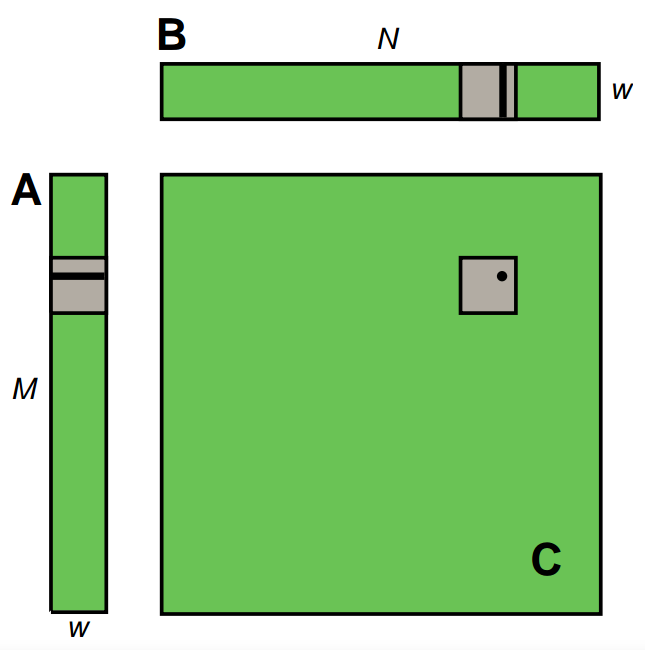
算法:矩阵A的高度为M,宽度为w。矩阵B的高度为w,宽度为N。矩阵C的高度为M,宽度为N。实现C=A×B的矩阵相乘。为了简化问题,我们将w取32,M和N取32的整数倍。
分配资源:
dim3 dimBlock(BLOCK_SIZE,BLOCK_SIZE);
dim3 dimGrid(N/dimBlock.x,M/dimBlock.y);
未优化的核函数:
__global__ void simpleMultiply(float* a,float* b,float* c,int N){
int row=blockIdx.y*blockDim.y+threadIdx.y;
int col=blockIdx.x*blockDim.x+threadIdx.x;
float sum=0.0f;
for(int i=0;i<TILE_DIM;i++){
sum+=a[row*TILE_DIM+i]*b[i*N+col];
}
c[row*N+col]=sum;
}优化后的核函数:
__global__ void coalescedMultiply(float* a,float* b,float* c,int N){
__shared__ float aTile[TILE_DIM][TILE_DIM],bTILE[TILE_DIM][TILE_DIM];
int row=blockIdx.y*blockDim.y+threadIdx.y;
int col=blockIdx.x*blockDim.x+threadIdx.x;
float sum=0.0f;
aTILE[threadIdx.y][threadIdx.x]=a[row*TILE_DIM+threadIdx.x];
bTILE[threadIdx.y][threadIdx.x]=b[threadIdx.y*N+col];
__syncthreads();
for(int i=0;i<TILE_DIM;i++){
sum+=aTile[threadIdx.y][i]*bTile[i][threadIdx.x];
}
c[row*N+col]=sum;
}














 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









