







 本文介绍了如何在CUDA中通过TILE分块和shared memory技术实现矩阵乘法,通过代码示例展示并行计算过程,并验证了结果与MATLAB计算的一致性。
本文介绍了如何在CUDA中通过TILE分块和shared memory技术实现矩阵乘法,通过代码示例展示并行计算过程,并验证了结果与MATLAB计算的一致性。
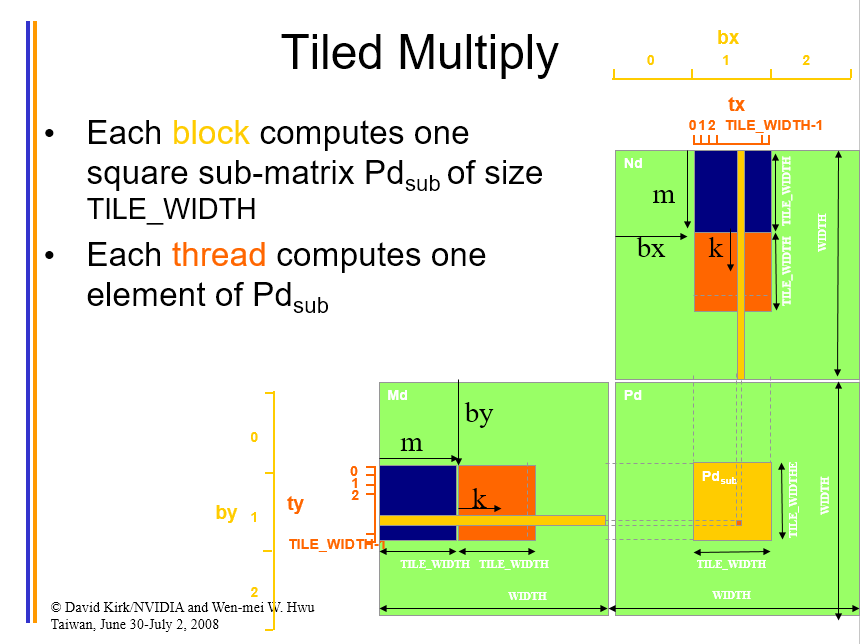
CUDA 矩阵乘法
将输入数据分成很多个TILE使用shared memory进行并行计算
代码
#include "device_functions.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
typedef struct {
int width;
int height;
int stride;
float* elements;
} Matrix;
#define BLOCK_SIZE 16
#define N 3072
__device__ float GetElement(const Matrix A, int row, int col) {
return A.elements[row * A.stride + col];
}
__device__ void SetElement(Matrix A, int row, int col, float value) {
A.elements[row * A.stride + col] = value;
}
__device__ Matrix GetSubMatrix(Matrix A, int row, int co 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4140
4140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









