










0.概述
决策树(decision tree)是一种基本的分类与回归方法。
主要优点:模型具有可读性,分类速度快。
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。
1.决策树模型与学习
节点:根节点、子节点;内部节点(internal node)和叶节点(leaf node)。
决策树学习本质上是从训练数据集中归纳出一组分类规则。
决策树学习仍然需要将代价函数最小化。
为了防止有过拟合现象,需要对决策图进行修剪。
决策图的生成对应于模型的局部选择,决策树的剪枝则考虑全局最小选择。
2.特征选择
特征选择在于选取对训练数据具有分类能力的特征。可以用一个例子说明:预测波斯顿的房价,把盖房子所用砖头的颜色作为特征,显示是没有意义的!
特征选择的准则是信息增益或信息增益比。
特征有多个,选择哪个决策图更科学呢?答案是:
如果一个特征具有更好的分类能力,或者说,按照这一特征将训练数据集分割成子集,使得各个子集在当前条件下有最好的分类,那么就更应该选择这个特征。信息增益(information gain)就能够很好地表示这一直观的准则。
决策树学习应用信息增益准则选择特征。信息增益大的特征具有更强的分类能力。
特征选择的方法:对训练数据集(或子集)D,计算其每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。
信息增益算法:

例子:

3.决策图的生成
决策树学习的经典算法:ID3、C4.5中的生成算法。
通过实例理解ID3算法:
4.决策树的剪枝
决策树的减枝是为了解决过拟合现象,决策树的剪枝往往通过极小化决策树整体的代价函数来实现。
5.代码
"""
功能:回归决策树
说明:人为设置函数模型为每隔5个点引入噪音的离散的sin(x),我们利用决策树回归拟合这些数据
作者:唐天泽
博客:http://blog.csdn.net/u010837794/article/details/76596063
日期:2017-08-03
"""
"""
导入项目所需的包
"""
import numpy as np
from sklearn.tree import DecisionTreeRegressor
# 使用交叉验证的方法,把数据集分为训练集合测试集
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
def creat_data(n):
'''
产生用于回归问题的数据集
:param n: 数据集容量
:return: 返回一个元组,元素依次为:训练样本集、测试样本集、训练样本集对应的值、测试样本集对应的值
'''
np.random.seed(0)
X = 5 * np.random.rand(n, 1)
y = np.sin(X).ravel()
noise_num=(int)(n/5)
y[::5] += 3 * (0.5 - np.random.rand(noise_num)) # 每第5个样本,就在该样本的值上添加噪音
X_train, X_test, y_train, y_test=train_test_split(X, y,test_size=0.25,random_state=1)
return X_train, X_test, y_train, y_test # 拆分原始数据集为训练集和测试集,其中测试集大小为元素数据集大小的 1/4
# 使用DecisionTreeRegressor考察线性回归决策树的预测能力
def test_DecisionTreeRegressor(X_train, X_test, y_train, y_test):
# 选择模型
cls = DecisionTreeRegressor()
# 把数据交给模型训练
cls.fit(X_train, y_train)
print("Training score:%f" % (cls.score(X_train, y_train)))
print("Testing score:%f" % (cls.score(X_test, y_test)))
"""绘图"""
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
X = np.arange(0.0, 5.0)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
X = np.arange(0.0, 5.0, 0.01)[:, np.newaxis] # X为array([[ 0. ],[ 0.01],...,[4.99]]
Y = cls.predict(X)
# 离散点
ax.scatter(X_train, y_train, label="train sample", c='g')
ax.scatter(X_test, y_test, label="test sample", c='r')
# 连续点
ax.plot(X, Y, label="predict_value", linewidth=2, alpha=0.5)
ax.set_xlabel("data")
ax.set_ylabel("target")
ax.set_title("Decision Tree Regression")
ax.legend(framealpha=0.5)
plt.show()
if __name__=='__main__':
X_train,X_test,y_train,y_test=creat_data(100) # 产生用于回归问题的数据集
test_DecisionTreeRegressor(X_train,X_test,y_train,y_test) # 调用 test_DecisionTreeRegressor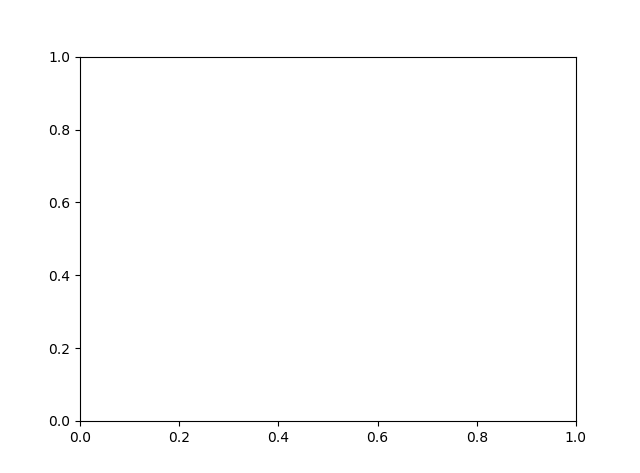
6.参考资料
[1] 李航 《统计学习方法》
[2] 华校专《Python大战机器学习》















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









