







 本实验通过Weka平台对比分析数值型数据和添加标称属性后的分类效果。在纯数值型数据上,多种算法如NN、KNN、Naive Bayes等被测试,而在加入标称属性后,分类准确度普遍提升。Random Forest、C4.5 (J48)、Simple Logistic和Multilayer Perceptron展现出最佳分类性能。
本实验通过Weka平台对比分析数值型数据和添加标称属性后的分类效果。在纯数值型数据上,多种算法如NN、KNN、Naive Bayes等被测试,而在加入标称属性后,分类准确度普遍提升。Random Forest、C4.5 (J48)、Simple Logistic和Multilayer Perceptron展现出最佳分类性能。
本实验是福建矿产分布分类识别实验,使用常用的weka 分类识别算法,第一组实验只使用数据中的数值型数据,第二组实验在数值型特征基础上加上了标称属性分类。
1. 数值型数据在weka 平台上
数值型数据分布
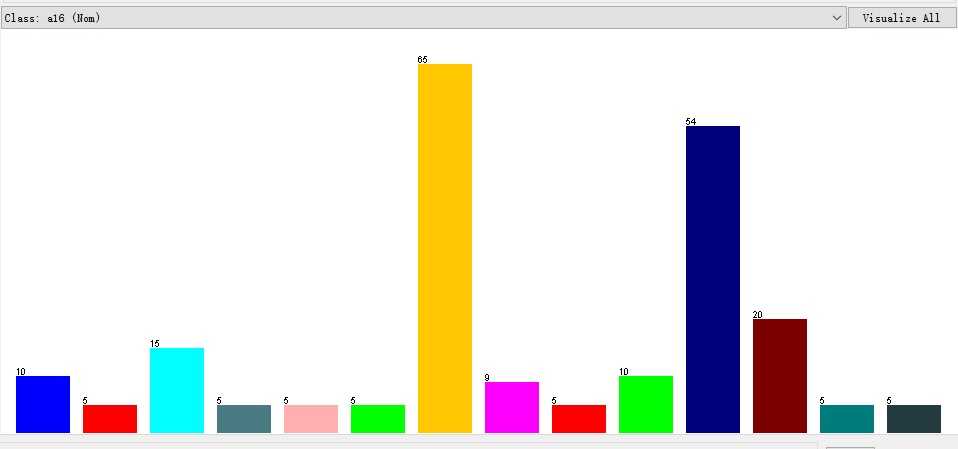
横坐标代表类别数,一共有14类数据,纵坐标代表每类数据的样本个数分布。
在weka中采用多种传统分类方法实验结果
在weka中测试以下常用的分类方法,记录各方法的识别正确率、Kappa系数、均方根误差、相对绝对误差如下表所示:
| 方法名 | weka中对应方法 | Correctly Classified rate | Kappa 系数 | Root mean square error | Relative absolute error |
|---|---|---|---|---|---|
| NN | lazy.IB1 | 38.9908 % | 0.265 | 0.2952 | 73.1243 % |
| 2-NN | lazy.IBk(k=2) | 33.945 % | 0.2066 | 0.2526 | 77.5179 % |
| 3-NN | lazy.IBk(k=3) | 38.5321 % | 0.261 | 0.2424 | 79.9899 % |
| Naive Bayes | bayes.NaiveBayes | 30.2752 % | 0.2109 | 0.2933 | 84.9225 % |
| Bayes Net | bayes.BayesNet | 30.2752 % | 0.0736 | 0.2408 | 97.0716 % |
| Complement Naive Bayes | bayes.ComplementNaiveBayes | 31.1927 % | 0.0885 | 0.3135 | 82.471 % |
| Simple Logistic | functions.SimpleLogistic | 42.6606 % | 0.2699 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6443
6443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









