






Weka是一款机器学习软件,最主要应用是数据挖掘,网上大部分的课程也都是关于如何使用Weka做数据挖掘的。在这里基于一个tweet文本分析地点来介绍一些Weka的入门使用步骤
- 下载 直接google即可,官网下载相应版本。
2. 导入文件
Weka 支持的是 arff 格式的文件,如果不是该格式,一定先转成该格式。点击open file选择自己要使用的文件

3. Preprocess 介绍
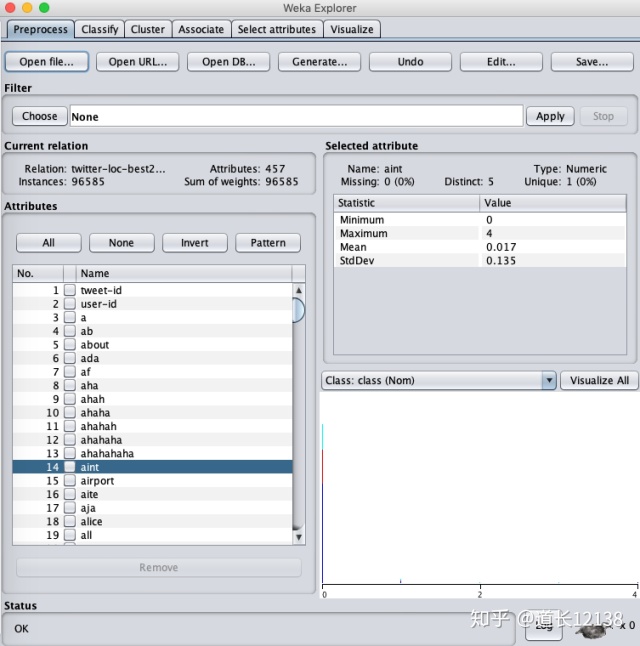
在导入文件之后我们就可以看到Weka的preprocess界面里的一些参数了 如上图
首先是 Attribute 部分,这是根据导入的文件格式自动生成的。在这里面,原来是数字的部分会被认定为值,并在右侧展示该数字的分布。如图,我们选择 tweet-id 作为我们当前的特征可以看到 tweet-id 在整个区间中的分布情况。同时三种不同的颜色分别是代表分的三类(三个地点)
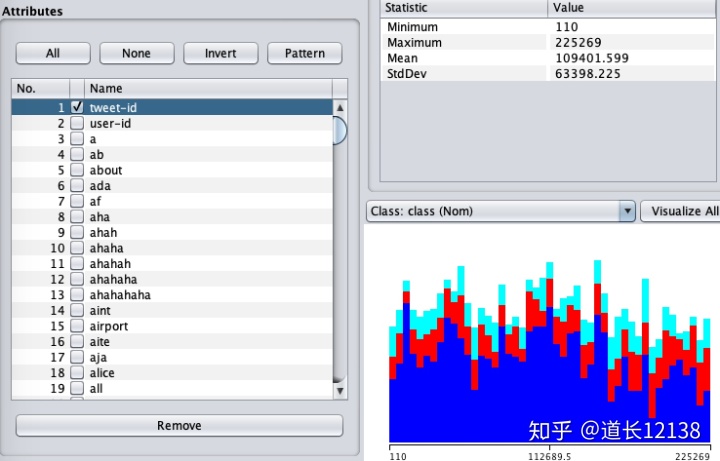
选择一个 class(右侧直方图上方),这个 class 就是我们要做的分类(一般我们在数据集中命名我们的的分类依据为“Class”),本次样例中使用的是三个地点。
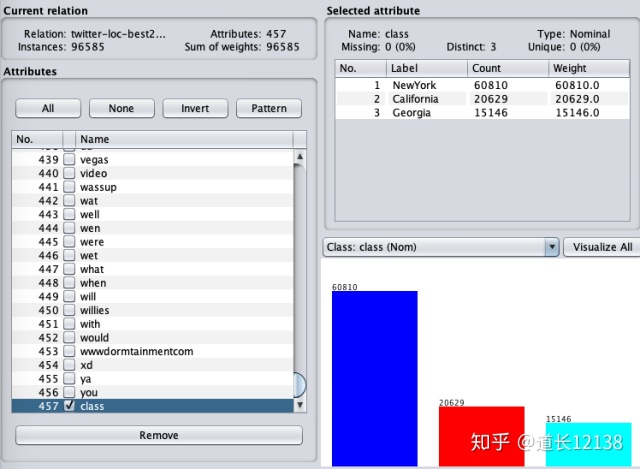
此外,由于我们是对文本进行分析,文本中的单词也被提取出来作为特征。文本中包含这个单词的数量就是这个特征的值。这里我们并没有将所有的单词提取出来作为特征,只是在文本中提前设定好了,出现频率最多的单词 Top n(most) 或者相关信息度 Top n(best),并可以通过数据文件名来区分。
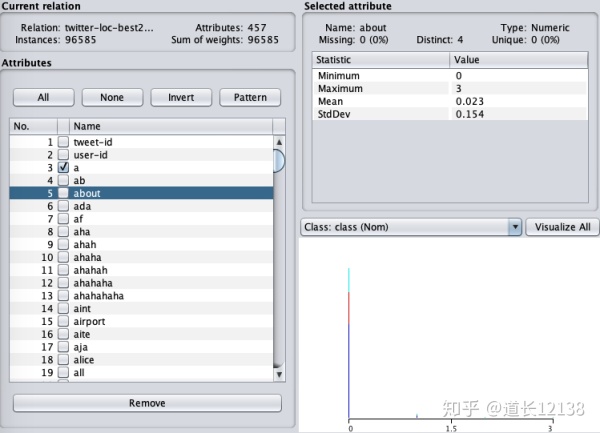
另外,我们可以通过点击 Edit 来查看全部的数据

4 Classify
首先我们进入 Classify 并点击 choose 选择一个模型,这里我们首先使用 ZeroR来实验一下

然后我们在 Test Options 这一部分可以选择本次的分类依据,注意,并不是所有的模型都可以选择所有类别作为分类依据,这里 ZeroR 是可以根据 nom 分类的。
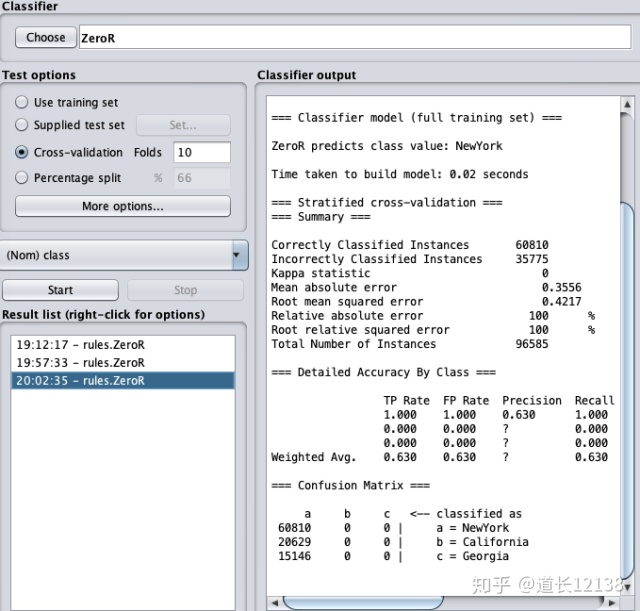
我们可以先简单的看一下结果。第一次测试中,显然把所有的样例都划分到 New York 这一类别里了,所以导致另外两项的准确率都为 0.
在下一次的学习计划中我们将继续学习分类及各种模型,并将这些模型应用到weka上,得到我们想要的结果。















 3661
3661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









