







16年北航的一篇论文 : Topic Modeling of Short Texts: A Pseudo-Document View
看大这篇论文想到了上次面腾讯的时候小哥哥问我短文档要怎么聚类或者分类。当时一脸懵逼。
short texts : 短文本,一般指的是文档的平均单词数量比较小(10左右)的文档这类文档由于co-occurance的单词数目的限制,用普通的主题模型效果不好。
那么要怎么办呢? 生成pseudo-document 即伪文档。
伪文档是真实文档的某种结合,论文里边提到了三个点: topic selectors, smoothing prior, weak smoothing。 举个例子如下:
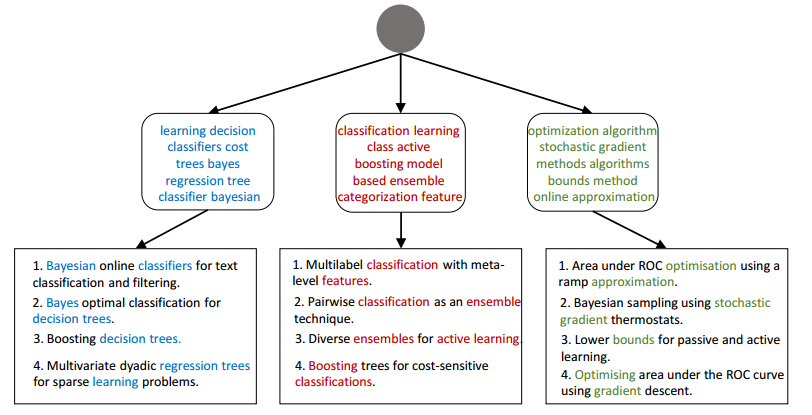
第二层的是pseudo-document , 第三层是原始的文档,平均每个文档的单词数目较少。
pseudo-document 已经生成了,那么主题模型变成什么样子了?
针对每个topic 得到每个topic的分布
针对每个伪文档dl, 得到每个dl的分布
对于短文档ds, 首先找到对应的伪文档l, 再根据dl的分布得到主题topic, 根据主题t的分布得到单词w
pseudo-document 的数量是实验过程中人为指定的,数目对模型的好坏是有一定的影响的。















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









