






http://blog.csdn.net/u011239443/article/details/52015680
github:https://github.com/apache/incubator-carbondata
参考: 陈亮,华为:《Spark+CarbonData(New File Format For Faster Data Analysis)》 http://www.meetup.com/Hangzhou-Apache-Spark-Meetup/events/231071384/
用例和动机:为什么介绍一种新的文件格式?
用例: 顺序扫描
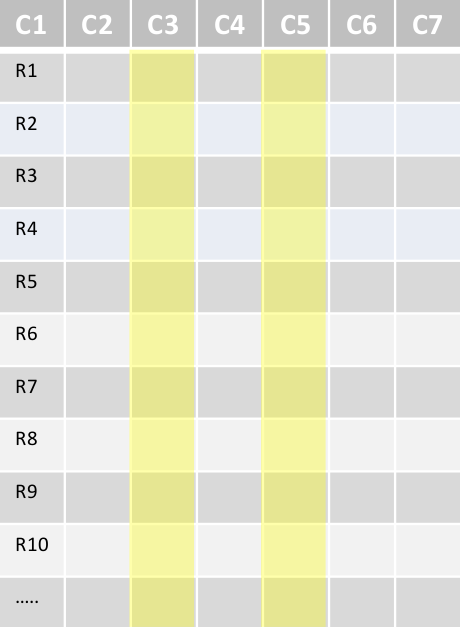
- 全表扫描
- 大扫描(全行, 没过滤)
- 只获取表的几列作为查询结果
- 通常的使用场景:
- ETL工作
- 日志分析
用例:随机访问
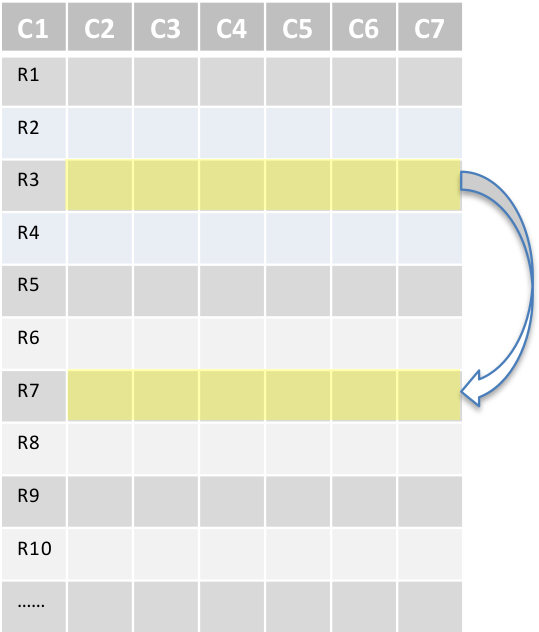
- 在很多列进行过滤(点查询)
- 行键值查询 (比如HBase)
- 窄扫描但可能要获取所以列
- 要求秒/亚秒级别的低延迟
- 通常的使用场景:
- 操作查询
- 用户分析
用例:OLAP类查询
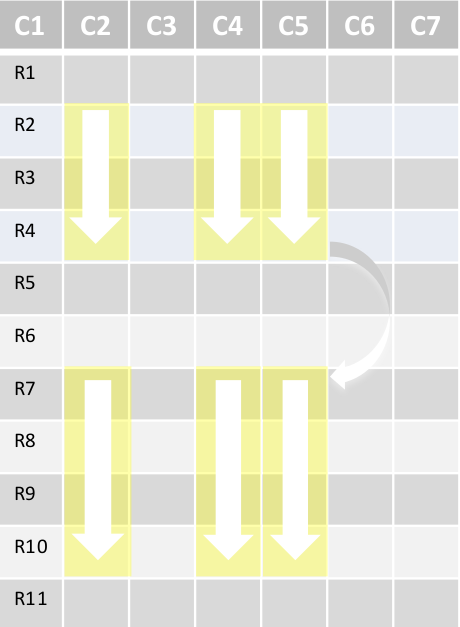
- 任意范围的交互数据分析
- 包括聚合/join
- Roll-up, Drill-down, Slicing and Dicing
- 低延迟的点对点查询
- 通常的使用场景:
- 仪器报表
- 诈骗&点对点分析
动机
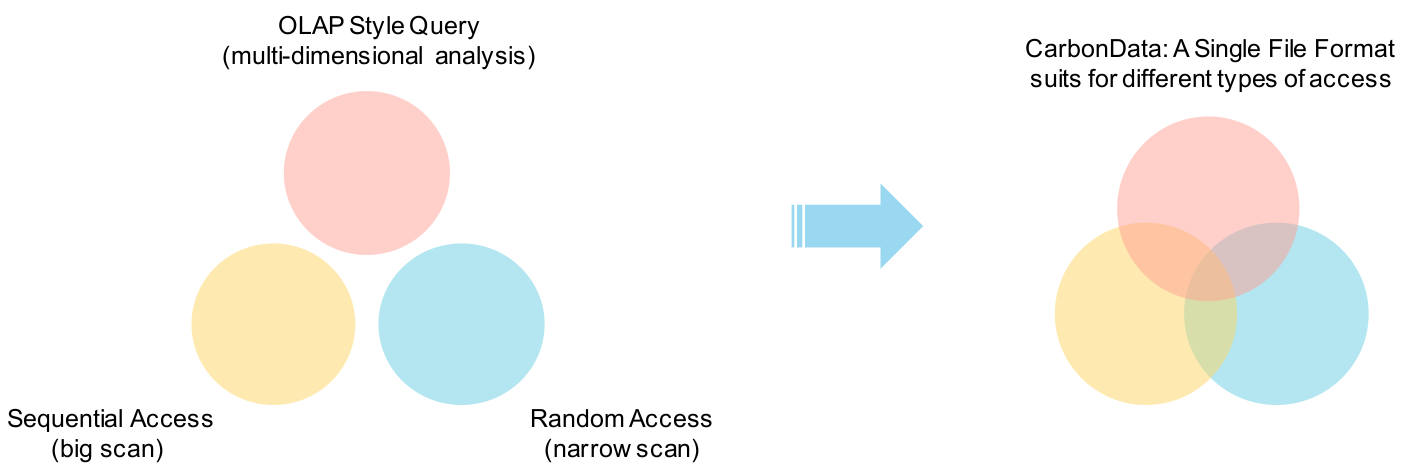
为什么需要CarbonData
基于以下需求,我们研究Hadoop生态系统中现有的文件格式,但是我们不能找到一个同时满足所有需求的合适的方法,所以我们开始设计CarbonData。
- 支持广扫描& 少列结果
- 支持在亚秒级响应主键查找
- 支持大数据上涉及一个查询中有许多过滤的交互OLAP类查询, 并能以秒级响应
- 支持包含全列的单条记录的快速抽取
- 支持HDFS以便用户可以管理正存在的Hadoop集群
当我们研究Parquet/ORC,它们似乎在R1和R5上表现很好,但是对于R2,R3,R4则不然。所以我们设计CarbonData主要增加以下不同的特性:
- 带索引的数据存储:它可以显著的提高查询性能,并且当查询中有过滤条件,可以减少I/O扫描与CPU资源开销。CarbonData索引包括多个级别,处理框架可以通过这个索引来减少它需要调度和处理的任务。它也可以在一个更加高效的单元(叫做blocklet)里面跳跃扫描,而不用扫描整个文件。
- 可操作的编码过的数据:通过支持高效的压缩和全局编码设计,使得可以在已经压缩/编码过的数据上进行查询。数据可以仅当返回结果给用户的时候才修改,即“惰性实现”。
- 列组:允许多列组成一个列组,并以行格式进行存储。这减少了查询时的行重建的开销。
- 用一种数据格式支持多种用例:如交互OLAP类查询,顺序查找(广扫描),随机访问(窄扫描)。
设计目标
- 多种数据访问类型的低延迟
- 允许压缩编码过数据上的快速查询
- 确保空间高效性
- Hadoop生态系统上可行的通用格式
- 读最优化的列式存储
- 利用多级索引实现低延迟
- 支持利用列组来获得基于行的有点
- 能够对聚合的延迟解码进行字典编码
- 贯穿整个广泛的Hadoop生态体系
深入CarbonData文件格式
CarbonData文件结构
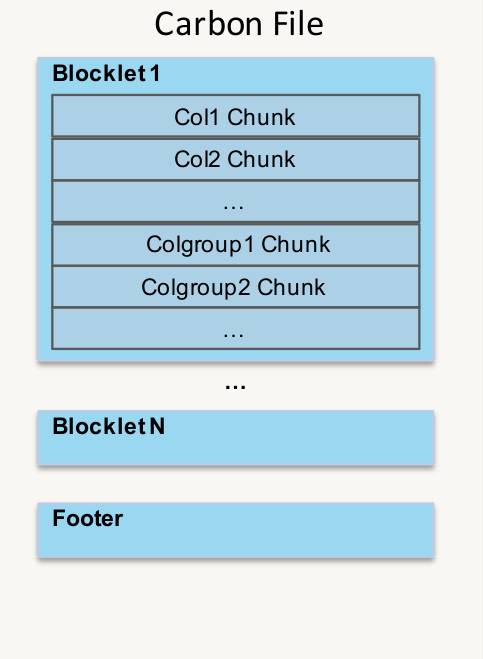
- Blocklet:一个包含列式存储中的多行的集合
- Column chunk:在一个Blocklet中一列/列组的数据
- 允许多列组成一个列组&以行格式进行存储
- 列数据以有序索引存储
- Footer:元数据信息
- 文件级别的元数据&统计信息
- 表信息
- Blocklet索引&Blocklet级别元数据
一个CarbonData文件是一个HDFS块。
版式
Blocklet
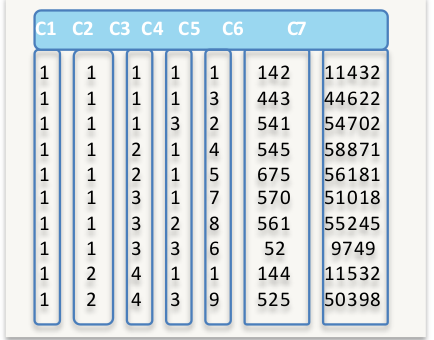
- 数据根据多维键值(MDK)排序
- 在列存中数据以索引存储
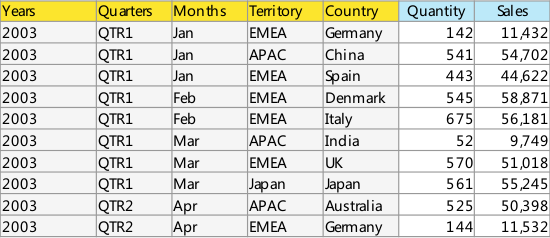
例子:
原始表
编码
对每列的取值进行Hash,如(QTR1->1),(QTR2->2),……
MDK排序
Blocklet逻辑结构图


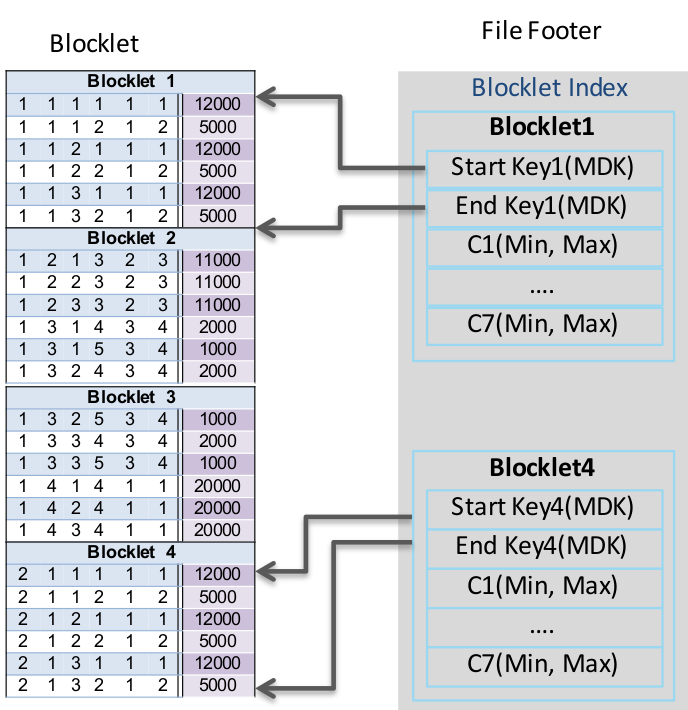
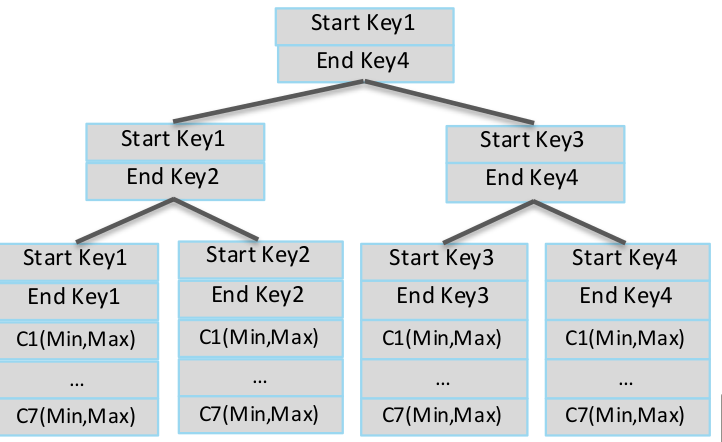
文件级别Blocklet索引
- 建立用于过滤的内存中的文件级别MDK索引
为高效扫描做的主要优化
倒排索引
- 在column chunk选择性的将列数据存储为倒排索引
- 取值种类少的列压缩效果更加好
- 利于快速判断过滤
例子:
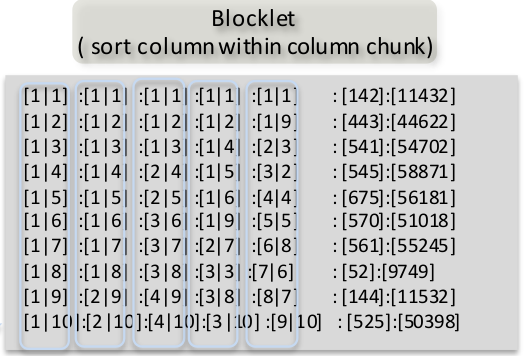
Blocklet
我们需要对每个维度按照键值进行排序,但是还要知道每个值原来的行号。所以我们把每个键值map成[值,行号],然后对每个维度按照键值进行排序。
倒排索引
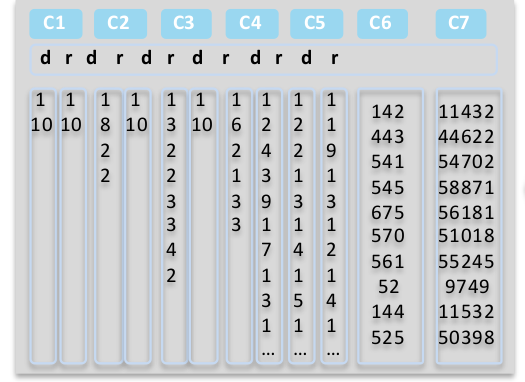
Blocklet物理结构图
- d列存储内容:值,该行开始往后,有几行都是存这个值
- r列存储内容:值,该行开始往后,有几行都是顺序增1的

















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









