









版权声明:作者:Jinliang's Hill(金良山庄),欲联系请评论博客或私信,CSDN博客: http://blog.csdn.net/u012176591
1.要求解的问题
求解无约束非线性优化问题
该问题有精确解 x∗=(1,1)T,f(x∗)=0
其梯度向量
其海森矩阵
下面定义了三个Python语言编写的函数:函数表达式fun,梯度向量gfun,和海森矩阵hess。这三个表达式在后面各个算法的实现中会用到。
# 函数表达式fun
fun = lambda x:100*(x[0]**2-x[1])**2 + (x[0]-1)**2
# 梯度向量 gfun
gfun = lambda x:np.array([400*x[0]*(x[0]**2-x[1])+2*(x[0]-1), -200*(x[0]**2-x[1])])
# 海森矩阵 hess
hess = lambda x:np.array([[1200*x[0]**2-400*x[1]+2, -400*x[0]],[-400*x[0],200]])2.线搜索技术和Armijo准则
线搜索技术是求解许多优化问题下降算法的基本组成部分,但精确线性搜索需要计算很多的函数值和梯度值,从而耗费较多资源。特别是当迭代点远离最优点时,精确线搜索技术通常不是有效和合理的。对于许多优化算法,其收敛速度并不依赖于精确搜索过程。因此既能保证目标函数具有可接受的下降量,又能使最终形成的迭代序列收敛的非精确先搜索越来越流行。
符号约定:
- gk : ∇f(xk) ,即第目标函数关于 k 次迭代值 xk 的导数。
- Gk : G(xk)=∇2f(xk) ,即海森矩阵。
- dk : 第 k 次迭代的优化方向。在最速下降算法中,有 dk=−gk
- αk : 第 k 次迭代的步长因子,有 xk+1=xk+αkdk
在精确线性搜索中,步长因子
αk
由下面的式子确定:
而对于非精确线性搜索,选取的
αk
只要使得目标函数
f
得到可接受的下降量,即
Armijo准则用于非精确线性搜索中步长因子 α 的确定,内容如下:
Armijo准则:
已知当前位置 xk 和优化的方向 dk ,参数 β∈(0,1) , δ∈(0,0.5) .令步长因子 αk=βmk ,其中 mk 为满足下列不等式的最小非负整数 m :
f(xk+βmdk)≤f(xk)+δβmgTkdk
由此确定的下一个位置 xk+1=xk+αkdk
NOTE: 上面的公式仅仅适用于梯度下降(Gradient Descent),对于梯度上升,则略有不用。首先公式变成了f(xk−βmdk)≥f(xk)−δβmgTkdk,然后确定下一个位置 xk+1=xk−αkdk
该准则在接下来的介绍的几个算法中多次使用。
3.最速下降法及其Python实现
算法描述:
step 1 :选取初始点 x0∈Rn ,容许误差 0≤ϵ≪1 .令 k←1 .
step 2 :计算 gk=∇f(xk) . 若 ||gk||≤ϵ ,停止迭代,输出 xk 作为近似最优解。
step 3 :取方向 dk=−gk .
step 4 :由线搜索技术确定步长因子 αk .
step 5 :令 xk+1←xk+αkdk ,转step 2.
上述step 3中步长因子
αk
的确定既可以使用精确线搜索方法,也可以使用非精确线搜索方法,在理论上都能保证其全局收敛性。若采用精确线搜索方法,则
αk
满足
从而有
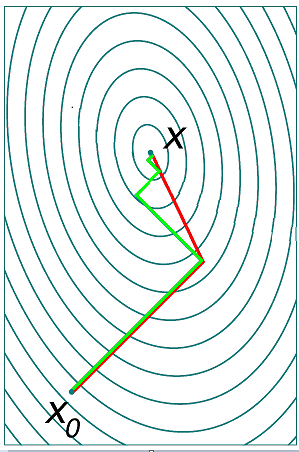
即 xk+1 处的梯度与其前驱 xk 处的梯度是正交的,也就是说,迭代点序列所走的路线是锯齿形的,这造成其收敛速度很缓慢。如下图所示,其中绿色折线所显示的路线就是由最速下降法得到的,红色曲线是由共轭梯度下降法确定的,通过对比可以看出梯度下降法所走的路线是锯齿形的,经测试,其收敛速度非常慢。
最速下降法的Python实现。
def gradient(fun,gfun,x0):
#最速下降法求解无约束问题
# x0是初始点,fun和gfun分别是目标函数和梯度
maxk = 5000
rho = 0.5
sigma = 0.4
k = 0
epsilon = 1e-5
while k<maxk:
gk = gfun(x0)
dk = -gk
if np.linalg.norm(dk) < epsilon:
break
m = 0
mk = 0
while m< 20:
if fun(x0+rho**m*dk) < fun(x0) + sigma*rho**m*np.dot(gk,dk):
mk = m
break
m += 1
x0 += rho**mk*dk
k += 1
return x0,fun(x0),k性能测试
可以看到大约有一半的样本的迭代次数要超过2000次。
4.牛顿法
牛顿法的基本思想是用迭代点 xk 处的一阶导数(梯度 gk )和二阶倒数(海森矩阵 Gk )对目标函数进行二次函数近似,然后把二次模型的极小点作为新的迭代点。
牛顿法推导
函数 f(x) 在 xk 处的泰勒展开式的前三项得
T(f,xk,3)=fk+gTk(x−xk)+12(x−xk)TGk(x−xk)
则其稳定点∇T=gk+Gk(x−xk)=0
若 Gk 非奇异,那么解上面的线性方程(标记其解为 xk+1 )即得到牛顿法的迭代公式xk+1=xk−G−1kgk
即优化方向为 dk=−G−1kgk
求稳定点是用到了以下公式:
考虑 y=xTAx ,根据矩阵求导法则,有
dydx=Ax+ATxd2ydx2=A+AT
注意实际中 dk 的是通过求解线性方程组 Gkd=−gk 获得的。
阻尼牛顿法及其Python实现
阻尼牛顿法采用了牛顿法的思想,唯一的差别是阻尼牛顿法并不直接采用 xk+1=xk+dk ,而是用线搜索技术获得合适的步长因子 αk ,用公式 xk+1=xk+δmdk 计算 xk+1 。
阻尼牛顿法的算法描述:
step 1: 给定终止误差 0≤ϵ≪1,δ∈(0,1),σ∈(0,0.5) . 初始点 x0∈Rn . 令 k←0
step 2: 计算 gk=∇f(xk) . 若 ||gk||≤ϵ ,停止迭代,输出 x∗≈xk
step 3: 计算 Gk=∇2f(xk) ,并求解线性方程组得到解 dk ,Gkd=−gk
step 4: 记 mk 是满足下列不等式的最小非负整数 m .f(xk+βmdk)≤f(xk)+δβmgTkdk
step 5: 令 αk=δmk,xk+1=xk+αkdk,k←k+1 ,转 step 2
阻尼牛顿法的Python实现:
def dampnm(fun,gfun,hess,x0):
# 用阻尼牛顿法求解无约束问题
#x0是初始点,fun,gfun和hess分别是目标函数值,梯度,海森矩阵的函数
maxk = 500
rho = 0.55
sigma = 0.4
k = 0
epsilon = 1e-5
while k < maxk:
gk = gfun(x0)
Gk = hess(x0)
dk = -1.0*np.linalg.solve(Gk,gk)
if np.linalg.norm(dk) < epsilon:
break
m = 0
mk = 0
while m < 20:
if fun(x0+rho**m*dk) < fun(x0) + sigma*rho**m*np.dot(gk,dk):
mk = m
break
m += 1
x0 += rho**mk*dk
k += 1
return x0,fun(x0),k性能展示
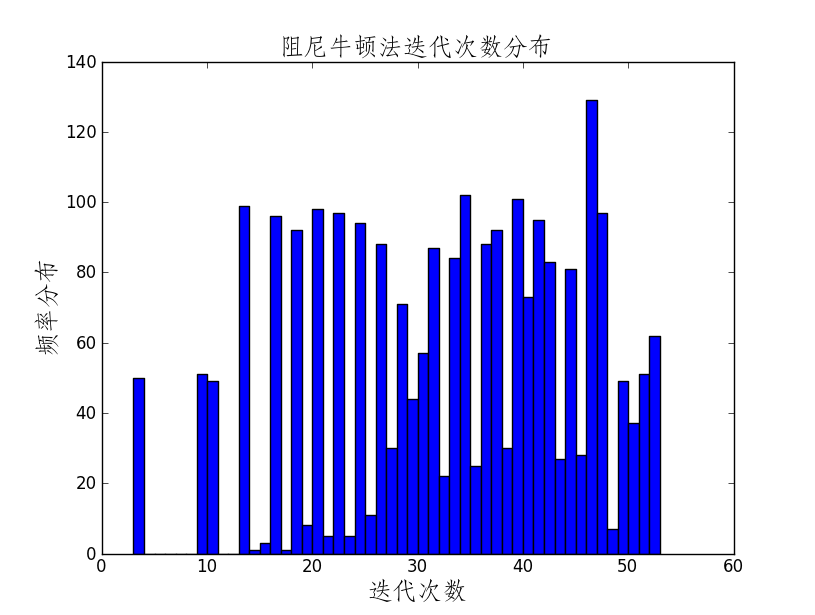
作图代码:
iters = []
for i in xrange(np.shape(data)[0]):
rt = dampnm(fun,gfun,hess,data[i])
if rt[2] <=200:
iters.append(rt[2])
if i%100 == 0:
print i,rt[2]
plt.hist(iters,bins=50)
plt.title(u'阻尼牛顿法迭代次数分布',{'fontname':'STFangsong','fontsize':18})
plt.xlabel(u'迭代次数',{'fontname':'STFangsong','fontsize':18})
plt.ylabel(u'频率分布',{'fontname':'STFangsong','fontsize':18})修正牛顿法法及其Python实现
牛顿法要求目标函数的海森矩阵
G(x)=∇2f(x)
在每个迭代点
xk
处是正定的,否则难以保证牛顿方向
dk=−G−1kgk
是
f
在
xk
处的下降方向。为克服这一缺陷,需要对牛顿法进行修正。
下面介绍两种修正方法,分别是“牛顿-最速下降混合算法”和“修正牛顿法”。
牛顿-最速下降混合算法
该方法将牛顿法和最速下降法结合起来,基本思想是:当海森矩阵正定时,采用牛顿法确定的优化方向作为搜索方向;否则,即海森矩阵为非正定矩阵时,则采用负梯度方向作为搜索方向。
修正牛顿法
引入阻尼因子
μk≥0
,即在每一迭代步适当选取参数
μk
,使得矩阵
Ak=Gk+μkI
正定,用
Ak
代替
Gk
来求解
dk
。
算法描述:
step 1: 给定终止误差 0≤ϵ≪1,δ∈(0,1),σ∈(0,0.5) . 初始点 x0∈Rn . 令 k←0
step 2: 计算 gk=∇f(xk) , μk=||gk||1+τ . 若 ||gk||≤ϵ ,停止迭代,输出 x∗≈xk
step 3: 计算 Gk=∇2f(xk) ,并求解线性方程组得到解 dk ,(Gk+μkI)d=−gk
step 4: 记 mk 是满足下列不等式的最小非负整数 m .f(xk+βmdk)≤f(xk)+δβmgTkdk
step 5: 令 αk=δmk,xk+1=xk+αkdk,k←k+1 ,转 step 2
修正牛顿法的Python实现代码:
def revisenm(fun,gfun,hess,x0):
# 用修正牛顿法求解无约束问题
#x0是初始点,fun,gfun和hess分别是目标函数值,梯度,海森矩阵的函数
maxk = 1e5
n = np.shape(x0)[0]
rho = 0.55
sigma = 0.4
tau = 0.0
k = 0
epsilon = 1e-5
while k < maxk:
gk = gfun(x0)
if np.linalg.norm(gk) < epsilon:
break
muk = np.power(np.linalg.norm(gk),1+tau)
Gk = hess(x0)
Ak = Gk + muk*np.eye(n)
dk = -1.0*np.linalg.solve(Ak,gk)
m = 0
mk = 0
while m < 20:
if fun(x0+rho**m*dk) < fun(x0) + sigma*rho**m*np.dot(gk,dk):
mk = m
break
m += 1
x0 += rho**mk*dk
k += 1
return x0,fun(x0),k性能展示
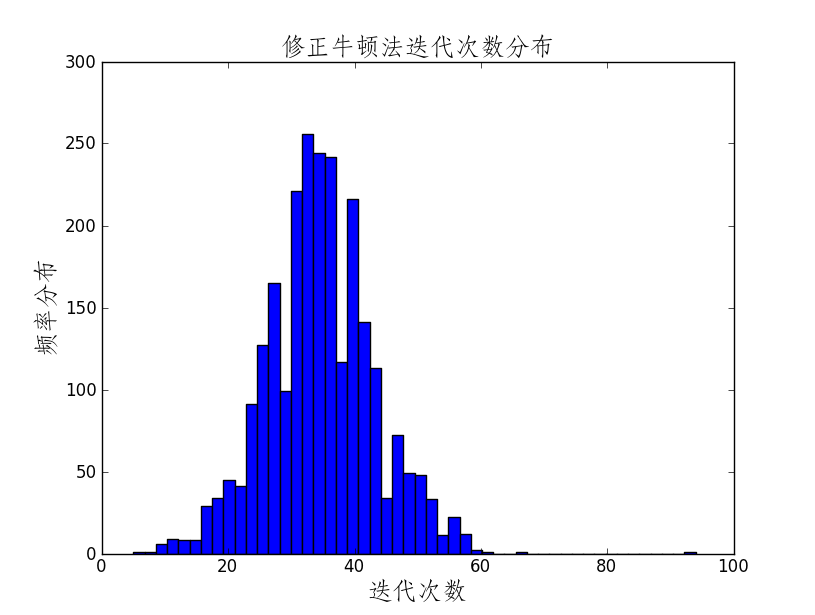
5.拟牛顿法
牛顿法的优点是具有二阶收敛速度,缺点是:
- 但当海森矩阵 G(xk)=∇2f(x) 不正定时,不能保证所产生的方向是目标函数在 xk 处的下降方向。
- 特别地,当 G(xk) 奇异时,算法就无法继续进行下去。尽管修正牛顿法可以克服这一缺陷,但修正参数的取值很难把握,过大或过小都会影响到收敛速度。
- 牛顿法的每一步迭代都需要目标函数的海森矩阵 G(xk) ,对于大规模问题其计算量是惊人的。
拟牛顿法的基本思想是用海森矩阵 Gk 的某个近似矩阵 Bk 取代 Gk . Bk 通常具有下面三个特点:
- 在某种意义下有 Bk≈Gk ,使得相应的算法产生的方向近似于牛顿方向,确保算法具有较快的收敛速度。
- 对所有的 k , Bk 是正定的,从而使得算法所产生的方向是函数 f 在 xk 处下降方向。
- 矩阵 Bk 更新规则比较简单
设
f:Rn→R
在开集
D⊂Rn
上二次连续可微,那么
f
在
xk+1
处的二次近似模型为:
对上式求导得
令 x=xk ,位移 sk=xk+1−xk ,梯度差 yk=gk+1−gk ,则有
因此,拟牛顿法中近似矩阵 Bk 要满足关系式
令 Hk+1=B−1k+1 ,得到拟牛顿法的另一形式
其中 Hk+1 为海森矩阵逆矩阵的近似。上面两个公式称为 拟牛顿方程。
搜索方向由 dk=−Hkgk 或 Bkdk=−gk 确定。根据近似矩阵的第三个特点,有
其中 Ek,Dk 为秩1或秩2矩阵。该公式称为 校正规则。
通常将上面的三个式子(拟牛顿方程和校正规则)所确立的方法称为拟牛顿法。从下面的拟牛顿法的几个变种可以看出,不同的拟牛顿法的主要区别在于更新公式的不同。
DFP算法及其Python实现
DFP算法的校正公式如下:
注意公式中的两个分数结构,分母 yTkHkyk 和 sTkyk 是标量,分子 HkykyTkHk 和 sksTk 是与 Hk 同型的矩阵,而且都是对称矩阵。若 Hk 正定,且 sTkyk>0 ,则 Hk+1 也正定。
当采用精确线搜索时,矩阵序列
Hk
的正定新条件
sTkyk>0
可以被满足。但对于
Armijo
搜索准则来说,不能满足这一条件,需要做如下修正:
DFP算法描述:
step 1: 给定参数 δ∈(0,1),σ∈(0,0.5) ,初始点 x0∈R ,终止误差 0≤ϵ≪1 .初始对称正定矩阵 H0 (通常取为 G(x0)−1 或单位矩阵 In ).令 k←0
step 2: 计算 gk=∇f(xk) . 若 ||gk||≤ϵ ,停止迭代,输出 x∗≈xk
step 3: 计算搜索方向dk=−Hkgk
step 4: 记 mk 是满足下列不等式的最小非负整数 m .f(xk+βmdk)≤f(xk)+δβmgTkdk令 αk=δmk,xk+1=xk+αkdk
step 5: 由校正公式确定 Hk+1
step 6: k←k+1 ,转 step 2
DFP算法的代码实现
def dfp(fun,gfun,hess,x0):
#功能:用DFP族算法求解无约束问题:min fun(x)
#输入:x0是初始点,fun,gfun分别是目标函数和梯度
#输出:x,val分别是近似最优点和最优解,k是迭代次数
maxk = 1e5
rho = 0.55
sigma = 0.4
epsilon = 1e-5
k = 0
n = np.shape(x0)[0]
#海森矩阵可以初始化为单位矩阵
Hk = np.linalg.inv(hess(x0)) #或者单位矩阵np.eye(n)
while k < maxk :
gk = gfun(x0)
if np.linalg.norm(gk) < epsilon:
break
dk = -1.0*np.dot(Hk,gk)
m=0;
mk=0
while m < 20: # 用Armijo搜索求步长
if fun(x0+rho**m*dk) < fun(x0)+sigma*rho**m*np.dot(gk,dk):
mk = m
break
m += 1
#print mk
#DFP校正
x = x0 + rho**mk*dk
sk = x - x0
yk = gfun(x) - gk
if np.dot(sk,yk) > 0:
Hy = np.dot(Hk,yk)
print Hy
sy = np.dot(sk,yk) #向量的点积
yHy = np.dot(np.dot(yk,Hk),yk) # yHy是标量
#表达式Hy.reshape((n,1))*Hy 中Hy是向量,生成矩阵
Hk = Hk - 1.0*Hy.reshape((n,1))*Hy/yHy + 1.0*sk.reshape((n,1))*sk/sy
k += 1
x0 = x
return x0,fun(x0),k#分别是最优点坐标,最优值,迭代次数由以上代码可知,拟牛顿法只需要在迭代开始前计算一次海森矩阵,更一般的,根本就不计算海森矩阵,而是初始化为单位矩阵,在每次迭代过程中是不需按传统方法(二阶导数)计算海森矩阵的。
实际性能
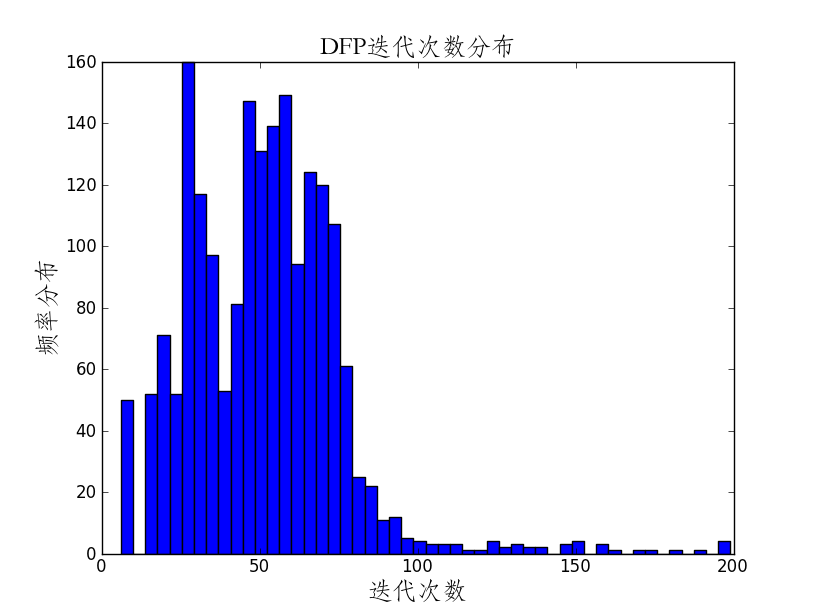
相关代码:
n = 50
x = y = np.linspace(-10,10,n)
xx,yy = np.meshgrid(x,y)
data = [[xx[i][j],yy[i][j]] for i in range(n) for j in range(n)]
iters = []
for i in xrange(np.shape(data)[0]):
rt = dfp(fun,gfun,hess,np.array(data[i]))
if rt[2] <=200: # 提出迭代次数过大的
iters.append(rt[2])
if i%100 == 0:
print i,rt[2]
plt.hist(iters,bins=50)
plt.title(u'DFP迭代次数分布',{'fontname':'STFangsong','fontsize':18})
plt.xlabel(u'迭代次数',{'fontname':'STFangsong','fontsize':18})
plt.ylabel(u'频率分布',{'fontname':'STFangsong','fontsize':18})BFGS算法及其Python实现
BFGS算法与DFP步骤基本相同,区别在于更新公式的差异
BFGS算法的Python实现
def bfgs(fun,gfun,hess,x0):
#功能:用BFGS族算法求解无约束问题:min fun(x)
#输入:x0是初始点,fun,gfun分别是目标函数和梯度
#输出:x,val分别是近似最优点和最优解,k是迭代次数
maxk = 1e5
rho = 0.55
sigma = 0.4
epsilon = 1e-5
k = 0
n = np.shape(x0)[0]
#海森矩阵可以初始化为单位矩阵
Bk = eye(n)#np.linalg.inv(hess(x0)) #或者单位矩阵np.eye(n)
while k < maxk:
gk = gfun(x0)
if np.linalg.norm(gk) < epsilon:
break
dk = -1.0*np.linalg.solve(Bk,gk)
m = 0
mk = 0
while m < 20: # 用Armijo搜索求步长
if fun(x0+rho**m*dk) < fun(x0)+sigma*rho**m*np.dot(gk,dk):
mk = m
break
m += 1
#BFGS校正
x = x0 + rho**mk*dk
sk = x - x0
yk = gfun(x) - gk
if np.dot(sk,yk) > 0:
Bs = np.dot(Bk,sk)
ys = np.dot(yk,sk)
sBs = np.dot(np.dot(sk,Bk),sk)
Bk = Bk - 1.0*Bs.reshape((n,1))*Bs/sBs + 1.0*yk.reshape((n,1))*yk/ys
k += 1
x0 = x
return x0,fun(x0),k#分别是最优点坐标,最优值,迭代次数 实际性能
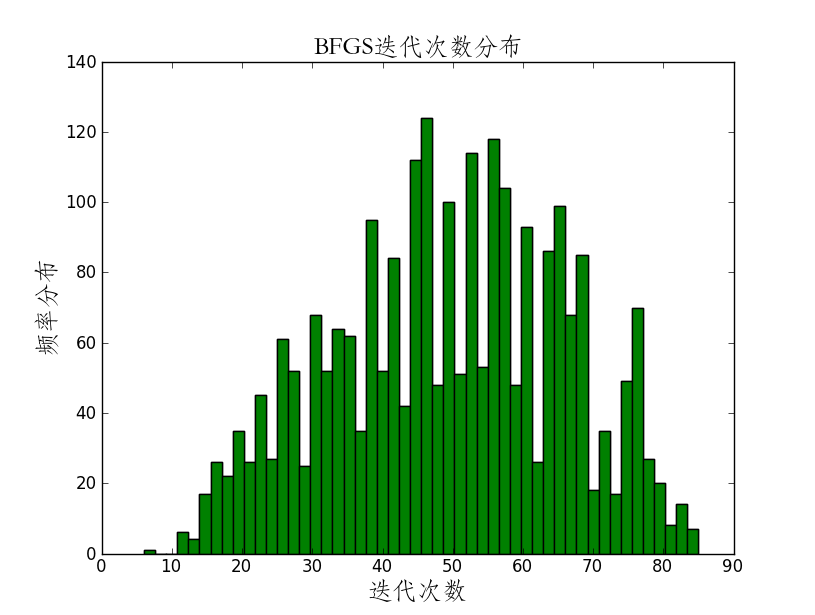
相关代码:
iters = []
for i in xrange(np.shape(data)[0]):
rt = bfgs(fun,gfun,hess,np.array(data[i]))
if rt[2] <=200:
iters.append(rt[2])
if i%100 == 0:
print i,rt[2]
plt.hist(iters,bins=50)
plt.title(u'BFGS迭代次数分布',{'fontname':'STFangsong','fontsize':18})
plt.xlabel(u'迭代次数',{'fontname':'STFangsong','fontsize':18})
plt.ylabel(u'频率分布',{'fontname':'STFangsong','fontsize':18})Broyden族算法及其Python实现
之前的BFGS和DFP校正都是由
yk
和
Bksk
(或
sk
和
Hkyk
)组成的秩2矩阵。而Broyden族算法采用了BFGS和DFP校正公式的凸组合,如下:
其中 ϕk∈[0,1] , vk 由下式定义:
Broyden族算法Python实现
def broyden(fun,gfun,hess,x0):
#功能:用Broyden族算法求解无约束问题:min fun(x)
#输入:x0是初始点,fun,gfun分别是目标函数和梯度
#输出:x,val分别是近似最优点和最优解,k是迭代次数
x0 = np.array(x0)
maxk = 1e5
rho = 0.55;
sigma = 0.4;
epsilon = 1e-5
phi = 0.5;
k=0;
n = np.shape(x0)[0]
Hk = np.linalg.inv(hess(x0))
while k<maxk :
gk = gfun(x0)
if np.linalg.norm(gk) < epsilon:
break
dk = -1*np.dot(Hk,gk)
m=0;mk=0
while m < 20: # 用Armijo搜索求步长
if fun(x0+rho**m*dk) < fun(x0)+sigma*rho**m*np.dot(gk,dk):
mk = m
break
m += 1
#Broyden族校正
x = x0 + rho**mk*dk
sk = x - x0
yk = gfun(x) - gk
Hy = np.dot(Hk,yk)
sy = np.dot(sk,yk)
yHy = np.dot(np.dot(yk,Hk),yk)
if(sy < 0.2 *yHy):
theta = 0.8*yHy/(yHy-sy)
sk = theta*sk + (1-theta)*Hy
sy = 0.2*yHy
vk = np.sqrt(yHy)*(sk/sy-Hy/yHy)
Hk = Hk - Hy.reshape((n,1))*Hy/yHy +sk.reshape((n,1))*sk/sy + phi*vk.reshape((n,1))*vk
k += 1
x0 = x
return x0,fun(x0),k #分别是最优点坐标,最优值,迭代次数实际性能
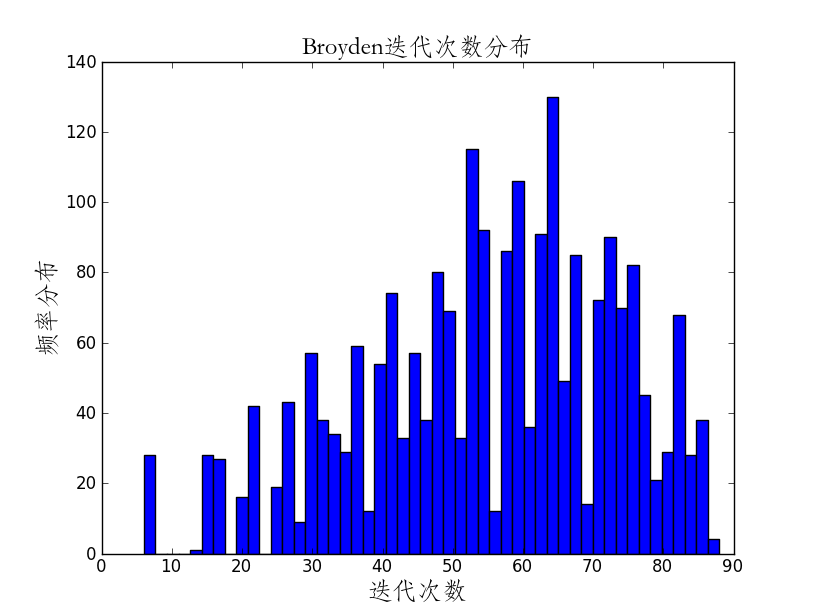
相关代码:
iters = []
for i in xrange(np.shape(data)[0]):
rt = broyden(fun,gfun,hess,np.array(data[i]))
if rt[2] <=200:
iters.append(rt[2])
if i%100 == 0:
print i,rt[2]
plt.hist(iters,bins=50)
plt.title(u'Broyden迭代次数分布',{'fontname':'STFangsong','fontsize':18})
plt.xlabel(u'迭代次数',{'fontname':'STFangsong','fontsize':18})
plt.ylabel(u'频率分布',{'fontname':'STFangsong','fontsize':18})L-BFGS算法及其Python实现
拟牛顿法(如BFGS算法)需要计算和存储海森矩阵,其空间复杂度是 n2 ,当 n 很大时,其需要的内存量是非常大的。为了解决该内存问题,有限内存BFGS(即传说中的L-BFGS算法)横空出世。
基本BFGS算法的校正公式可以改写成
记 ρk=1/sTkyk ,以及 Vk=(I−ρkyksTk) ,则上式可以写成
给定一个初始矩阵 H0 (其取值后面有提到),则由上式的递推关系可以得到
更一般的,我们有
在上式的右边中, H0 是由我们设置的,其余变量可由保存的最近 m 次迭代所形成的向量序列,如位移向量序列 {sk} 和一阶导数差所形成的向量序列 {yk} 获得。也就是说,可由最近 m 次迭代的信息计算当前的海森矩阵的近似矩阵。
补充几点:
- H0=I⋅sTmymyTmym ,第一次迭代时,序列{ sk }和{ yk }为空,则 H0=I
- 最初的若干次迭代, 序列{ sk }和{ yk }的元素个数较小,会有 n<m ,则将 Hm+1 计算公式右边的 m 换成 n 即可。
- 随着迭代次数增加, 序列{ sk }和{ yk }的元素个数增大,会有 n>m 。由于我们只需要最近 m 次迭代产生的序列元素,所以序列{ sk }和{ yk }只需要保存最新的 m 个元素即可,如果再有新的元素进入,则同时扔掉最旧的元素,以保证序列元素个数恒为 m 。
这就是L-BFGS算法的思想。聪明的同学会问:你上面的公式不还是要计算海森矩阵的近似矩阵吗?那岂不是还是需要
n2
规模的内存?
其实在实际中是不计算该矩阵的, 而且不是采用上面的方法,而是直接得到
Hkgk
,而搜索方向就是
dk=−Hkgk
。下面给出了计算的函数twoloop(s,y,
ρ
,gk)的伪代码,可知该函数内部的计算仅限于标量和向量,未出现矩阵。
函数参数 s,y 即向量序列{ sk }和{ yk }, ρ 为元素序列{ ρk },其元素 ρk=1/sTkyk , gk 是向量,为当前的一阶导数,输出为向量 z=Hkgk ,即搜索方向的反方向
Functiontwoloop(s,y,ρ,gk)q=gkFori=k−1,k−2,…,k−mαi=ρisTiqq=q−αiyiHk=yTk−1sk−1/yTk−1yk−1z=HkqFori=k−m,k−m+1,…,k−1βi=ρiyTizz=z+si(αi−βi)Returnz
给出L-BFGS的算法
可以看到其搜索方向 dk 是根据函数 twoloop 计算得到的。

L-BFGS算法Python实现
def twoloop(s, y, rho,gk):
n = len(s) #向量序列的长度
if np.shape(s)[0] >= 1:
#h0是标量,而非矩阵
h0 = 1.0*np.dot(s[-1],y[-1])/np.dot(y[-1],y[-1])
else:
h0 = 1
a = empty((n,))
q = gk.copy()
for i in range(n - 1, -1, -1):
a[i] = rho[i] * dot(s[i], q)
q -= a[i] * y[i]
z = h0*q
for i in range(n):
b = rho[i] * dot(y[i], z)
z += s[i] * (a[i] - b)
return z
def lbfgs(fun,gfun,x0,m=5):
# fun和gfun分别是目标函数及其一阶导数,x0是初值,m为储存的序列的大小
maxk = 2000
rou = 0.55
sigma = 0.4
epsilon = 1e-5
k = 0
n = np.shape(x0)[0] #自变量的维度
s, y, rho = [], [], []
while k < maxk :
gk = gfun(x0)
if np.linalg.norm(gk) < epsilon:
break
dk = -1.0*twoloop(s, y, rho,gk)
m0=0;
mk=0
while m0 < 20: # 用Armijo搜索求步长
if fun(x0+rou**m0*dk) < fun(x0)+sigma*rou**m0*np.dot(gk,dk):
mk = m0
break
m0 += 1
x = x0 + rou**mk*dk
sk = x - x0
yk = gfun(x) - gk
if np.dot(sk,yk) > 0: #增加新的向量
rho.append(1.0/np.dot(sk,yk))
s.append(sk)
y.append(yk)
if np.shape(rho)[0] > m: #弃掉最旧向量
rho.pop(0)
s.pop(0)
y.pop(0)
k += 1
x0 = x
return x0,fun(x0),k#分别是最优点坐标,最优值,迭代次数实际性能
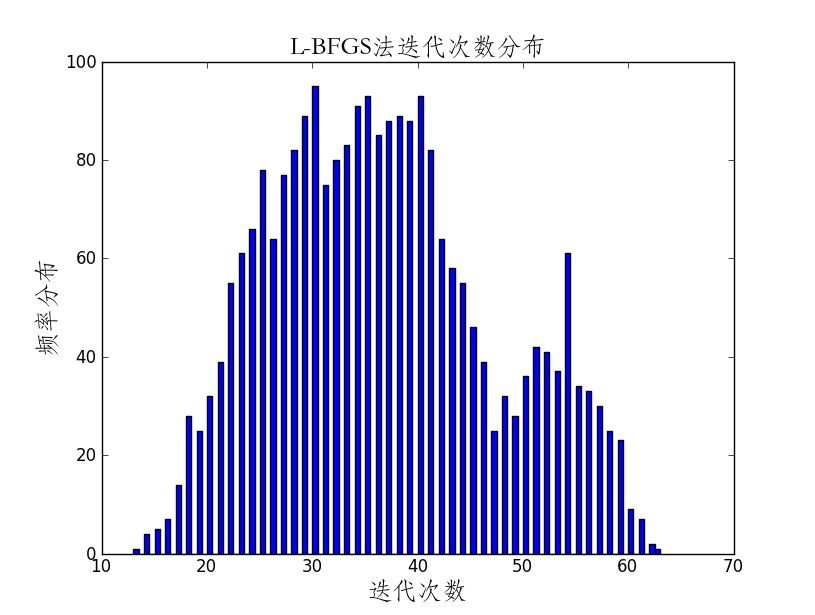
相关代码:
n = 50
x = y = np.linspace(-10,10,n)
xx,yy = np.meshgrid(x,y)
data = [[xx[i][j],yy[i][j]] for i in range(n) for j in range(n)]
iters = []
for i in xrange(np.shape(data)[0]):
rt = lbfgs(fun,gfun,data[i])
if rt[2] <=1000:
iters.append(rt[2])
if i%100 == 0:
print i,rt[2]
plt.hist(iters,bins=100)
plt.title(u'L-BFGS法迭代次数分布',{'fontname':'STFangsong','fontsize':18})
plt.xlabel(u'迭代次数',{'fontname':'STFangsong','fontsize':18})
plt.ylabel(u'频率分布',{'fontname':'STFangsong','fontsize':18})参考文献
- Large-scale L-BFGS using MapReduce
http://papers.nips.cc/paper/5333-large-scale-l-bfgs-using-mapreduce.pdf - L-BFGS的原理及在回归分析中的应用
http://blog.csdn.net/hlx371240/article/details/39970727
L-BFGS的原理和MATLAB实现 - deep learning Softmax分类器(L-BFGS,CG,SD)
http://blog.csdn.net/hlx371240/article/details/40015395 - 机器学习中导数最优化方法
http://www.cnblogs.com/daniel-D/p/3377840.html - Newton’s method in optimization
http://en.wikipedia.org/wiki/Newton%27s_method_in_optimization - Quasi-Newton method
http://en.wikipedia.org/wiki/Quasi-Newton_method - Davidon–Fletcher–Powell formula
http://en.wikipedia.org/wiki/Davidon%E2%80%93Fletcher%E2%80%93Powell_formula - Broyden–Fletcher–Goldfarb–Shanno algorithm
http://en.wikipedia.org/wiki/Broyden%E2%80%93Fletcher%E2%80%93Goldfarb%E2%80%93Shanno_algorithm - Limited-memory BFGS
http://en.wikipedia.org/wiki/Limited-memory_BFGS - some books
《Basic Concepts and Stationary Iterative Methods》
《Iterative Methods for Optimization》
《Non-Linear Least-Squares Minimization》 - some papers
《A comparison of algorithms for maximum entropy parameter estimation》
《Updating Quasi-Newton Matrices with Limited Storage》
《Scalable Training of L1-Regularized Log-Linear Models》 - 《最优化方法及其MATLAB程序设计》,马昌凤,科学出版社
- 《优化方法》,李春明,东南大学出版社
- 《应用最优化方法及MATLAB实现》,刘兴高,胡云卿,科学出版社
- 《优化技术与MATLAB优化工具箱》,赵继俊,机械工业出版社
- http://hub.darcs.net/amgarching/pts/browse/bfgs.py
- markdown 公式,可直接复制得到特性公式
http://www.aleacubase.com/cudalab/cudalab_usage-math_formatting_on_markdown.html - CSDN-markdown语法之如何插入图片
http://blog.csdn.net/lanxuezaipiao/article/details/44310775















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









