







1.官方定义
a MapReduce-like cluster computing framework designed for low-latency iterative jobs and interactive use from an interpreter.
2.体系结构
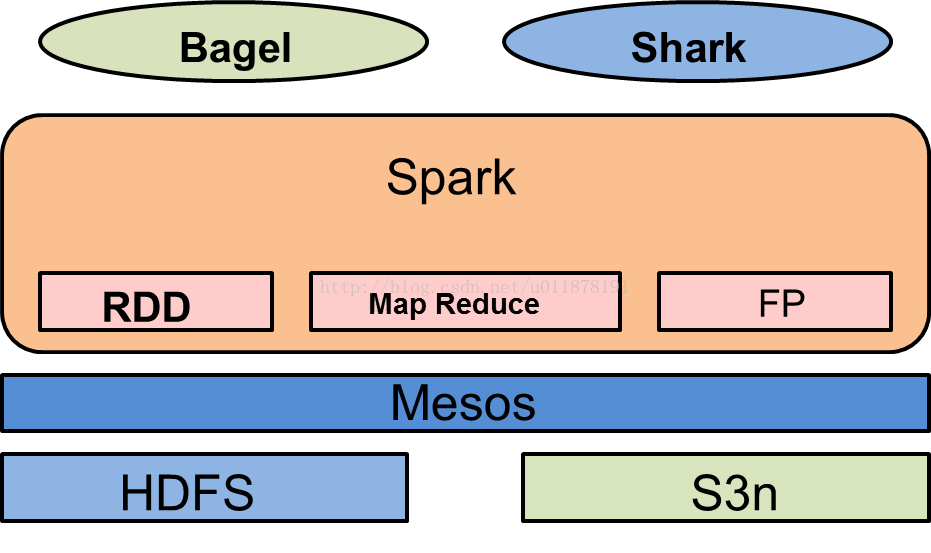
3.一些重要概念的解析
(1) RDD (resilient distributed dataset)
弹性分布式数据集 一个只读的,可分区的分布式数据集,能够部分或全部的缓存在内存中(数据溢出时会根据LRU策略来决定哪些数据可以放在内存里,哪些存到磁盘上),用来减少Disk-io,Network-io的读写开销,从而降低整个计算框架的开销。RDD支持两种操作,分别是transformation,如filter、map、join、union,和Action,如reduce,count,save,collect等。transformation是从一个已有的数据集创建一个新的数据集,而action是将transformation的数据集进行迭代计算,并将计算结果传递给Driver。为了提高运行效率,Spark中所有的Action都是延迟生成的,就是说它只是暂时的记住之前的转换动作,只有当真正需要将数据集返回给Driver时才会执行这些动作。
(2)Lineage
称为血统,是用来记录RDD数据集是如何从其他RDD数据集演变过来的,当某个RDD数据集部分分区
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









