1.官方定义
a MapReduce-like cluster computing framework designed for low-latency iterative jobs and interactive use from an interpreter.
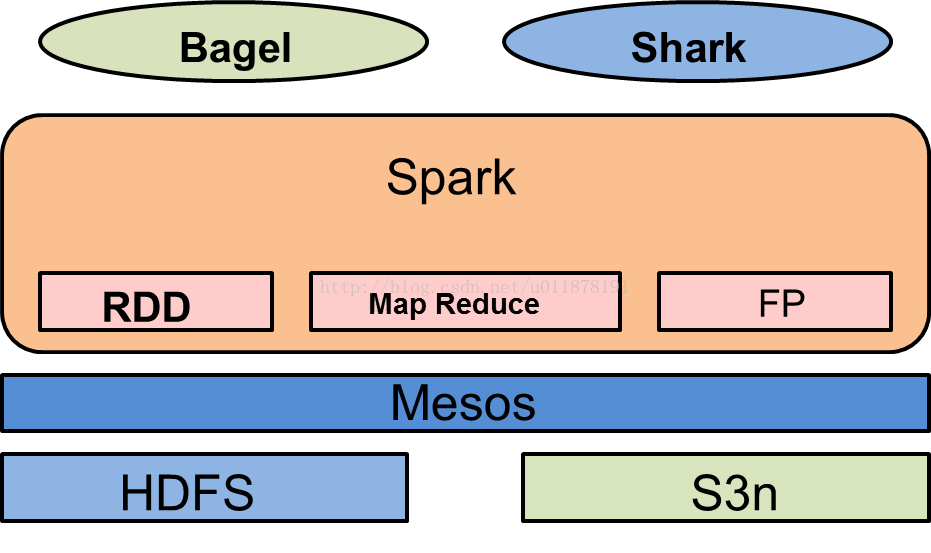
2.体系结构
3.一些重要概念的解析
(1) RDD (resilient distributed dataset)
弹性分布式数据集 一个只读的,可分区的分布式数据集,能够部分或全部的缓存在内存中(数据溢出时会根据LRU策略来决定哪些数据可以放在内存里,哪些存到磁盘上),用来减少Disk-io,Network-io的读写开销,从而降低整个计算框架的开销。RDD支持两种操作,分别是transformation,如filter、map、join、union,和Action,如reduce,count,save,collect等。transformation是从一个已有的数据集创建一个新的数据集,而action是将transformation的数据集进行迭代计算,并将计算结果传递给Driver。为了提高运行效率,Spark中所有的Action都是延迟生成的,就是说它只是暂时的记住之前的转换动作,只有当真正需要将数据集返回给Driver时才会执行这些动作。
(2)Lineage
称为血统,是用来记录RDD数据集是如何从其他RDD数据集演变过来的,当某个RDD数据集部分分区数据丢失时,系统可以通过Lineage获得足够的信息来重新运算和恢复丢失的数据分区。这是Spark为了提高系统性能所设计的粗粒度的容错机制。相比于其它的备份机制或Log机制的细粒度的容错处理机制,这种粗粒度的容错机制减少了数据的冗余和读写磁盘的开销。
RDD的血统依赖分为两种,即宽依赖和窄依赖。如图所示
窄依赖是指父RDD的每个分区仅对应一个子RDD分区,而一个子RDD分区可以使用一个或多个父RDD分区。宽依赖是指父RDD的每个分区可以对应多个子RDD分区,而每一个子RDD分区也可以使用父RDD的多个分区。当一个节点宕机时,明显数据重算的开销宽依赖比窄依赖要大。
(3) DAG (Directed Acycle graph) 有向无环图 反映了RDD之间的依赖关系
4.生态系统
spark主要支持的组件有:
(1)用于大数据查询分析计算的组件Shark。对于Spark来说,Shark的作用就类似于Hive在Hadoop系统中的作用,Shark提供了一系列的命令接口,通过配置参数可以缓存Spark中特定的RDD,并对数据进行检索。此外,Shark可以调用用户自定义函数,将数据分析与SQL查询结合并实现数据重用,从而提高计算速度。
(2)用于流式计算组件Spark Streaming。它的基本原理是,将数据分割成非常小的数据片段,封装到RDD分区中,然后以类似批处理的方式来处理这些小数据,利用Spark基于内存的特点,可以保证计算的低延迟性,以及兼容批处理和实时数据处理的算法,另外通过Lineage来进行容错。
(3)对于图计算的GraphX:spark的GraphX提供了对图操作的API,在图加载,边反转和邻接计算方面对通信的要求更低,产生的RDD图更加简单,。利用GraphX框架可以很方便的实现多种图算法。
(4)用于机器学习的MLib组件,提供了机器学习算法的实现库,目前支持聚类、二元分类,回归以及协同过滤算法。同时也提供了相关测试和数据生成器。
spark既可以在本地单节点上运行(开发调试用)也可以集群运行,集群运行需要集群管理器Mesos,Yarn等将计算任务分布到分布式系统的各个工作节点上。spark的数据源可以由HDFS(或者其他类似文件系统)生成。
五、编程模型(转自http://www.cnblogs.com/vincent-hv/p/3278169.html)
spark的所有操作时基于RDD的,RDD算子相比于Hadoop丰富了不少。
一部分变换算子视RDD的元素为简单元素,分为如下几类:
- 输入输出一对一(element-wise)的算子,且结果RDD的分区结构不变,主要是map、flatMap(map后展平为一维RDD);
- 输入输出一对一,但结果RDD的分区结构发生了变化,如union(两个RDD合为一个)、coalesce(分区减少);
- 从输入中选择部分元素的算子,如filter、distinct(去除冗余元素)、subtract(本RDD有、它RDD无的元素留下来)和sample(采样)。
另一部分变换算子针对Key-Value集合,又分为:
- 对单个RDD做element-wise运算,如mapValues(保持源RDD的分区方式,这与map不同);
- 对单个RDD重排,如sort、partitionBy(实现一致性的分区划分,这个对数据本地性优化很重要,后面会讲);
- 对单个RDD基于key进行重组和reduce,如groupByKey、reduceByKey;
- 对两个RDD基于key进行join和重组,如join、cogroup。
后三类操作都涉及重排,称为shuffle类操作。
从RDD到RDD的变换算子序列,一直在RDD空间发生。这里很重要的设计是lazy evaluation:计算并不实际发生,只是不断地记录到元数据。元数据的结构是DAG(有向无环图),其中每一个“顶点”是RDD(包括生产该RDD 的算子),从父RDD到子RDD有“边”,表示RDD间的依赖性。 Spark给元数据DAG取了个很酷的名字,Lineage(世系)。这个 Lineage也是前面容错设计中所说的日志更新。
Lineage一直增长,直到遇上行动(action)算子(图1中的绿色箭头),这时 就要evaluate了,把刚才累积的所有算子一次性执行。行动算子的输入是RDD(以及该RDD在Lineage上依赖的所有RDD),输出是执行后生 成的原生数据,可能是Scala标量、集合类型的数据或存储。当一个算子的输出是上述类型时,该算子必然是行动算子,其效果则是从RDD空间返回原生数据 空间。
Action算子有如下几类:生成标量,如count(返回RDD中元素的个数)、reduce、fold/aggregate(见 Scala同名算子文档);返回几个标量,如take(返回前几个元素);生成Scala集合类型,如collect(把RDD中的所有元素倒入 Scala集合类型)、lookup(查找对应key的所有值);写入存储,如与前文textFile对应的saveAsText-File。还有一个检 查点算子checkpoint。当Lineage特别长时(这在图计算中时常发生),出错时重新执行整个序列要很长时间,可以主动调用 checkpoint把当前数据写入稳定存储,作为检查点。
这里有两个设计要点。首先是lazy evaluation。熟悉编译的都知道,编译器能看到的scope越大,优化的机会就越多。Spark虽然没有编译,但调度器实际上对DAG做了线性复 杂度的优化。尤其是当Spark上面有多种计算范式混合时,调度器可以打破不同范式代码的边界进行全局调度和优化。下面的例子中把Shark的SQL代码 和Spark的机器学习代码混在了一起。各部分代码翻译到底层RDD后,融合成一个大的DAG,这样可以获得更多的全局优化机会。
参考文章:基于Spark的大数据混合计算模式应用与研究








 本文深入探讨Spark的重要知识点,包括官方定义、体系结构、关键概念解析和生态系统。重点阐述了RDD的变换算子,如map、flatMap、filter、groupByKey等,以及lazy evaluation和Lineage的概念。同时,解释了行动算子的作用,如count、reduce、collect等,并讨论了检查点在长Lineage中的重要性。Spark的这种设计提供了高效的分布式计算优化。
本文深入探讨Spark的重要知识点,包括官方定义、体系结构、关键概念解析和生态系统。重点阐述了RDD的变换算子,如map、flatMap、filter、groupByKey等,以及lazy evaluation和Lineage的概念。同时,解释了行动算子的作用,如count、reduce、collect等,并讨论了检查点在长Lineage中的重要性。Spark的这种设计提供了高效的分布式计算优化。

















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









