







文章(VLDB‘2010)
该文章提出了对Hadoop的修改,使之能够适用于迭代计算,将原生的Hadoop中每一个job中一个map-reduce对改成多个map-reduce对,这样job就可以复用(如果不复用,每一个job完成之后都会把reduce的结果写进Hdfs文件,同时启动新的job时会从Hdfs中读文件,造成I/O压力),实现了在job内就可以控制迭代,同时由于迭代计算本身的特性(不变的数据invariant data会多次复用,而且变的数据比不变的数据要小很多),将invariant data缓存(cache)起来,进一步减少了I/O,使得迭代的效率更高。
下面架构图:
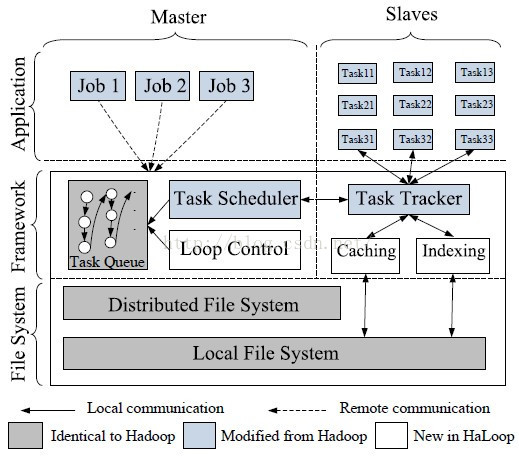
与Hadoop比较的四点改变:
1.提供了一套新的编程接口,更加适用于迭代计算;
HaLoop给迭代计算一个抽象的递归公式:
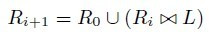
循环控制在Hadoop中是在job间的,因为Hadoop的一个job只能是一个map-reduce对,迭代计算需要多次map-reduce,因此需要启动多个job,而且每个job完成之后需要进行判断,而判断的时候需要从hdfs中读取reduce的结果文件,这样又要启动额外的任务,因此HaLoop将其做了修改,一个job中可以有多个map-reduce对,而且提供了判断接口,这样不需要再启动额外的任务来判断迭代是否结束,下图说明了Hadoop与HaLoop的不同:
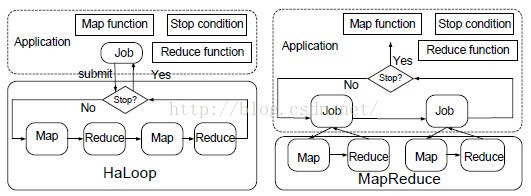
a.设置相邻两次迭代计算的差值门限(threshold)
b.设置迭代的最大次数
3.Task Scheduler也进行了修改,使得任务能够尽量满足data locality(尽量本地计算对HaLoop来说非常重要,否则Cache没有任何用处,还是得耗费网络I/O),除此之外应该让两次迭代的任务尽量使用相同的数据。
下图很清楚地说明了如果能够满足任务使用相同数据时的好处:
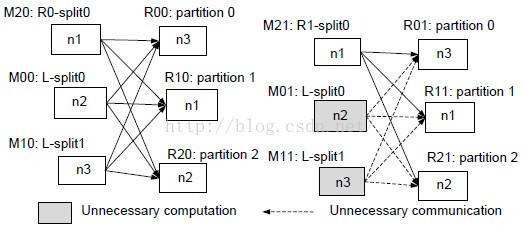
该job一共有三个map任务,三个reduce任务,分布在三个节点上,对于map任务,在n2,n3中运行,数据都是邻接表(linkage table),这是静态数据(invariant data),而R也即迭代的中间数据则在n1上运行,这是动态数据(variant data)。上一次迭代完成后,进入下一个迭代环节,如果我们依然用n2,n3节点计算L邻接表的数据,而n1计算Ri中的数据,这样我们就不需要再将n2,n3的map结果传给reduce,因为跟上次的结果是一样的,只需要将n1的计算结果传到后面。
4.slave nodes对数据进行cache并index索引,索引也以文件的形式保存在本地磁盘。
slave的cache有:
a.Reduce input cache:这样cache之后,如果上次的Map output跟这次的一样,就不用网络I/O,直接从磁盘I/O进内存。
b.Reduce output cache:用于判断迭代的终止。
c.Map input cache:如果这一次的计算是网路I/O得到的数据,则将其cache起来方便下次使用。
总结HaLoop的缺点:
1.静态数据与动态数据不能完全分离;
2.迭代的终止条件不能准确判断;
3.抽象度不够高。














 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









