







这篇文章是武汉大学张良培教授的深度学习处理遥感影像处理的入门教程论文。
Deep Learning forRemote Sensing Data
Liangpei Zhang
DL在RS领域有非常好的发展前景,传统方法人工提取特征,无法在discriminability和鲁棒性之间达到平衡。
以场景识别为例, 在 DL 的帮助下, 场景可以通过利用低级特征捕获的局部空间安排和结构模式的变化来表示为酉变换, 而不需要分割阶段或单独的对象提取阶段。
问题?
尽管有巨大的潜力, DL 不能直接用于许多 RS 任务, 其中一个障碍是大量的频带。一些遥感图像, 特别是高光谱的, 包含数以百计的波段, 可以导致一个小块输入是一个真正的大数据立方体, 对应于大量的神经元在一个 pretrained 网络。除了每个波段内的视觉几何图案外, 跨波段的光谱曲线向量也是重要的信息。然而, 如何利用这些信息还需要进一步的研究。高分辨率遥感图像中仍然存在问题, 它们只有绿色、红色和蓝色通道, 与 DL 的基准数据集相同。在实践中, 很少有标记样本可用, 这可能使 pretrained 网络难以构建。此外, 不同传感器获取的图像存在较大差异。如何将 pretrained 网络传输到其他图像尚不得而知。
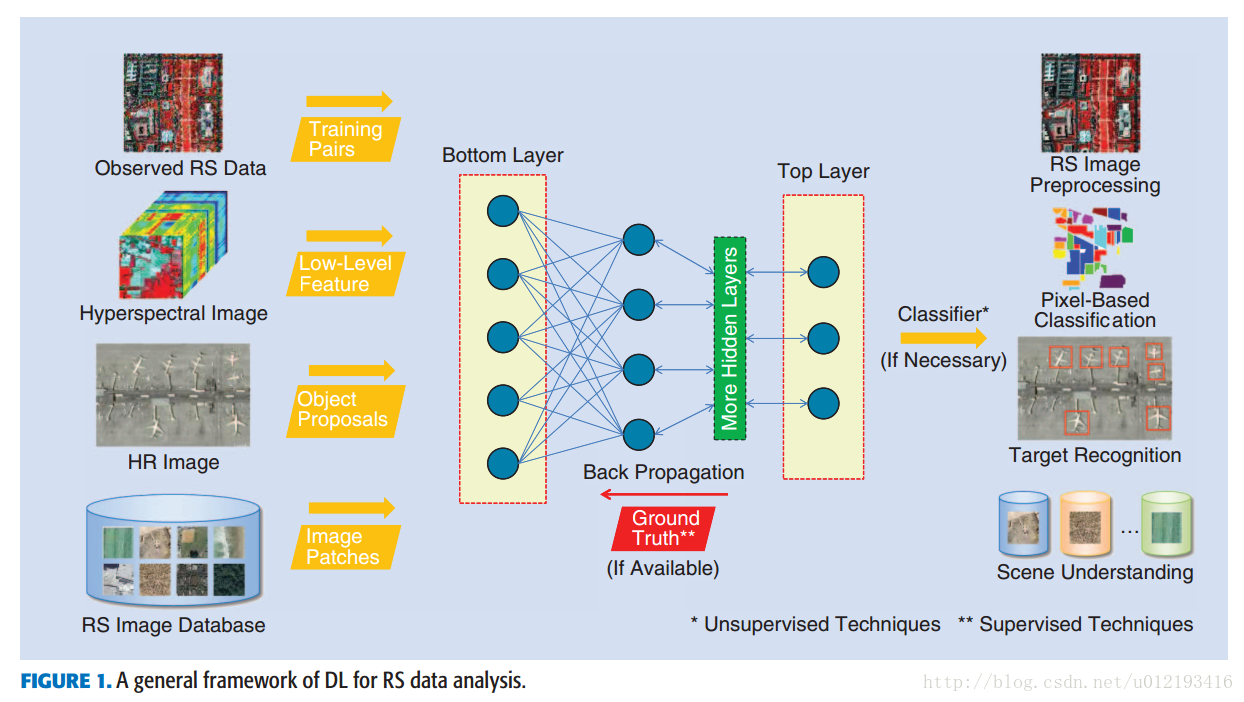
上图就是处理遥感数据信息的深度学习框架。
算法介绍:
卷积神经网络:卷积层、激活函数、池化层
自编码器(autoencoder)
RBM
稀疏编码
Antoencoder是encoder和decoder的结合,它既可以理解成对原图像一次降维,也可以理解成是训练整个深层神经网络的一种预先训练方法,是无监督学习,不需要labels,之后可以接分类器进行分类(就是我之前看的那篇论文的思路)
SAE就是稀疏自编码器(系数是一种优化方法)
是最优化输入数据和重构数据之间的误差
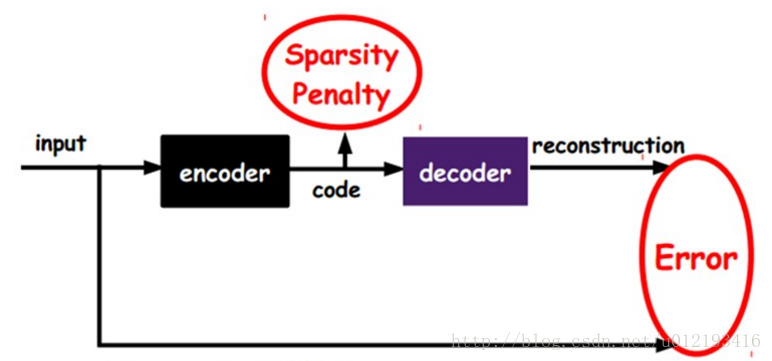
RBM反复堆叠就是DBN,误差函数就是能量函数,有两层,输入层和隐藏层。
稀疏编码:它是把大多数的神经元限制为0,只允许少量的神经元激活,来达到“稀疏”的效果。这主要是为了模拟人眼视觉细胞的特性。在算法里,其实就是在用来优化的目标函数里面加入一个表示稀疏的正则项,一般可以通过L1范数或者KL divergence来实现。稀疏性可以加到autoencoder上,也可以加到RBM上。
Deep Learning for remote sensingimage
根据相关的 rs 文献, 目前遥感图像去噪、模糊、超和泛锐化的方法大多基于信号处理社会中的标准图像处理技术, 而机器学习技术却很少。
RemoteSensing Image Preprocessing
restorationand denoising(恢复和去噪)
Pan Sharpening(锐化):超分辨率图像融合技术

proposed anew pan-sharpening method for RS image preprocessing that used a stackedmodified sparse denoising AE (S-MSDA) to train the relationship between HR (Highresolution)and LR(Low resolution) image patches
Pixed-BaesdClassfication
传统分类方法人工特征描述、判别性特征学习、强有力的分类器设计。但是从深度学习角度来看,传统方法只提取到浅层特征,鲁棒性不够。采用基于像素的分类。
Significantprogress has been achieved in recent years, e.g. in the aspects of handcraftedfeature description, discriminative feature learning and powerful classifierdesigning. However, from the DL point of view, most of the existing methods canextract only shallow features of the original data (the classification step canalso be treated as the top level of the network), which is not robust enoughfor the classification task. DL-based pixel classification for RS imagesinvolves constructing a DL architecture for the pixel-wise data representationand classification. By adopting DL techniques, it is possible to extract morerobust and abstract feature representations and thus improve the classificationaccuracy.
三个步骤:
1. input data空间、光谱、空谱联合
2. A deepnetwork structure 可以是有监督学习,也可以是无监督学习(AES、DBNS)
3. 分类器:硬分类器SVM,输出整数,即类别;软分类器logistic回归,输出概率值
Spectralfeature classification(光谱)
AE+SVM
AE+logisticregression
Classificationwith spatiial information
波段太多,用PCA降维,空间居然被搞成一维输入到DL network中去。
空谱联合DCNNs
TargetRecognition
由于RS图像背景复杂,所以并没有什么特别好传统方法来实现目标检测
在目标中提取特征,DL算法可以提取高频率的低级特征,例如边缘、外形和对象的轮廓, 无论目标的形状、大小、颜色或旋转角度如何。这种类型的算法还可以从输入图像或patches中学习分层表示, 例如, 由较低级别特征复合的对象部分, 从而识别 RS 目标的判别和健壮性。
General deep-learning framework of remote sensing target recognition
两种方法:有监督和无监督,但是都可以被统一在以下这个方案里。
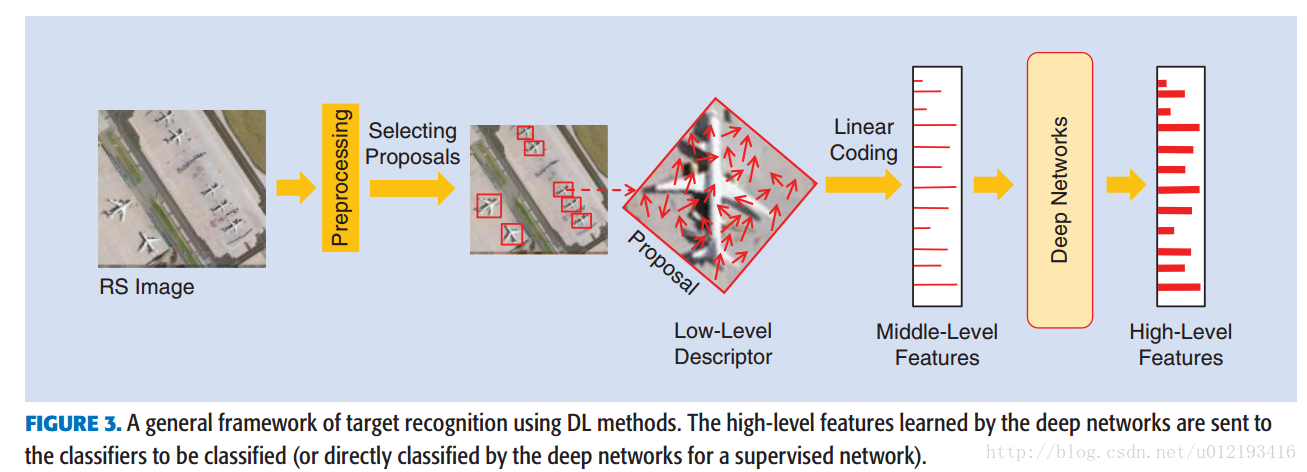
预处理:
1.计算均值和方差,转化成灰度图处理
2.计算梯度图,在一定阈值下,
生成包含检测对象的定位边框proposal
在边框中实现一个简单的特征提取,提取位移、旋转、尺度的不变性这样的低级特征,接着提取中级特征,当然这一步不是必要的,但比直接使用原始像素输入神经网络效果好。
深度神经网络是分级模型,可以从浅层中学习特征,在深层中自动学习高层特征。
从proposals中学习到判别和稳健的表示后,用SVM分类
当一个新的proposal在新图像中生成时,这个框架可以自动的学习高层特征,然后交由分类器去判断proposal是不是要检测目标。
Sampleselection proposals
选择包含目标proposal,理想情况就是目标位于定位边框中央。
选择proposal:1.滑动窗口,但是目标太多的话,效率低下
2.目标定位,粗略锁定目标位置,有效减少proposal数目
Low-tomiddle-level feature learning
将低级特征描述符输入神经网络可以加速深度网络,只不过只能获取有限空间几何特征会减低分类准确率,所以引入一个中级特征描述符效果好一点
Traningthe deep-learning networks
尽管中级特征从低级特征描述符中获取了结构信息,防止周围区域元素相关性的干扰,但是依然无法很好提供足够的特征描述和在巨大变化之下的背景中对目标对象的识别能力。
总的来说:1.监督学习 2.无监督学习
Supervisedmethods
CNN:分层模型,把输入图像转变成特征图,高层特征代表原始输入数据
MLP:转变成一维向量,在经过fc之后,就生成最终的代表向量。
监督神经网络输入二维向量对一个目标前测对象而言。训练阶段,用正负样本训练权重和核函数,在测试阶段,从新的RS图像中提取的propsal经过模型输出联系的概率值。
但是对于大尺寸的变化,训练CNN提取多尺度的特征描述是必要的。
HDNN: Theinput of the HDNN with L convolutional layers is a gray image. The image isfiltered by the filters in the first convolutional layers f1 to get the featuremaps C1,which are then subsampled by the first max-pooling layer to select therepresentative features as well as reduce the number of parameters to beprocessed. After transferring the L layers’ activations or feature maps, thefinal convolutional feature maps of the Lth layer CL are generated. In thearchitecture of the conventional CNNs, the final layer is followed by somefully connected layers and finally the classification layer.
但是这样无法充分利用特征和滤波器,卷积层是固定的,无法提取多尺度的特征。
1. 加深网络,但是消耗资源
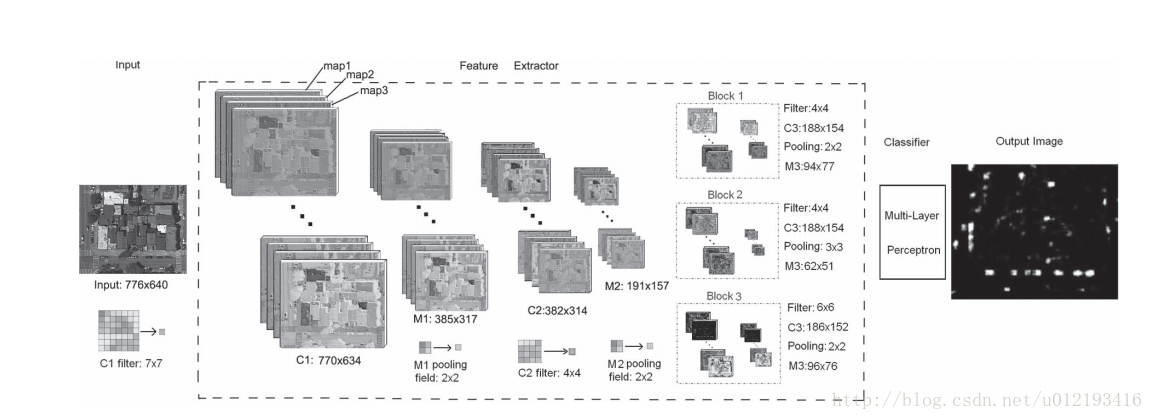
2. Anotherway is to use a multiscale receptive field size that can train filters withdifferent sizes and generate multiscale feature maps.
下图是DCNN多尺度特征提取的典型。
UpsupervisedMethods
高质量的带labels的遥感影像数据的缺乏,所以用少量labels的patches训练,用无labels的图像进行特征提取。
RBM、Sparse coding、AE、KNN、Guassian Mixture Model
都可以堆叠成深度无监督模型,其中RBM堆成DBN
DBN类似于anto-encoder,是无监督学习模型,用来聚类或者降维
Sceneunderstanding
高分辨率遥感影像1.数据量巨大2.地物类型以及混合复杂 使其成为遥感领域具有挑战性的课题。
Thissuggests that recognizing and analyzing scenes from VHR images should havemultiple trainable feature-extraction stages stacked on top of each other, andwe should learn the hierarchical internal feature representations from theimage.
1. Patchextraction
2. Featureextraction
3. Featurerepresentation
4. Classification
无监督学习算法通常是在强度和颜色信息上操作。
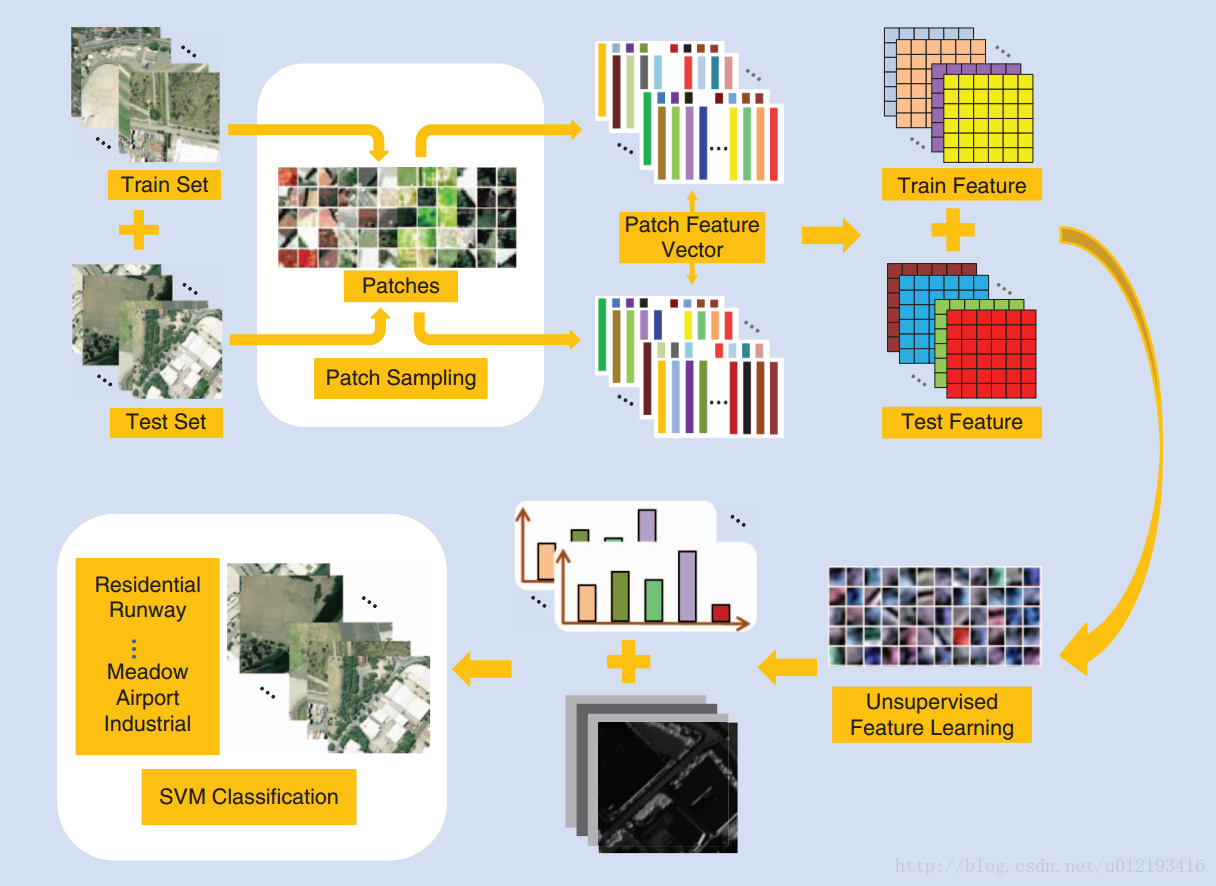
supervised hierarchicalfeature-learning-based method
properinitialization 良好的梯度下降和激活函数来传达有用的信息,高质量的标签数据
LDA 主题词法 词袋模型
梯度加速随机卷积模型
预训练模型
多尺度输入策模型
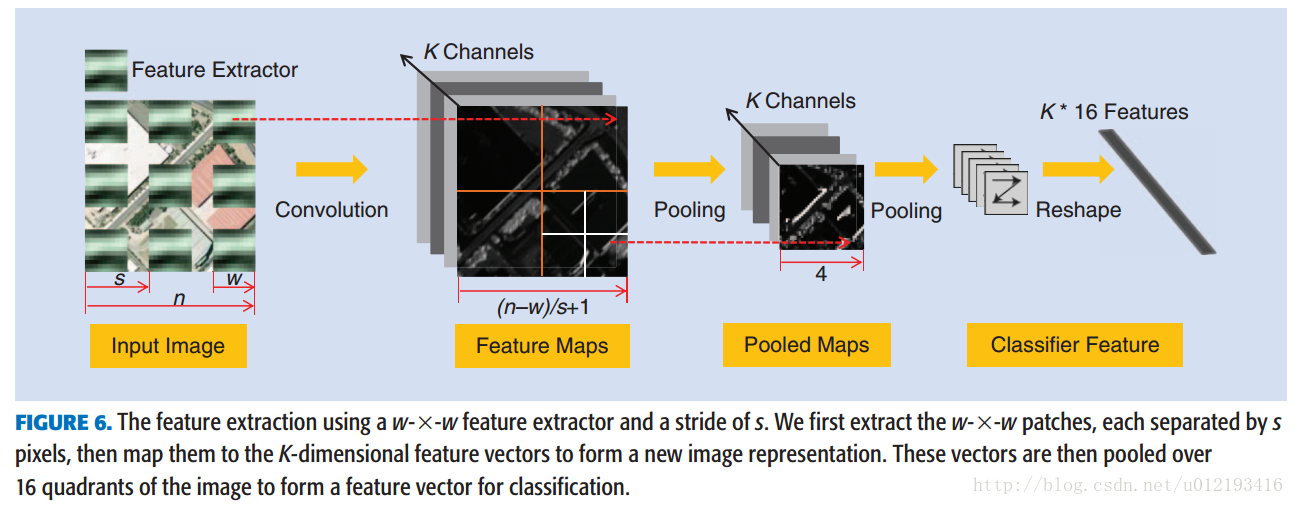
Experiments and analysis
UC-merced21类 RCNet 94.53%
Sydneydata set RCNet 97.78%
Conclusions and future work
深度学习方法也是最近刚刚应用到遥感影像处理上的,由于传统方法只能提取浅层特征,而深度学习方法可以提取高层特征,非常具有优势。
问题:
1. 缺乏高质量带标签的训练集
2. 遥感影像本身的复杂性,同一张图上有很多不同类型的objects
3. 缺乏可以迁移的遥感影像数据集。
4. 网络深度问题,越深学习到的分布特征越多,自然越好,但容易过拟合,而且训练集缺乏,所以要兼顾深度还有处理效率即时间的问题。















 1022
1022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









