







k-means原理与论文点评
--------------k-means原理--------------
区分两个概念:
hard clustering:一个文档要么属于类w,要么不属于类w,即文档对确定的类w是二值的1或0。
soft clustering:一个文档可以属于类w1,同时也可以属于w2,而且文档属于一个类的值不是0或1,可以是0.3这样的小数。
K-Means就是一种hard clustering,所谓K-means里的K就是我们要事先指定分类的个数,即K个。
k-means算法的流程如下:
1)从N个文档随机选取K个文档作为初始质心
2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类
3)重新计算已经得到的各个类的质心
4)迭代2~3步直至满足既定的条件,算法结束
在K-means算法里所有的文档都必须向量化,n个文档的质心可以认为是这n个向量的中心,计算方法如下:
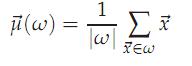
这里加入一个方差RSS的概念:
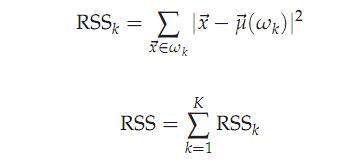
RSSk的值是类k中每个文档到质心的距离,RSS是所有k个类的RSS值的和。
算法结束条件:
1)给定一个迭代次数,达到这个次数就停止,这好像不是一个好建议。
2)k个质心应该达到收敛,即第n次计算出的n个质心在第n+1次迭代时候位置不变。
3)n个文档达到收敛,即第n次计算出的n个文档分类和在第n+1次迭代时候文档分类结果相同。
4)RSS值小于一个阀值,实际中往往把这个条件结合条件1使用
回过头用RSS讨论质心的计算方法是否合理
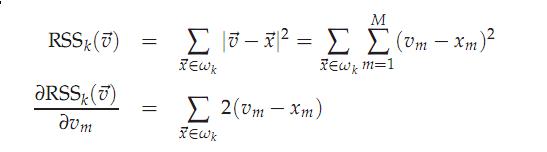
为了取得RSS的极小值,RSS对质心求偏导数应该为0,所以得到质心
可见,这个质心的选择是合乎数学原理的。
K-means方法的缺点是聚类结果依赖于初始选择的几个质点位置,看下面这个例子:

如果使用2-means方法,初始选择d2和d5那么得到的聚类结果就是{d1,d2,d3}{d4,d5,d6},这不是一个合理的聚类结果
解决这种初始种子问题的方案:
1)去处一些游离在外层的文档后再选择
2)多选一些种子,取结果好的(RSS小)的K个类继续算法
3)用层次聚类的方法选择种子。我认为这不是一个合适的方法,因为对初始N个文档进行层次聚类代价非常高。
以上的讨论都是基于K是已知的,但是我们怎么能从随机的文档集合中选择这个k值呢?
我们可以对k去1~N分别执行k-means,得到RSS关于K的函数下图:

当RSS由显著下降到不是那么显著下降的K值就可以作为最终的K,如图可以选择4或9。
---------对《Learning Feature Representations with K-means》的总结---------
自从Deep Learning之风盛起之时到现在,江湖上诞生了很多都可以从无标签数据中学习到深度的分级的特征的算法。大部分情况,这些算法都涉及到一个多层网络,而训练和调整这个网络需要很多tricks。最近,我们发现K-means聚类算法也可以被作为一个非常快的训练方法。它的优点是快!容易实现!当然了,K-means也不是万能神丹,它也存在自身的局限性。在本文中,我们就关注K-means的方方面面。总结了最近的K-means算法的效果和介绍使用k-means来有效地学习图像的特征的一些技巧。
一、概述
非监督学习的一般流程是:先从一组无标签数据中学习特征,然后用学习到的特征提取函数去提取有标签数据特征,然后再进行分类器的训练和分类。之前说到,一般的非监督学习算法都存在很多hyper-parameters需要调整。而,最近我们发现对于上面同样的非监督学习流程中,用K-means聚类算法来实现特征学习,也可以达到非常好的效果,有时候还能达到state-of-the-art的效果。亮瞎了凡人之俗眼。
托“bag of features ”的福,K-means其实在特征学习领域也已经略有名气。今天我们就不要花时间迷失在其往日的光芒中了。在这里,我们只关注,如果要K-means算法在一个特征学习系统中发挥良好的性能需要考虑哪些因素。这里的特征学习系统和其他的Deep Learning算法一样:直接从原始的输入(像素灰度值)中学习并构建多层的分级的特征。另外,我们还分析了K-means算法与江湖中其他知名的特征学习算法的千丝万缕的联系(天下武功出少林,哈哈)。
经典的K-means聚类算法通过最小化数据点和最近邻中心的距离来寻找各个类中心。江湖中还有个别名,叫“矢量量化vector quantization”(这个在我的博客上也有提到)。我们可以把K-means当成是在构建一个字典D∊Rnxk,通过最小化重构误差,一个数据样本x(i) ∊Rn可以通过这个字典映射为一个k维的码矢量。所以K-means实际上就是寻找D的一个过程:
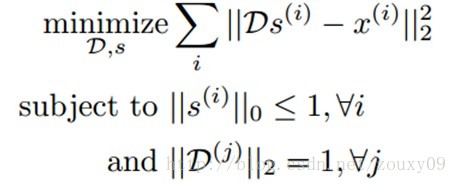
这里,s(i)就是一个与输入x(i)对应的码矢量。D(j)是字典D的第j列。K-means毕生的目标就是寻找满足上面这些条件的一个字典D和每个样本x(i)对应的码矢量s(i)。我们一起来分析下这些条件。首先,给定字典D和码矢量s(i),我们需要能很好的重构原始的输入x(i)。数学的表达是最小化x(i)和它的重构D s(i)。这个目标函数的优化需要满足两个约束。首先,|| s(i)||0<=1,意味着每个码矢量s(i)被约束为最多只有一个非零元素。所以我们寻找一个x(i)对应的新的表达,这个新的表达不仅需要更好的保留x(i)的信息,还需要尽可能的简单。第二个约束要求字典的每列都是单位长度,防止字典中的元素或者特征变得任意大或者任意小。否则,我们就可以随意的放缩D(j)和对应的码矢量,这样一点用都木有。
这个算法从精神层面与其他学习有效编码的算法很相似,例如sparse coding:
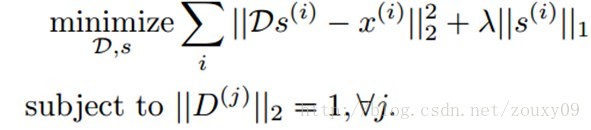
Sparse coding也是优化同样类型的重构。但对于编码复杂度的约束是通过在代价函数中增加一个惩罚项λ|| s(i)||1,以限制s(i)是稀疏的。这个约束和K-means的差不多,但它允许多于一个非零值。在保证s(i)简单的基础上,可以更准确的描述x(i)。
虽然Sparse coding比K-means性能要好,但是Sparse coding需要对每个s(i)重复的求解一个凸优化问题,当拓展到大规模数据的时候,这个优化问题是非常昂贵的。但对于K-means来说,对s(i)的优化求解就简单很多了:
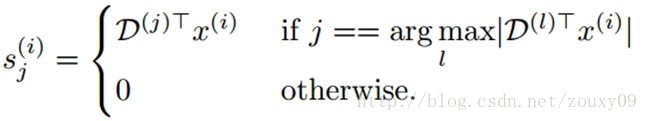
这个求解是很快的,而且给定s求解D也很容易,所以我们可以通过交互的优化D和s(可以了解下我博客上的EM算法的博文)来快速的训练一个非常大的字典。另外,K-means还有一个让人青睐的地方是,它只有一个参数需要调整,也就是要聚类的中心的个数k。
二、数据、预处理和初始化
这里我们采用的是包含很多小的图像patches的数据集,每个patch是16x16的灰度图,对每个patch样本我们将其拉成一个256维的列向量。这些patches可以在无标签图像中随机的裁剪得到。为了建立一个“完备complete”的字典(至少有256个类中心的字典),我们需要保证有足够的用以训练的patches,这样每个聚类才会包含一定合理数量的输入样本。对于16x16的灰度patch来说,样本数m=100,000个是足够的。实际上,训练一个k-means字典比其他的算法(例如sparse coding)需要的训练样本个数要多,因为在k-means中,一个样本数据只会贡献于一个聚类的中心,换句话说一个样本只能属于一个类,与其他类就毫无瓜葛了,该样本的信息全部倾注给了它的归宿(对应类的中心)。
2.1、预处理 Pre-processing
在训练之前,我们需要对所有的训练样本patches先进行亮度和对比度的归一化。具体做法是,对每个样本,我们减去灰度的均值和除以标准差。另外,在除以标准差的时候,为了避免分母为0和压制噪声,我们给标准差增加一个小的常数。对于[0, 255]范围的灰度图,给方差加10一般是ok的:
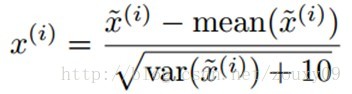
对训练数据进行归一化后,我们就可以在上面运行k-means算法以获得相应的聚类中心了(字典D的每一列),可视化在图a中,可以看到,k-means趋向于学习到低频的类边缘的聚类中心。但不幸的是,这样的特征不会有比较好的识别效果,因为邻域像素的相关性(图像的低频变化)会很强。这样K-means就会产生很多高度相关的聚类中心。而不是分散开聚类中心以更均匀的展开训练数据。所以我们需要先用白化来去除数据的相关性,以驱使K-means在正交方向上分配更多的聚类中心。

图a是由k-means从没有经过白化处理的自然图像中学习到的聚类中心。图b展示了没有和有白化的效果。左边是没有经过白化的,因为数据存在相关性,所以聚类中心会跑偏。右边是经过白化后的,可以看到聚类中心是更加正交的,这样学习到的特征才会不一样。图c展示的是从经过白化后的图像patches学习到的聚类中心。
实现whitening白化一个比较简单的方法是ZCA白化(可以参考UFLDL)。我们先对数据点x的协方差矩阵进行特征值分解cov(x)=VDVT。然后白化后的点可以表示为:
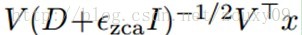
ɛzca是一个很小的常数。对于对比度归一化后的数据,对16x16的patch,可以设ɛzca=0.01,对8x8的patch,可以设ɛzca=0.1 。需要注意的一点是,这个常数不能太小,如果太小会加强数据的高频噪声,会使特征学习更加困难。另外,因为数据的旋转对K-means没有影响,所以可以使用其他的白化变换方法,例如PCA白化(与ZCA不同只在于其旋转了一个角度)。
在白化后的数据中运行k-means可以得到清晰的边缘特征。这些特征和sparse coding啊,ICA啊等等方法学到的初级特征差不多。如图c所示。另外,对于新的数据,可能需要调整归一化的参数ɛ和白化的参数ɛzca,以满足好的效果(例如,图像patches具有高对比度,低噪声和少低频波动)。
2.2、初始化 Initialization
一般的K-means聚类算法存在一个比较常见的问题,就是会出现空的聚类。通俗的讲,就是它聚类后的一个类里面居然没有样本(接近于没有)。那么很明显,这个类就一点意义都没有,留着反而还会危害人间。这我们当然得做些努力来避免这种情况的发生了。那就得找原因了吧。其实这一定情况下可以认为是中心的初始化的不恰当导致的。常用的中心初始化方法就是随机地从样本中挑k个出来作为k个初始的聚类中心。但这不是个明智的选择。它有可能会导致图像趋于稠密聚集某些区域,因为如果随机选择的patches,也就是训练样本本身就在某个区域分布非常密,那么我们随机去选择聚类中心的时候,就会出现就在这个数据分布密集的地方被选出了很多的聚类中心(因为原数据分布密集,所以被选中的概率会大)。这是不好的,因为本身这个密集的区域,一个聚类中心才是好的,你硬搞出几个聚类中心,好好的队伍就会被强拆了,还搞得其他比较分散的数据点找不到归宿,因为聚类中心离它好遥远,大部分的聚类中心都让富二代给占有了,社会资源分配不当啊,哈哈。这样还会出现一种情况,就是如果样本分布密集的话,它们都几乎从属于一个聚类中心,那么其他聚类中心就几乎没有样本属于它。这样也不好。所以,一个比较好的初始化方式就是从一个正态分布中随机初始化聚类中心,然后归一化他们到单位长度。另外,因为经过了白化的阶段,我们期望我们的数据的主要成分已经在一定程度上被组织为球面spherical分布了,而在一个球面上随机地选取一些向量结果就显得温柔多了。
另外,还存在一些启发性的方法去改善k-means的这个问题。例如启发性得重新初始化空的聚类中心。实践中证明,这种方法对图像数据的效果比较好。当空类出现的时候,我们再随机挑选样本来替代这个空类中心,一般都是足够有效的。但好像一般也没啥必要。事实上,对于一个足够规模的实现来说,我们会训练很多的聚类中心,如果一个聚类中心包含的数据点太少了,我们直接抛弃它就好了,不要这个聚类中心了,因为俺们的聚类中心够多,多你一个不多,少你一个不少的。
还有一种改善的方法叫做聚类中心的抑制更新damped updates。它在每次的迭代中,都会根据以下方式更新聚类中心:
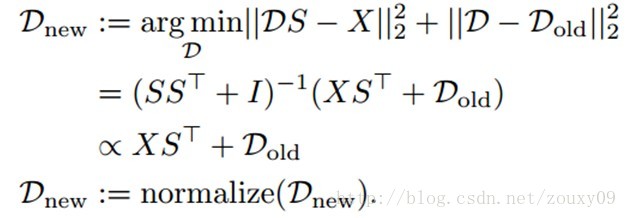
需要注意的是,这种形式的抑制并不会对“大”的聚类有很大的影响(因为XST的第j列会比Dold的第j列要大得多),它只能防止小的聚类在一次的迭代过程中被拉得太远(就像滤波的方法一样,新的值不仅受当前值的影响,还受历史值的影响,这样就会防止这个值出现突变。例如a_old=1,新的值为5,那么a_new=0.5*5+0.5*a_old=3,也就是a_new会跳到3而不是一下子跳到5,当然还取决于前面的权值0.5,看我们更信任新值还是历史值。但如果新值很大,那就没有特别大的效果了。例如新值为99,那么a_new=50,它还是比a_old=1要大多了)。我们将这个k-means训练算法概括如下:

三、与稀疏特征学习的比较
上面我们提到,K-means能像ICA,sparse coding一样学习到方向性的边缘特征。那我们会怀疑,这是偶然吗(因为边缘太常见了,所以一般的学习模型都可以发现它们)?!还是说这隐含着K-means本身就具有和ICA相似的稀疏分解的能力。因为每个s(i)只能包含一个非零元素(相应的聚类中心),所以k-means会尝试去学习一个可以很好的描述整个输入图像的聚类中心。因此,它也无法保证一定可以学到和ICA或者sparse coding学到的滤波器一样。这些算法可以学习到真正的“分布式”描述,因为一张图像可以通过一个字典的几列来联合描述,而不是只通过一列。尽管如此,k-means在天时地利人和的时候依然能发现数据的稀疏投影,虽然作为一个聚类方法它好像没有明确的通过公式告诉我们它还能做这个。所以我们看到的结果也不是幻觉或者偶然。
虽然k-means和ICA和sparse coding有着经验性的相似,但它有一个很大的缺点:它发现数据稀疏投影方向的能力很大程度上取决于输入数据的维数和数量。如果数据的维数增加,我们就需要增加大量的样本,才能得到好的结果。这点就比较难伺候了。例如,在实验中,对64x64的patch,我们用了500,000个样本来训练k-means,结果还是很烂。我们只学习到了很少的边缘。在这种情况下,就会存在很多的接近空数据点的聚类,所以就需要非常多的数据才能让k-means发挥光与热。所以,这就存在一个折衷了,是否要采用k-means,就要看我们的数据有多少维,我们能提供多少数据(一般要达到相同的结果,比sparse coding要多很多)。对于适当的维度(例如100维),使用k-means的训练速度比其他算法快那么多,那么我情愿花点力气去提供更多的样本给它。但对于很高维的数据,采用其他算法例如sparse coding会比k-means性能要好,甚至速度也要更快。
4、在图像识别上的应用
在这里没什么好说的,k-means就作为一种学习特征的方法,取代一般的非监督学习过程里面的特征学习那块就好了。可以参考UFLDL中的“卷积特征提取”和“池化”。另外,文中也介绍了一些选择参数的方法,很多论文也可以看到,这里也不说了。这里比较有趣的一点是,文中说到,根据观测的结果,如果我们的识别系统设计有大量有效的有标签训练数据的话,那么选择一个简单的快速的前向编码器(特征映射函数)的话,效果都可以挺好。但如果我们的有标签训练数据不多,那么采用一个复杂的编码函数会更好。例如,在大规模情况下,采用软阈值非线性函数:
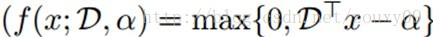
就可以工作的比较好。其中,ɑ是个可调的常数。相反,复杂的sigmoid非线性函数效果就没那么好了:
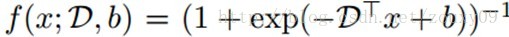
5、构建深度网络
在上面一个章节中,我们是先从一些无标签数据中随机提取一些patches,然后用k-means来学习其中的特征,得到一个字典。然后对于一个大的图像,我们用这个字典(特征提取器)去卷积图像的每个局部感受野,从而提取整幅图像的特征。然后我们再通过一个pooling步骤去对提取到的特征进行绛维。当然了,如果我们可以通过上面这些提取到的特征去学习更高层的特征,那就更好了。最简单的方法就是,对无标签数据集X中,我们通过上面的方法得到pooling后的特征后,然后得到新的数据集Z,我们再在这个数据库Z中用同样的特征学习过程去学习新的特征。从而得到第二层的特征。但这有个问题,就是这个Z一般都是非常高维的,所以需要用非常大的特征字典来学习(例如k=10000甚至更多)。但这样,对k-means的要求也高了,我们需要提供更多的样本来训练。
该文提出了一种pair-wise “dependency test"的方法来改善这个问题。我们通过一个“能量相关”来定义数据集Z中两个特征zj和zk的依赖性。我们需要在Z的特征表达之上学习更高级的特征。使用“dependency test",我们可以以一种相对简单的方式来选择合理的感受野:我们挑了一个特征z0,然后使用“dependency test"来寻找和z0具有很强依赖性的R特征。然后只用这R特征作为k-means算法的输入。如果我们选取的R足够小(例如100或者200),那么归一化和白化过后,再用k-means来训练一般都可以达到好的效果。因为输入的维数很小,所以我们只需要训练一百个左右的聚类中心,这样使用少量的训练样本就可以运行k-means了。
详细的算法介绍和效果见原论文。
六、总结
本文中,我们讨论了用k-means来搭建特征学习系统的一些关键点,现在总结如下:
1、需要先对数据进行均值和对比度的归一化。
2、使用白化来消去数据的相关性。注意白化参数的选择。
3、通过高斯噪声和归一化来初始化k-means的聚类中心。
4、使用抑制更新来避免空聚类和增加稳定性。
5、注意数据的维数和稀疏的影响。K-means通过寻找数据分布的”heavy-tailed"方向来找到输入数据的稀疏投影。但如果数据没有经过适当的白化,或者数据维数太高了,或者存在无效的数据,那么效果往往是不好的。
6、对于高维数据,k-means需要增加大量的样本来能得到好的效果。
7、一些外在的参数(例如pooling,编码方法的选择等等)对于系统性能的影响比学习算法本身要大。所以最好先化时间和成本在通过更多的交叉检验的方法来挑选好的参数比花更多的成本在学习算法上要明智的多。
8、对于图像识别来说,更多的聚类中心往往是有帮助的。当然,前提是我们要有足够的训练样本。
9、当有标签数据多的时候,采用一个简单的编码器。如果标签数据有限(例如每类只有百来个训练样本),那么采用一个复杂的编码器会更好。
10、尽可能地使用局部感受野。K-means是否成功,其瓶颈在于输入数据的维数。越低越好。如果无法手动的选择好的局部感受野,那么尝试去通过一个自动的依赖性测试dependency test来帮助从数据中挑选出一组低维的数据。这对于深度网络来说是很有必要的。
对论文《Learning Feature Representations with K-means》的点评:














 2785
2785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









