







Representation Learning: 《A Review and New Perspectives》
摘要
机器学习算法的成功主要取决于数据的表达data representation。我们一般猜测,不同的表达会混淆或者隐藏或多或少的可以解释数据不同变化的因素。尽管特定的领域知识可以有助于设计或者选择数据的表达,但通过一般的先验知识来学习表达也是有效的。而且,人工智能AI的要求也迫使我们去寻找更强大的特征学习算法去实现这些先验知识。
本文回顾非监督特征学习和深度学习领域的一些近期工作,包括概率模型的发展、自动编码机、流行学习和深度网络。通过这些分析,可以激发我们去思考一些长久以来尚未解决的问题,例如如何学习好的表达?如何选择适合的目标函数以便于计算表达?还有表达学习、密度估计和流行学习他们之间是否具有一定的几何联系?
1、介绍
众所周知,机器学习方法的性能很大程度上取决于数据表达(或者特征)的选择。也正是因为这个原因,为了使得机器学习算法有效,我们一般需要在数据的预处理和变换中倾注大部分的心血。这种特征工程的工作非常重要,但它费时费力,属于劳动密集型产业。这种弊端揭露了目前的学习算法的缺点:在提取和组织数据的区分性信息中显得无能为力。特征工程是一种利用人的智慧和先验知识来弥补上述缺点的方法。为了拓展机器学习的适用范围,我们需要降低学习算法对特征工程的依赖性。这样,就可以更快的构建新的应用,更重要的是,在人工智能AI领域迈出了一大步。人工智能最基本的能力就是能理解这个世界(understand the world around us)。我们觉得,只有当它能学会如何辨别和解开在观测到的低级感知数据中隐含的解释性因素时才能达到这个目标。
这篇文章主要讲述表达学习representation learning的,或者说学习一种数据的表达使得提取对构建分类器或者预测器有用的信息更加容易。以概率模型为例,一个好的表达总能捕捉观测输入数据的隐含解释性因素的后验概率分布。一个好的表达作为监督预测器的输入也是有用的。在表达学习的那么多不同的方法中,本文主要聚焦在深度学习方法:通过组合多个非线性变换,以得到更抽象和最终更有效的表达。这里,我们综述这个快速发展的领域,其中还会强调当前进展中的特定问题。我们认为,一些基本问题正在驱动该领域的研究。特别的,是什么导致一种表达优于另一种表达?我们应该怎样去计算它的表达,换句话来说就是,我们应该如何进行特征提取?还有就是为了学习好的表达,怎样的目标函数才是适合的?
2、我们为什么要关心表达学习?
表达学习(亦被江湖称作深度学习或者特征学习)已经在机器学习社区开辟了自己的江山,成为学术界的一个新宠。在一些顶尖会议例如NIPS和ICML中都有了自己的正规军(研究它的workshops),今年(2013)还专门为它搞了一个新的会议,叫ICLR(International Conference on Learning Representations),可见它在学术界得到的宠爱招人红眼。尽管depth(深度)是这个神话的一个主要部分,但其他的先验也不能被忽视,因为有时候,先验知识会为表达的学习献上一臂之力,画上点睛之笔,更容易地学习更好的表达,这在下一章节中将会详细讨论。在表达学习有关的学术活动中最迅速的进展就是它在学术界和工业界都得到了经验性的显著性的成功。下面我们简单的聚焦几点。
2.1、Speech Recognition and Signal Processing语音识别与信号处理
语音也是神经网络诞生时其最早的一个应用之一,例如卷积(或者时延)神经网络(Bengio在1993年的工作)。当然,在HMM在语音识别成功之后,神经网络也相对沉寂了不少。到现在,神经网络的复活、深度学习和表达学习的运用在语音识别领域可谓大展拳脚,重展雄风,在一些学术派和工业派人士(Dahlet al., 2010; Deng et al., 2010; Seide et al., 2011a; Mohamedet al., 2012; Dahl et al., 2012; Hinton et al., 2012)的努力下取得了突破性的成果,使得这些算法得到更大范围的应用,并且实现了产品化。例如,微软在2012年发布了它们的语音识别MAVIS (Microsoft Audio Video Indexing Service)系统的一个新版本,这个版本是基于深度学习的(Seide et al., 2011a)。对比现有的一直保持领先位置的高斯混合模型的声学建模方法,他们在四个主要的基准测试集中把错误率降低了30%左右(例如在RT03S数据库中从 27.4%的错误率降到18.5%)。在2012年,Dahl等人再次书学神话,他在一个小的大词汇量语音识别基准测试集中(Bing移动商业搜索数据库,语音长40小时)的错误率降到16%与23%之间。
表达学习算法还被应用的音乐方面上,在四个基准测试集中,比当前领先的polyphonic transcription (Boulanger-Lewandowskiet al., 2012)在错误率上取得了5%到30%之间的提升。深度学习还赢得了MIREX (Music Information Retrieval)音乐信息检索竞赛。例如2011年的音频标注audio tagging上(Hamelet al., 2011)。
2.2、Object Recognition目标识别
在2006年,深度学习的开始,主要聚焦在MNIST手写体图像分类问题上(Hinton et al.,2006; Bengioet al., 2007),它冲击了SVMs在这个数据集的霸主地位(1.4%的错误率)。最新的记录仍被深度网络占据着:Ciresanet al.(2012)声称他在这个任务的无约束版本(例如,使用卷积架构)的错误率是0.27%,为state-of-the-art。而Rifaiet al.(2011c)在MNIST的knowledge-free版本中保持着0.81%的错误率,为state-of-the-art。
在最近几年,深度学习将其目光从数字识别移到自然图像的目标识别,而最新的突破是在ImageNet数据库中把领先的26.1%的错误率拉低到15.3% (Krizhevskyet al., 2012)。
2.3、Natural Language Processing自然语言处理
除了语音识别,深度学习在自然语言处理中也有很多应用。symbolic 数据的分布式表达由Hinton在1986年引入,在2003年由Bengio等人在统计语言模型中得到第一次的发展,称为神经网络语言模型neural net language models (Bengio,2008)。它们都是基于学习一个关于每个单词的分布式表达,叫做word embedding。增加一个卷积架构,Collobertet al.(2011)开发了一个SENNA系统,它在语言建模、部分语音标记、chunking(节点识别)、语义角色标记和句法分解中共享表达。SENNA接近或者超于目前的在这些任务中的当前领先方法。但它比传统的预测器要简单和快速。学习word embeddings可以以某种方式与学习图像表达结合,这样就可以联系文本和图像。这个方法被成功运用到谷歌的图像搜索上,利用大量的数据来建立同一空间中图像与问题之间的映射(Weston et al.,2010)。在2012年,Srivastava等将其拓展到更深的多模表达。
神经网络语言模型也被通过在隐层中增加recurrence来改进(Mikolovet al., 2011)。改进效果比当下领先的平滑n-gram语言模型不仅在复杂度上降低,还降低了语音识别的错误率(因为语言模型是语音识别系统的一个重要组成部分)。这个模型还被应用到统计机器翻译上面 (Schwenk et al., 2012; Leet al., 2013),改进了复杂度和BLEU分数。递归自动编码机Recursive auto-encoders(产生recurrent网络)在全句释义检测full sentenceparaphrase detection上也达到了现有的领先水平,是以前技术的两倍F1分数(Socheret al., 2011a) 。表达学习还用到了单词歧义消除word sense disambiguation上(Bordeset al., 2012),取得了准确率从67.8% 到 70.2%的提升。最后,它还被成功运用到sentimentanalysis (Glorotet al., 2011b; Socher et al., 2011b)上,并超越现有技术。
2.4、Multi-Task and Transfer Learning, Domain Adaptation多任务和迁移学习,域自适应
迁移学习(传统的机器学习假设训练数据与测试数据服从相同的数据分布。如果我们有了大量的、在不同分布下的训练数据,完全丢弃这些数据也是非常浪费的。如何合理的利用这些数据就是迁移学习主要解决的问题。迁移学习可以从现有的数据中迁移知识,用来帮助将来的学习。迁移学习(Transfer Learning)的目标是将从一个环境中学到的知识用来帮助新环境中的学习任务。)是指一个学习算法可以利用不同学习任务之间的共性来共享统计的优点和在任务间迁移知识。如下面的讨论,我们假设表达学习算法具有这样的能力,因为它可以学习到能捕捉隐含因素的子集的表达,这个子集是对每个特定的任务相关的。如图1所示。这个假设被很多的经验性结果所验证,并且展现了表达学习在迁移学习场合中同样具有优异的能力。
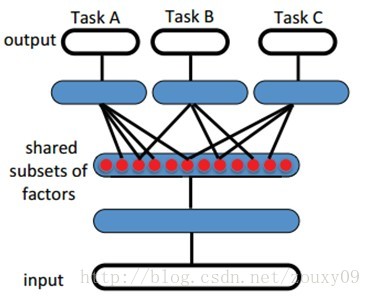
图1:表达学习发现了隐含的解释性因素(中间隐层红色的点)的示意图。一些解释了输入(半监督设置),一些解释了每个任务的目标。因为这些子集间会重叠,所以会贡献统计的优点,利于generalization泛化。















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









