









一、引言
这是一道好题!
为什么这么说,这道题分析出来思路或许就花了我 15 分钟;写出第一个版本的代码花了将近 10 分钟;之后优化代码更是花了我很久很久的时间,中间还间隔着吃晚饭的时间,大概能有个一个小时;最后的最后,我写出了自认为最优的代码,却还是被最高票答案所折服(做了这么久可能还是自己水平不够吧,尽管如此,我还是尽力把这道题的精彩之处分析给大家看 ^_^)。
究竟是怎样的一道题呢?让我们看看题目:
Given a string which consists of lowercase or uppercase letters, find the length of the longest palindromes that can be built with those letters.
This is case sensitive, for exampleAais not considered a palindrome here.Note:
Assume the length of given string will not exceed 1,010.Example:
Input:
“abccccdd”Output:
7Explanation:
One longest palindrome that can be built is “dccaccd”, whose length is 7.
题目信息有点多,我简单翻译一下:
给定一个含有小写和大写字母的字符串,请找出能够用其中字母组成的最大的回文字符串的长度。
这里对大小写敏感,比如Aa就不是一个回文字符串。注意:
假设给定的字符串的长度不会超过 1010 。举例:
输入:
“abccccdd”输出:
7解析:
可以根据给定字符串的字母拼凑出最长的回文字符串之一 “dccaccd”,长度是 7。
这道题的关键词是:
palindrome
[ˈpælɪndroʊm]
n.回文(指顺读和倒读都一样的词语)
这里特意从百度翻译里粘贴出来,可以看到 palindrome 所代表的意思是 :
回文
那么什么叫做回文呢?根据题意,其实我们很容易理解,比如题目中给出的例子 dccaccd 就是一个回文字符串,也就是说:
不论从左边开始看,还是从右边开始看,都是一样的顺序的字符串,我们就称之为回文字符串
也就是说,这道题要我们能够从给定参数字符串中,找到其能够拼凑出来的最大的回文字符串的长度并且返回之。
充分理解了题意,接下来让我们一起分析分析,这道题该怎么做。
二、别动手:让我们好好思考思考
我们该如何甄别一个字符串是否是回文字符串的问题,已经在引言中总结出来了,也就是说:
不论从左边开始看,还是从右边开始看,都是一样的顺序的字符串,我们就称之为回文字符串
我们要在指定参数字符串之中,拼凑出这么一个具有“对称”结构的字符串。
以上仅仅只是一个定义,我们该如何“翻译”成题目中能够使用的判断条件呢?
其实分析问题,最好的办法就是举例:
例子1:
“abba”
这是出现次数为偶数的元素对称分布构成的回文字符串例子2:
“aba”
这是出现次数为奇数的元素居中、两边出现次数为偶数的元素分别对称分布的回文字符串
让我们看看上面两个例子,你还能找到除了这两个情况之外的回文字符串的构成结构了吗?
不能了。也就是说,上面的这两个例子,其实就已经涵盖了所有的回文字符串的构成情况了,也就是如图所示的:

我们构成一个回文字符串:
出现次数为奇数的元素:要么只能取 1 个,要么不取
出现次数为偶数的元素:可以全取,以中心为对称点对称分布
既然分析出来了回文字符串的构成,那么我们如何在指定的字符串中取出我们所需的最大的回文字符串呢?
例子3:
“bananas”
| 字母 | 出现次数 |
|---|---|
| a | 3 |
| n | 3 |
| s | 1 |
| b | 1 |
对于 bananas 字符串,我们看到,a 和 n 都出现了 3 次,根据我们上面的分析,出现次数为奇数的我们只能取 1 个,而为了达到最大回文字符串这个条件,我们肯定要取最大的一个奇数元素,这里我们就算取走 a 作为回文字符串的中心吧。
那么剩下的字符我们该如何取呢?为了达到最大的回文长度,而且我们又已经取走了奇数元素了,根据我们上面的分析,我们只能再取出现次数为偶数的元素了。那么怎么办呢?我们可以将 n 元素取最大的偶数值,也就是 2,此外, “bananas” 再无出现次数为偶数的元素了。
因此,我们取出了 3 个 a 和 2 个 n,拼凑出 “bananas” 的最大回文字符串:
“naaan”
相信这里通过我举出的 3 个例子,大家已经对于回文字符串的构成、指定字符串中取出最大回文字符串的方法都有了一定的理解。
为了下面写代码方便,这里我还总结了一个取最大回文字符串的结论:
1.出现次数为偶数的元素:全取
2.出现次数为奇数的元素:没有则不取;有则取出现次数最多的元素 1 个,其他出现次数为奇数的元素取最大的偶数值(原值 - 1)
三、开始动手:代码精简的渐进史
其实这道题的所有答案基本都绕不开上面我们分析的结论,就看谁的代码更加优雅了。
在我分析出来了上述的结论之后,略微思考了下,考虑到统计出现次数,果断拿出 std::unordered_map,大笔一挥,也就有了第一个版本的代码:
// my solution 1 , runtime = 19 ms
class Solution1 {
public:
int longestPalindrome(string s) {
unordered_map<char, int> char_count;
int sum_double = 0, max_single = 0;
char single_char = '\0';
for (auto c : s) ++char_count[c];
for (auto item : char_count)
if (item.second % 2 && item.second > max_single) {
max_single = item.second;
single_char = item.first;
}
for (auto item : char_count)
if (item.first != single_char)
sum_double += item.second % 2 ? item.second - 1 : item.second;
return sum_double + max_single;
}
};这份代码的逻辑还是比较清晰的,三个 for 循环的目的性很强:
第一个 for 循环:统计参数字符串中各字符的出现次数
第二个 for 循环:找到出现次数为奇数的并且出现次数最大的元素(这个元素必然被放到回文字符串中间)
第三个 for 循环:遍历统计出现次数的映射关系,除开第 2 步中我们找到的那个元素,其他元素全部按照最大偶数值取(出现次数为奇数的值 - 1,出现次数为偶数的取原值)
最后,只要返回我们计算的最大奇数出现次数的元素的出现次数与其他所有元素的出现次数的最大偶数值的和即可。
这份代码虽说逻辑非常清晰,完全按照我们第二个标题中分析的逻辑进行编写。但是我不满意,因为毕竟用到了 3 个循环,效率必然高不了(runtime = 19 ms)。
我重新整理了下思路,发现我根本没有必要去找到最大出现次数为奇数的元素,我只需要判断是否存在出现次数为奇数的元素即可,为什么这么说呢:
我只需要将给定字符串的统计关系中,所有的元素全部按照最大偶数出现次数的方式来取值,然后判断该字符串是否存在出现次数为奇数的元素,如果存在,则给最后的值 + 1(该出现次数为奇数的元素在回文字符串中居中),否则什么都不用做
于是,在这个思路的引导下,我写出了第二个版本的方法:
// my solution 2 , runtime = 9 ms
class Solution2 {
public:
int longestPalindrome(string s) {
unordered_map<char, int> char_count;
int sum = 0;
bool bHasSingleChar = false;
for (auto c : s) ++char_count[c];
for (auto item : char_count) {
if (item.second % 2) bHasSingleChar = true;
sum += item.second % 2 ? item.second - 1 : item.second;
}
return bHasSingleChar ? sum + 1 : sum;
}
};这个方法比第一个版本的方法少了一个 for 循环(所以 runtime 也降到了 6 ms),在第二次遍历的时候进行是否存在出现次数为奇数的元素的记录,最后再在返回的时候进行辨别。
做到了这个方法的我,思维已经停不下来了,我又转念一想,我何必要考虑将所有元素的出现次数相加呢?我只需要将所有的元素的出现次数加起来之后减去出现次数为奇数的元素个数 - 1 即可呀:
遍历整个统计出现次数的关系,全部相加得结果 sum
如果没有出现次数为奇数的元素,则直接返回第 1 个步骤的结果 sum;如果出现了,则记录出现次数为奇数的元素的个数 single ,最后的返回值就是 sum - (single - 1) ,之所以要减去出现次数奇数的元素,是因为他们(除了居中的那个值)都取值为最大偶数值了(原值 - 1),所以为 single - 1。
于是这个思路的代码如下:
// my solution 3 , runtime = 6 ms
class Solution3 {
public:
int longestPalindrome(string s) {
unordered_map<char, int> char_count;
int sum = 0, single = 0;
for (auto c : s) ++char_count[c];
for (auto item : char_count) {
sum += item.second;
if (item.second % 2) ++single;
}
return single ? sum - single + 1 : sum;
}
};此时此刻,思路开火车的我已经停不下来了,我为何要把所有的元素的出现次数相加呢?给定的字符串的长度不就是直接可以取到的参数吗:
参数字符串的长度就已经涵盖了所有元素的出现次数之和的条件了,我们只需要在其中减去出现次数为奇数的元素个数 - 1(同理,减的 1 是回文字符串居中的那个元素)
如何方便的记录字符串中出现次数为奇数的元素呢?不需要
std::unordered_map,我们只需要先将字符串排序,然后遍历一遍字符串,以开关变量的形式处理每一个字符,即可获得字符串中出现次数为奇数的元素个数
这个思路的代码如下:
// my solution 4 , runtime = 6 ms
class Solution {
public:
int longestPalindrome(string s) {
int sum = s.size(), single = 0, temp = 0;
sort(s.begin(), s.end());
for (auto c : s)
if (temp == c) temp = 0, --single;
else temp = c, ++single;
return single ? sum - single + 1 : sum;
}
};可以看到,这里我为了一遍遍历能够得到字符串中出现次数为奇数的元素的个数,我首先进行了排序,然后声明了一个变量 temp 用来记录上一个元素。我们仔细看看这个 temp 变量的使用:
当我们发现 temp 与当前遍历值不一样的时候,我们记录奇数元素值 -1,并且 temp 归 0
当我们发现 temp 与当前遍历值相同的时候,我们记录奇数元素值 + 1,并且 temp 等于当前值
也就是说,只要一个元素出现偶数次, single 就增加 n 次又减少 n 次,刚好没有影响;而一个元素出现奇数次,那么 single 最后的结果刚好为 + 1
这是一个非常巧妙的处理 :)
可以看到,从第一个版本的代码到最后一个版本的代码,尽管我们都是参考着同样的一个逻辑,却写出了不同的代码,这几份代码或使用了更多的循环,或使用了不同的计算公式。
你或许会问,我为什么要这么竭尽全力地去思考这么多方法。
我只是想让代码变得更加简洁而已 :)
四、丧心病狂:5 lines C++
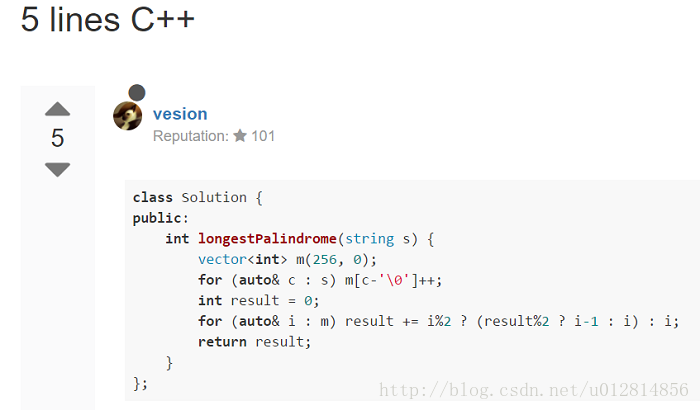
看到这个标题的我就已经很震惊了!
什么?!5行代码?要知道我那么拼命地降低代码量也才是第三个标题的 6 行代码而已 T_T
废话不多说,让我们好好膜拜下这份代码:
class Solution {
public:
int longestPalindrome(string s) {
vector<int> m(256, 0);
for (auto& c : s) m[c-'\0']++;
int result = 0;
for (auto& i : m) result += i%2 ? (result%2 ? i-1 : i) : i;
return result;
}
};这份代码的思路其实也是我第二个标题中总结的,只不过编写的方法不一样而已:
首先,作者使用了一个长度为 256 的 vector 来存储各个字母的出现次数值(为什么是 256 ?思考下 ASCII 值有多少个)
然后,作者进行了遍历,跟我之前的逻辑差不多的,也是根据出现次数的奇偶性进行不同的处理;不过这里不同的是,作者是如何保证奇数出现次数的元素只取 1 个的呢?下面这句代码泄露了天机,一旦 result 已经加上了出现次数为奇数的元素,那么 result 必然为奇数,那么再遇到出现次数为奇数的元素,则应该按照最大偶数值来取,否则取原值;这个方法非常巧妙(想想我之前为了判断是否存在出现次数为奇数的元素花了多大的力气 )
result += i%2 ? (result%2 ? i-1 : i) : i;- 最后,作者安心的返回计算出来的 result 值
可以说,作者的代码非常优雅,尽管难以让人看懂,不过写的非常短小精悍。
真的是膜拜大神啊!
五、总结
这道题其实不是那么复杂,可能我的表述比较多会有些迷惑。不过我相信只要看懂了前面的分析的部分,后面的代码罗列部分应该都仅仅是编写手法的问题了。
这道题做了我比较久的时间,做出第一个方法并没有花太久的时间,反而是之后逼着自己要写出更加优雅的代码,代码量更加短少的代码,却让自己陷入了比较难的境地。尤其是中间偷瞄了下最高票的标题 5 lines C++ ,当时我数了下自己的代码,比 5 行多那么多,于是拼命地降低再降低,修改自己的思路,最后才做出了第四个方法(不过也都有 6 行)。
不论怎么说,分析问题的方法才是最重要的,代码的编写仅仅是一个很次要的一方面。
写了这么多,尽管我写的比较累,但是也不希望你们看的那么累。如果觉得写的太多看起来麻烦,可以仅仅看几段代码,看看分析即可,其他都是无聊的自言自语罢了:)
不过不得不说,这道题让我做的很过瘾,那种拼命思考拼命追求代码简洁优雅的过程,真的非常享受:)
最后的最后:
To be Stronger!














 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









