










多版本并发控制
Multi-Version Concurrency Control
基础理解
事务T1改变数据V1,将其改为数据V2,在堆中,数据如下图
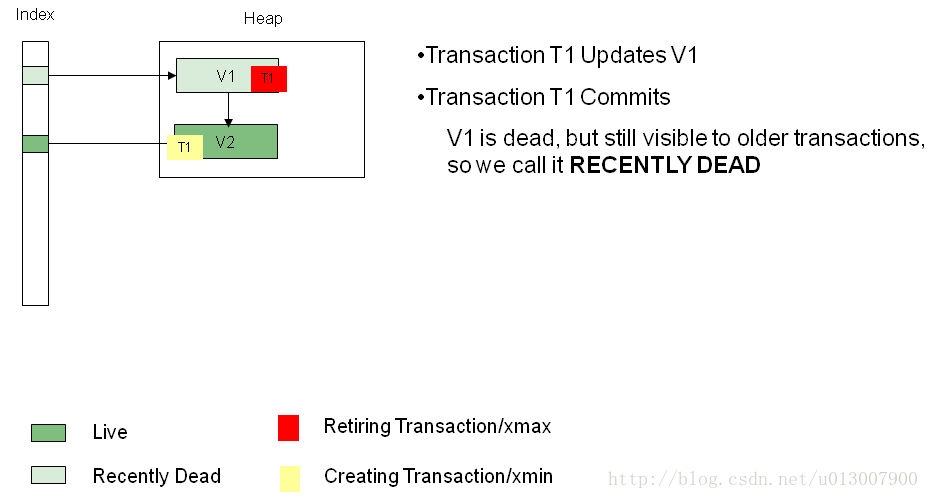
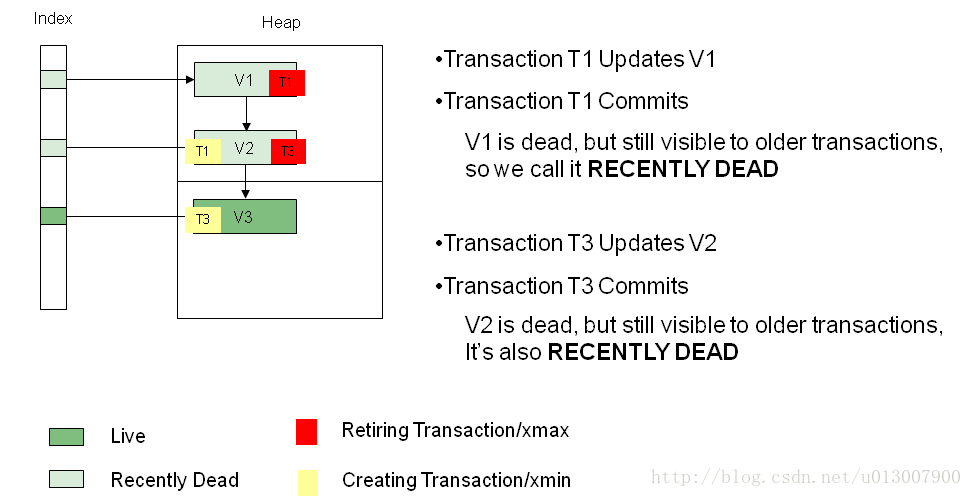
事务T3改变了V2,将其改为V3,在堆中,数据如下图:目前事务T2还在活动中,所以V1和V2属于recently dead状态,而不是真的dead状态。
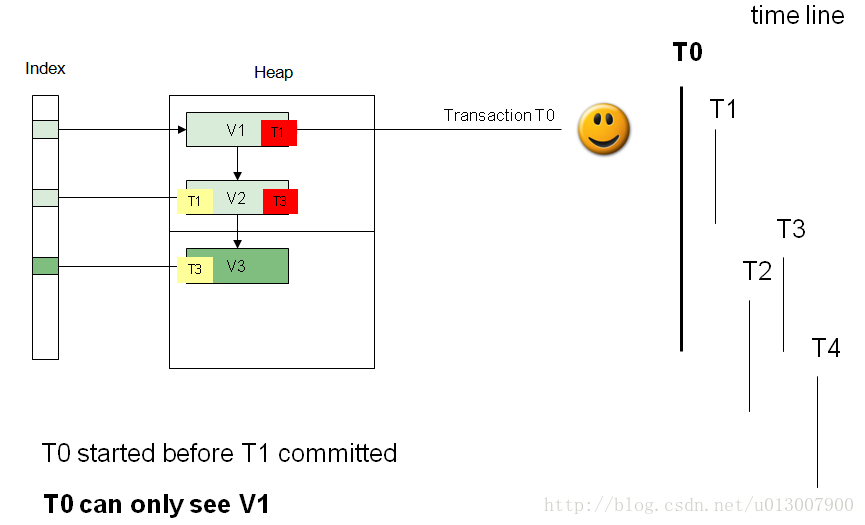
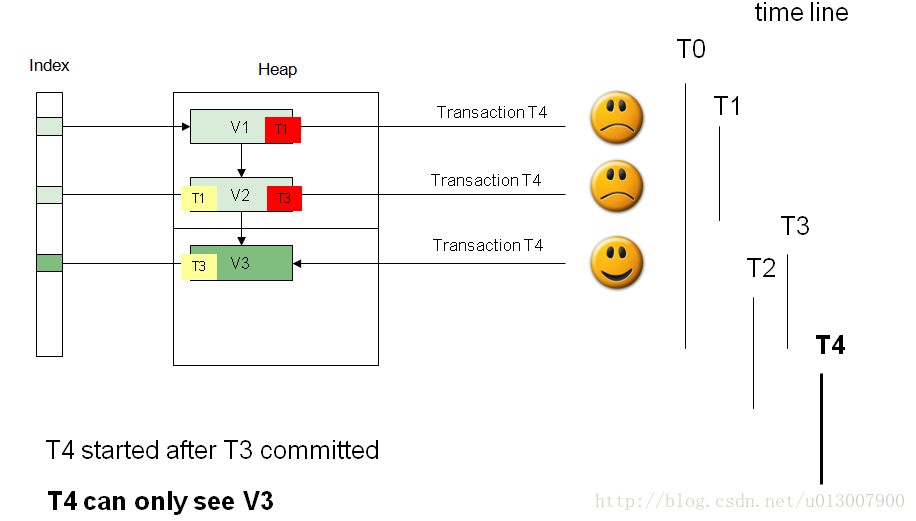
从可视性而言,事务T0只能看到数据V1。因为它早于事务T1启动。
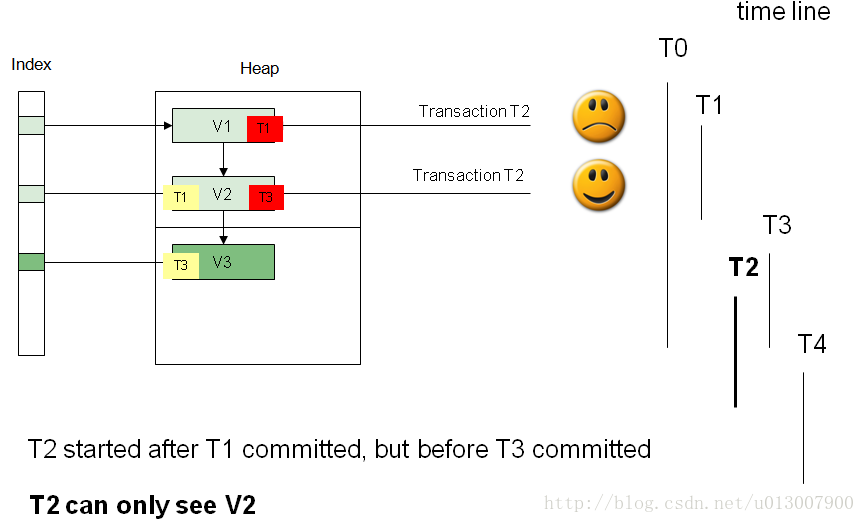
事务T1提交后,事务T2启动,此时事务T3尚未启动,故T2可以看到T1提交后的数据V2。
事务T3提交后,事务T4启动,故T4只能看到数据V3。
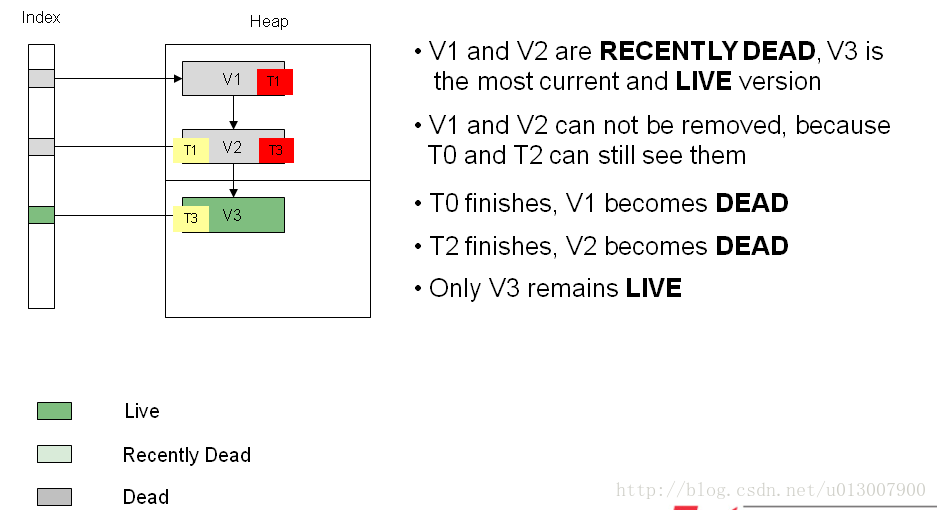
前面说过,当还有事务活动中访问数据V1和V2,V1和V2的状态是recently dead。
当T0和T2都结束,已经没有事务在访问数据V1和V2了,此时V1和V2为dead状态,所以V1和V2都成为VACUUM的处理对象了。
设计与实现
数据存储格式
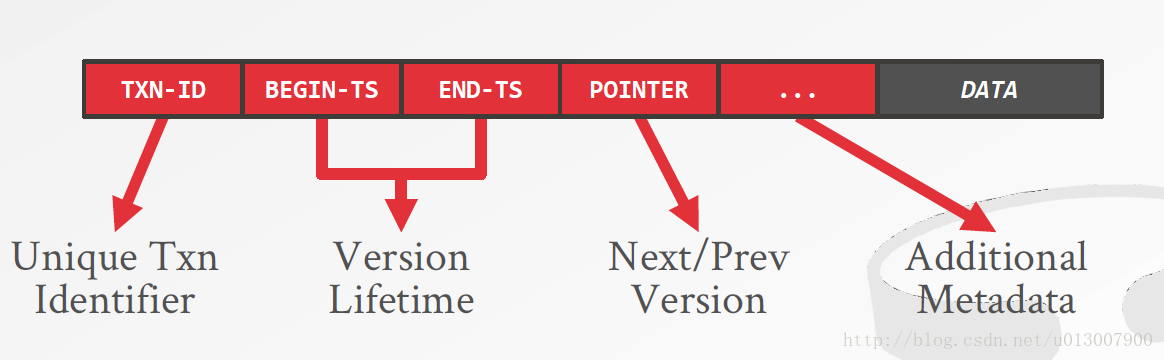
其中版本信息的每一个部分都将用64bits来存储。
Timestamp Ordering (MVTO)
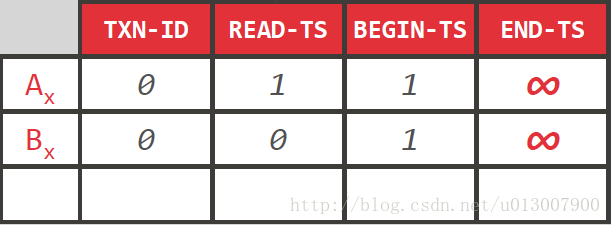
上图就包含了数据存储的样例。
只有当TXN-ID,即锁,没有被占有且事务的ID属于BEGIN-TS和END-TS之间才能够读取该数据。
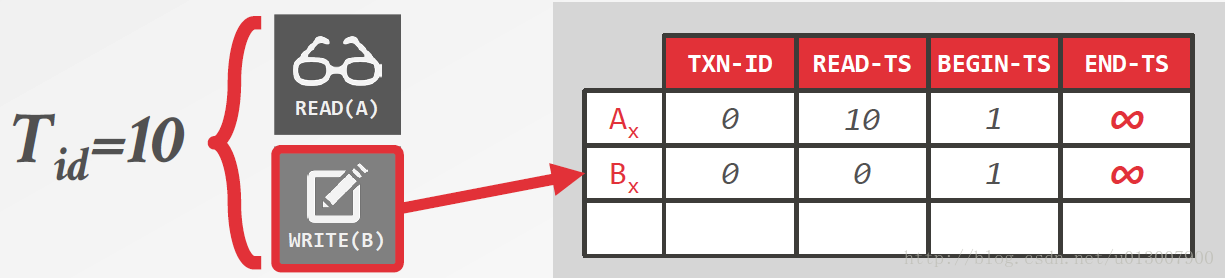
每次一个事务读取的时候,都会更新一下READ-TS。如果有一个事务11先于事务10读取,那么事务10也可以读取该数据,但是不会更新READ-TS。
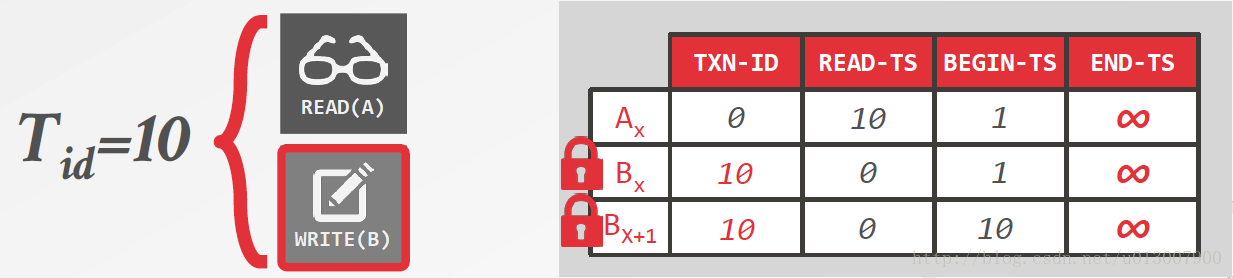
当事务10对数据进行操作的时候,会先占用锁,并创建一个新的版本。之所以要把老的也锁上,是因为需要更新一下END-TS的时间,同时也要更新一下NEXT-VERSION指针。当然,当对旧的数据不需要操作的时候也可以进行释放,但是在这个例子里新的数据的锁会已知保持到事务提交。

版本存储
使用的是VERSION CHAIN,即版本链进行存储。
- 可以使得DBMS找到对于特定事务可以读取的版本
- 索引指向的是链表的头
一般情况链表头指最旧的版本,之所以这么设计的原因是,在大部分情况下,查询的次数远大于修改的次数,所以链的长度并不是特别长,而且这样实现也更简单。
线程将会把版本信息存入内存,从而不必每次都要都从磁盘或者数据结构中获得。
不同的存储方式决定用何种方式何种媒介去存储每个版本的信息和数据。
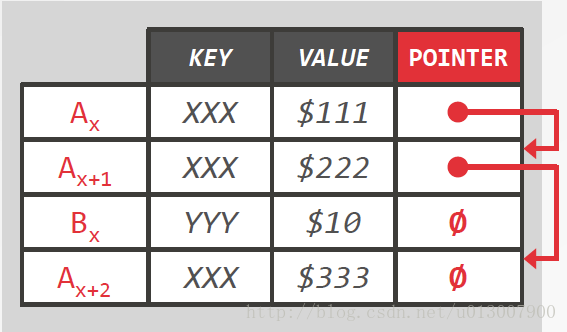
Append-Only Storage
所有物理级别的版本信息都存在一个表空间中。
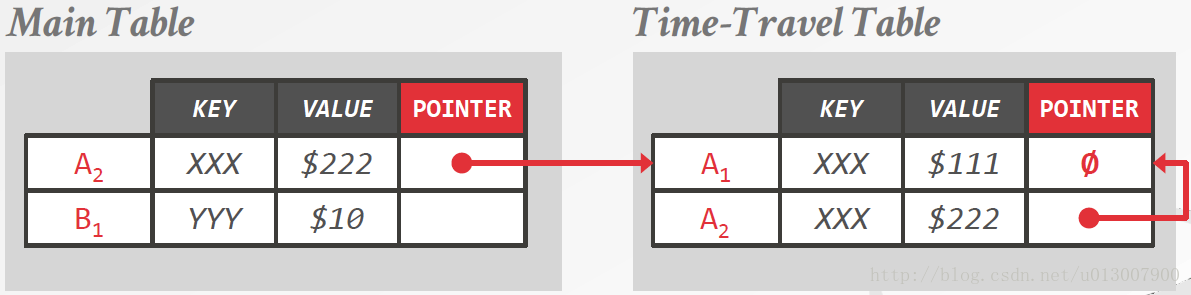
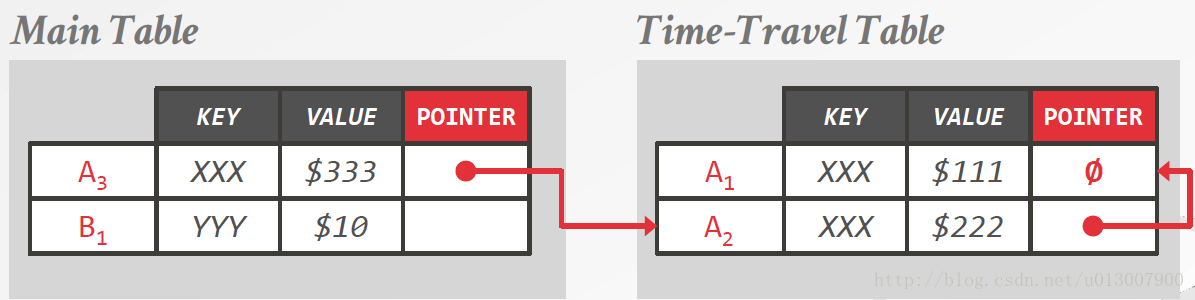
Time-Travel Storage
分两个表存储
先把旧的版本存入Time Travel 表,Time Travel表又是用链式存储的。
再将新的版本写入。
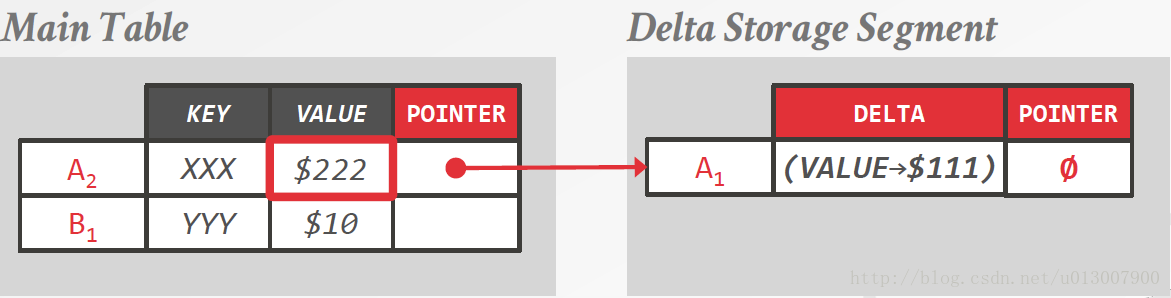
Delta Storage
有些类似Git管理代码的时候只记录两个版本的查
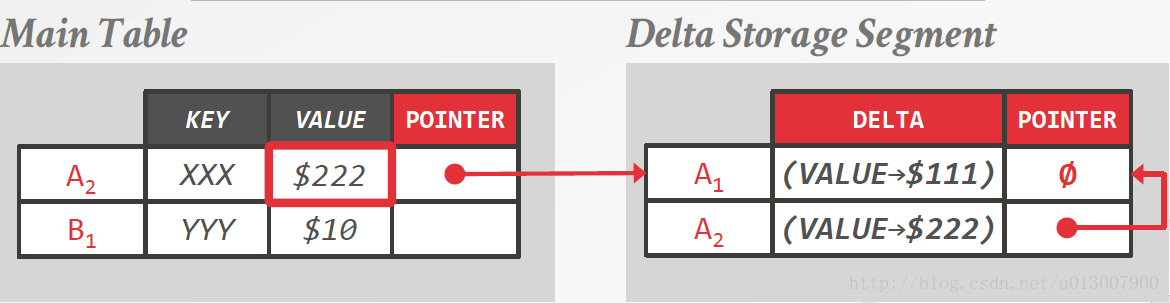
这样做的好处是,当你在一张有数千个属性的表里修改一个值的时候,你不需要把整个记录记下来,只需要保存修改过的东西。
垃圾回收
DBMS需要随时从数据库中删除可回收的版本(物理存储)。比如,所有激活的事务都不能看到的版本;由终止并回滚的事务产生的版本。
Tuple级别
数据库不需要存储整个table的版本信息,而是对于每次操作,存储其改变的元组的信息。
所以每次commit之后,我们不需要搜索整个table,而是对于我们修改过的元组我们将不必要的东西删除。
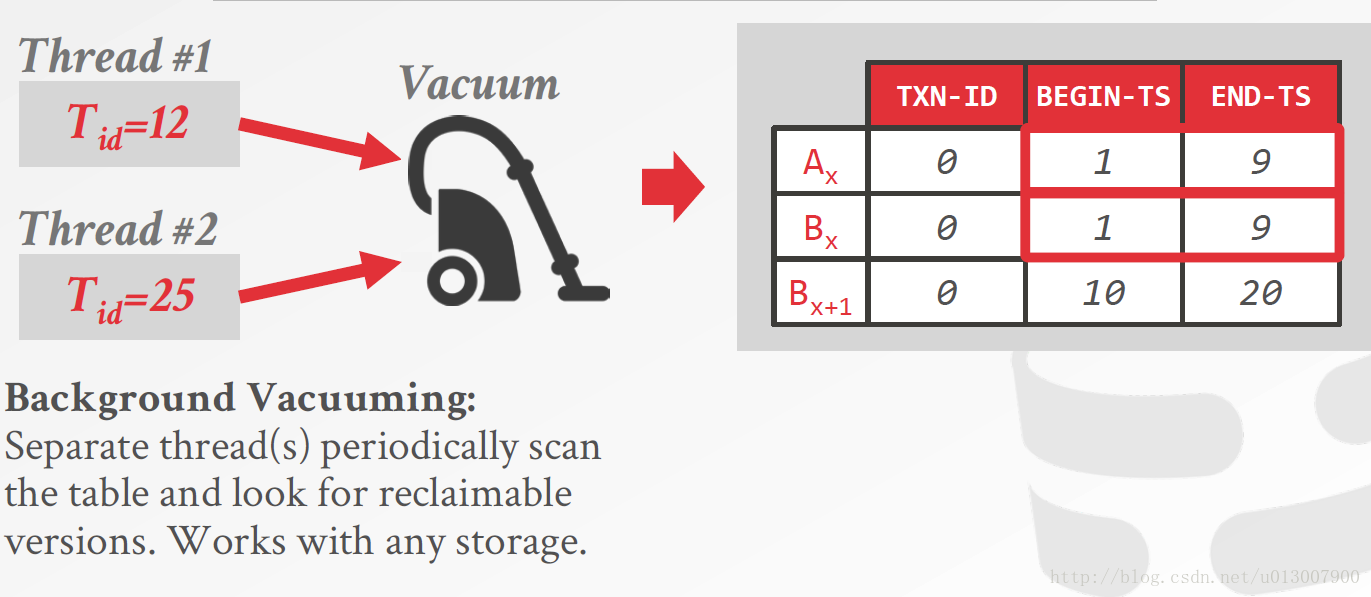
线程1的时间戳为12,线程2的时间戳为25,而右侧的版本中,前两个元组的结束时间戳,小于所有线程中时间戳最小的那一个,说明所有激活的事务都看不到前面两个版本,所以将他们删除。
事务级别
事务级别就是对于每个事务,追踪它的读写情况;通过DBMS可以得知有哪些版本永远不会被用到了。















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









