







HBase - Bloom Filter 简单理解
Bloom Filter 是一个过滤器,他提供了一个轻量级的 in-memeory 结构,来减少 Get 操作时读取磁盘文件的数量,只读取包含了要读取的行的文件。能大大的提高读取的效率。
Bloom Filter 是使用位数组来表示的。初始状态的数组全为0。

每个 HFile都会由一个与之联结 Bloom Filter位数组。Bloom Filter 会把一个表的行键组成一个集合,然后在分别了每个行键上进行 Hash 计算,Hash 计算的结果映射到数组的某位上,就将该位设为1。如果一个位置多次被置为1,那就还是1。
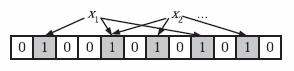
然后使用 Get 方法获取某个行键指定的行数据时,就同样对该行键进行 Hash,如果该 Hash 映射的数组的位置上有0,说明在该行键上一定不是该集合(HFile文件)的元素,如果映射的位置全为1,就说明可能是此集合(HFile文件)的元素。而说可能意思是会有一定的错误率,但使用该错误率来换取大的空间节省与扫描时间的减少,是值得的。
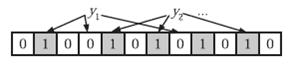
参考资料:
[1]http://blog.csdn.net/lifuxiangcaohui/article/details/39991781
[2]http://www.tuicool.com/articles/Nveyyy
[3]http://blog.csdn.net/opensure/article/details/46453681















 2213
2213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









