







 本文介绍了Bloom filter在Hbase中的作用,它能有效地减少磁盘IO次数。适用于用户定期更新部分行的场景,并探讨了数据单元格大小对使用Bloom filter的影响。文章还提到了行级与行加列级Bloom Filter的选择取决于操作模式,尤其是对于整行操作的情况。同时,文中提供了一个简单的Java实现示例。
本文介绍了Bloom filter在Hbase中的作用,它能有效地减少磁盘IO次数。适用于用户定期更新部分行的场景,并探讨了数据单元格大小对使用Bloom filter的影响。文章还提到了行级与行加列级Bloom Filter的选择取决于操作模式,尤其是对于整行操作的情况。同时,文中提供了一个简单的Java实现示例。
Bloom filter 简单而言就是对hash 表的创新,用在 Hbase 中可以有有效减少磁盘IO次数。
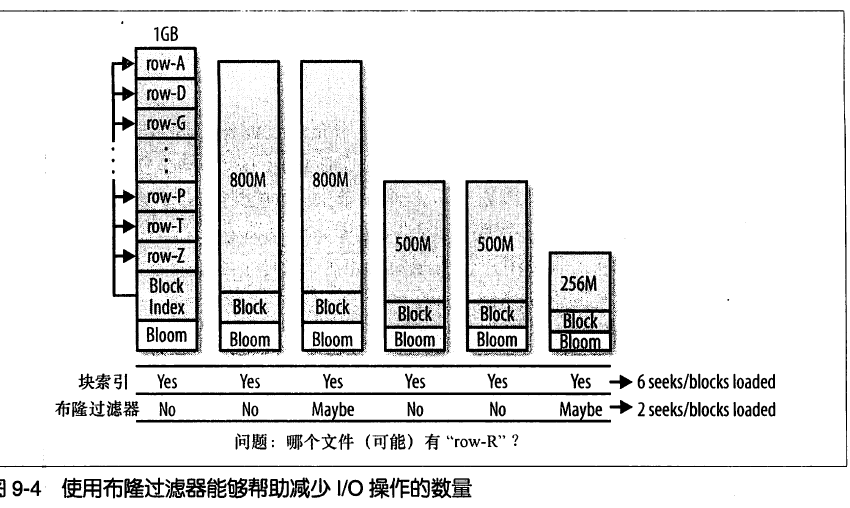
图片来源:hbase 权威指南
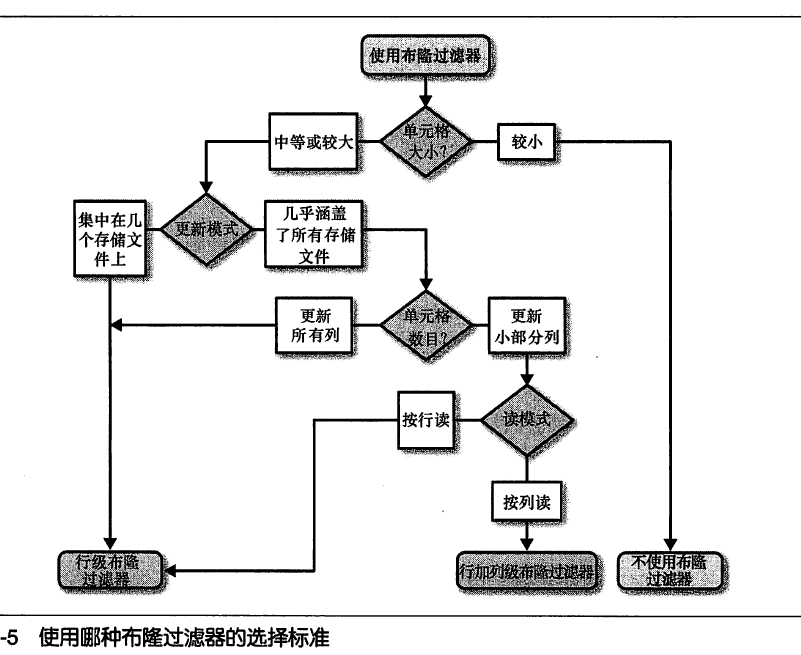
**使用场景总结:
- 当用户定期更新所有行时不适合使用Bloom filter,当用户定期更新部分行时,适合使用Bloom filter
- 当数据单元格较小时不合适使用Bloom filter (因为此时将会有太多的Bloom filter)
- 使用行级Bloom filter 还是 行加列级Bloom Filter 取决于使用模式,当操作是整行操作时,采用Bloom Filter 操作较合适
**
下面是一个java 的简单实现
package basic;
/*
* @author: wjf
* @version: 2016年4月15日 下午10:05:28
*/
import java.util.BitSet;
public class BloomFilter {
private static int DEFAULT_SIZE=1<<24;
private int[] seeds={3,5,7,11,13,17,31,41};
private static BitSet bits=new BitSet(DEFAULT_SIZE);
private SimpleHash[] hashs=new SimpleHash[seeds.length];
public boolean addValue(String value){
if(value==null){
return false;
}else{
for(int i=0;i<seeds.length;i++){
hashs[i]=new SimpleHash(DEFAULT_SIZE,seeds[i]);
bits.set(hashs[i].hash(value),true);
}
return true;
}
}
public boolean contains(String value){
if(value==null){
return false;
}else{
boolean ret=true;
for(SimpleHash h:hashs){
ret=ret && bits.get(h.hash(value));
if(ret == false){
return false;
}
}
return true;
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
BloomFilter bfilter=new BloomFilter();
bfilter.addValue("just for test");
System.out.println(bfilter.contains("just for test"));
}
}
class SimpleHash{
private int cap;
private int seed;
public SimpleHash(int cap,int seed){
this.cap=cap;
this.seed=seed;
}
public int hash(String value){
int result=0;
for(int i=0;i<value.length();i++){
result=result*seed+value.charAt(i);
}
return (cap-1)&result;
}
}















 2209
2209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









