







 HBase的负载均衡由HMaster负责,每5分钟执行一次。主要过程包括生成负载均衡计划表和由Assignment Manager执行计划。计算负载的评分算法涉及Region Load、Table Load、Data Locality、Memstore Sizes和Storefile Sizes等维度。HBase提供了RandomRegionPicker、LoadPicker和LocalityPicker三种策略进行region的交换或迁移,以达到更好的负载均衡效果。StochasticLoadBalancer在HBase 0.96版本成为默认负载均衡算法,相比旧版考虑了更多维度。
HBase的负载均衡由HMaster负责,每5分钟执行一次。主要过程包括生成负载均衡计划表和由Assignment Manager执行计划。计算负载的评分算法涉及Region Load、Table Load、Data Locality、Memstore Sizes和Storefile Sizes等维度。HBase提供了RandomRegionPicker、LoadPicker和LocalityPicker三种策略进行region的交换或迁移,以达到更好的负载均衡效果。StochasticLoadBalancer在HBase 0.96版本成为默认负载均衡算法,相比旧版考虑了更多维度。
HMater负责把region均匀到各个region server 。hmaster中有一个线程任务是专门处理负责均衡的,默认每隔5分钟执行一次。
每次负载均衡操作可以分为两步:
- 生成负载均衡计划表
- Assignment Manager 类执行计划表
下面我们来详细介绍一下HBase是如何生成负载平衡计划表的。
首先我们要明确,负载均衡是根据每个Table来的,在如下几种情况下是不会执行负载均衡的:
- 如果master没有被初始化
- 当前已经有负载均衡方法在跑了
- 当前有region处于splitting状态
- 当前集群中有挂掉的region server
生成RegionPlan表:
代码包路径:
org.apache.hadoop.hbase.master.balancer.StochasticLoadBalancer
生成regionPlan表方法为:
StochasticLoadBalancer. balanceCluster(Map<ServerName, List<HRegionInfo>> clusterState)这个方法比较特别也比较有意思,首先,StochasticLoadBalancer 有一套计算某一table下cluster load(集群负载)评分的算法,得出的值越低表明负载越合理。这套算法是根据以下几个维度来计算得出的:
- Region Load //每个regin server 的region 数目
- Table Load
- Data Locality //数据本地性
- Memstore Sizes //memstore大小
- Storefile Sizes //存储文件的大小
首先对单个region server 根据上面5个维度计算得出评分x(0<=x<=1),然后把同一table下所有region server评分加起来,就是当前table的cluster load评分。这个评分越低表明越合理。
然后它还有三种调节cluster load 的方法:
- RandomRegionPicker
- LoadPicker
- LocalityPicker
RandomRegionPicker 随机交换策略。在虚拟cluster中(虚拟cluster只作为记录用,不会涉及实际的region 迁移操作。cluster包含某个table下所有的region server的相关信息,以及region server下的regions.)随机选出两个region server ,然后分别在region server 中在 随机获取一个region,然后这两个region server下的region交换一下,然后再计算评分,如果得出的评分较低的话,表明这两个region 交换是有利于集群的负载均衡的,保留这个改变。否则,还原到之前的状态,两个region再交换下region server 。其中拥有比较少regions的region server 可能随机出一个空,实际情况,就是变成了迁移region,不再是交换region。
LoadPicker ,region数目均衡策略。在虚拟cluster中,首先获取region数目最多和最少的两个region server ,这样能使两个region server 最终的region数目更加的平均。后面的流程和上面的一样。
LocalityPicker ,本地性最强的均衡策略。本地性的意思是,Hbase底层的数据其实是存放在HDFS上面的,如果某个region的数据文件存放在某个region server 的比例比其他的region server 都要高,那么称这个region server是该region的最高本地性region server 。在该策略中,首先随机出一个region server 以及其下面的region 。然后找到这个region本地性最高的region server 。本地性最高的region server再随机出一个region server。这两个region server 后面的流程和上面的一样。
具体流程如下:
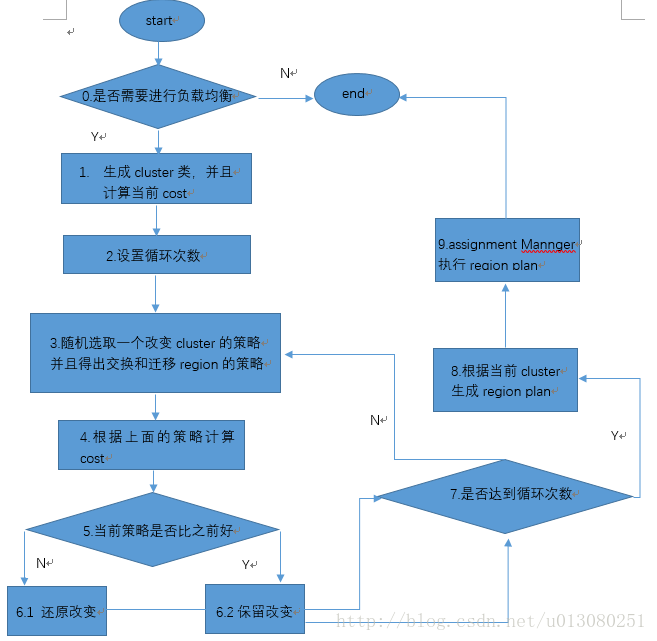
我们对上面流程图中的主要步骤进行分析:
0. 是否需要进行负载均衡—-是根据当前region server拥有的region数目来判断的,查看如下代码。
protected boolean needsBalance(ClusterLoadState cs) {
...
float average = cs.getLoadAverage(); // for</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 21
21

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









