









数据库集群负载均衡的实现依赖于数据库的数据分片设计,可以在一定程度上认为数据分片就是数据读写负载,那么负载均衡功能就是数据分片在集群中均衡的实现。
一、Region迁移
作为一个分布式系统,分片迁移是最基础的核心功能。集群负载均衡、故障恢复等功能都是建立在分片迁移的基础之上的。比如集群负载均衡,可以简单理解为集群中所有节点上的分片数目保持相同。
实际执行分片迁移时可以分为两个步骤:第一步,根据负载均衡策略制定分片迁移计划;第二步,根据迁移计划执行分片的实际迁移。
HBase系统中,分片迁移就是Region迁移。和其他很多分布式系统不同,HBase中Region迁移是一个非常轻量级的操作。所谓轻量级,是因为HBase的数据实际存储在HDFS上,不需要独立进行管理,因而Region在迁移的过程中不需要迁移实际数据,只要将读写服务迁移即可。
1,Region迁移的流程
在当前的HBase版本中,Region迁移虽然是一个轻量级操作,但实现逻辑依然比较复杂。复杂性主要表现在两个方面:其一,Region迁移过程涉及多种状态的改变;其二,迁移过程中涉及Master、ZooKeeper(ZK)以及RegionServer等多个组件的相互协调。
HBase定义的Region状态:
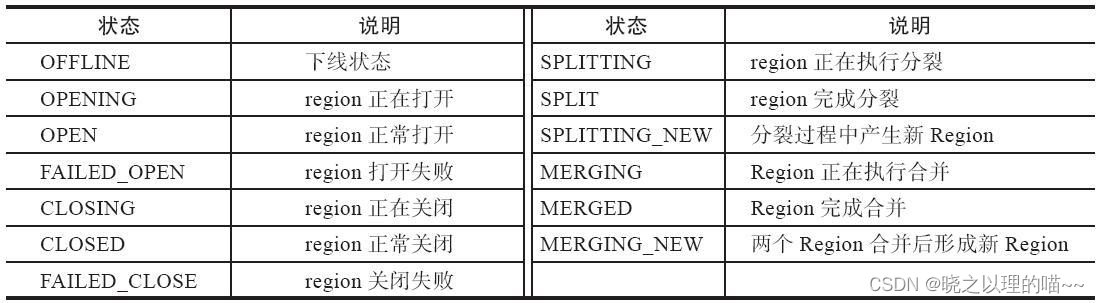
SPLITTING、SPLIT和SPLITTING_NEW 3个状态是Region分裂过程中的状态;
MERGING、MERGED和MERGING_NEW 3个状态是Region合并过程中的状态,
在实际执行过程中,Region迁移操作分两个阶段:unassign阶段和assign阶段。
(1)unassign阶段
unassign表示Region从源RegionServer上下线.
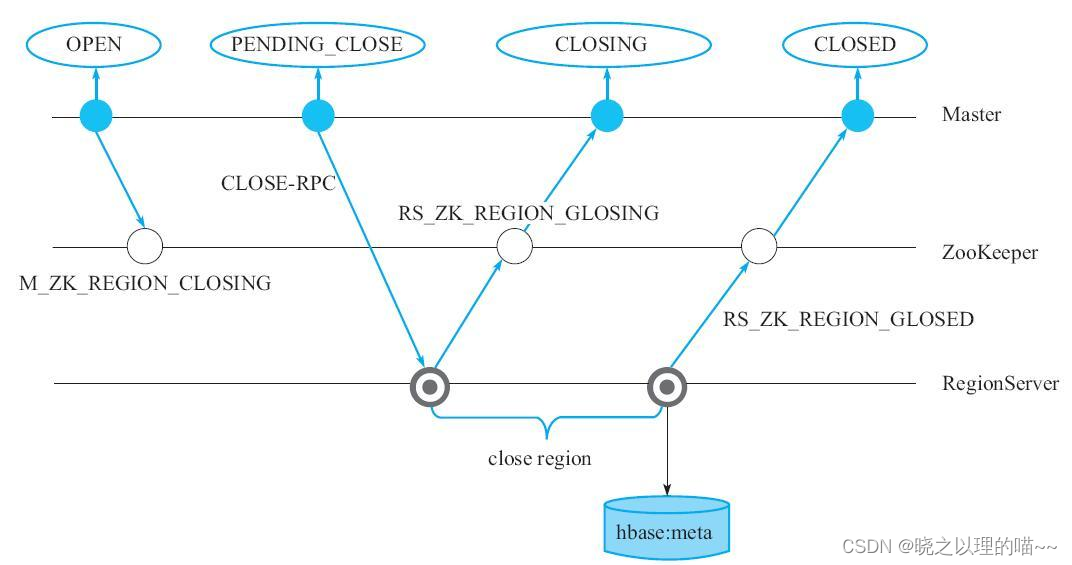
Region unassign阶段:
1)Master生成事件M_ZK_REGION_CLOSING并更新到ZooKeeper组件,同时将本地内存中该Region的状态修改为PENDING_CLOSE。
2)Master通过RPC发送close命令给拥有该Region的RegionServer,令其关闭该Region。
3)RegionServer接收到Master发送过来的命令后,生成一个RS_ZK_REGION_CLOSING事件,更新到ZooKeeper。
4)Master监听到ZooKeeper节点变动后,更新内存中Region的状态为CLOSING。
5)RegionServer执行Region关闭操作。如果该Region正在执行flush或者Compaction,等待操作完成;否则将该Region下的所有MemStore强制flush,然后关闭Region相关的服务。
6)关闭完成后生成事件RS_ZK_REGION_CLOSED,更新到ZooKeeper。Master监听到ZooKeeper节点变动后,更新该Region的状态为CLOSED
(2)assign阶段
assign表示Region在目标RegionServer上上线.
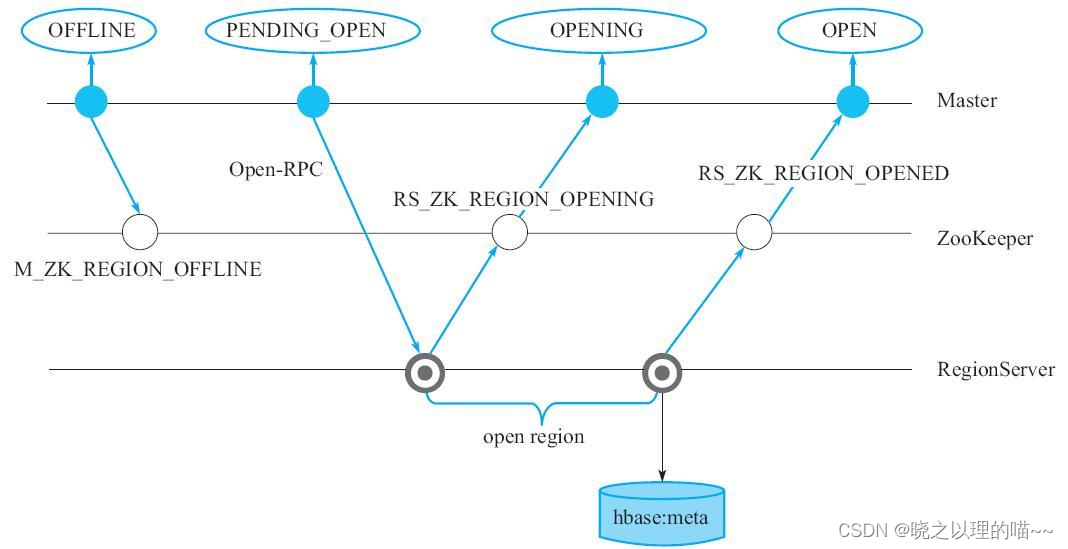
Region assign阶段:
1)Master生成事件M_ZK_REGION_OFFLINE并更新到ZooKeeper组件,同时将本地内存中该Region的状态修改为PENDING_OPEN。
2)Master通过RPC发送open命令给拥有该Region的RegionServer,令其打开该Region。
3)RegionServer接收到Master发送过来的命令后,生成一个RS_ZK_REGION_OPENING事件,更新到ZooKeeper。
4)Master监听到ZooKeeper节点变动后,更新内存中Region的状态为OPENING。
5)RegionServer执行Region打开操作,初始化相应的服务。
6)打开完成之后生成事件RS_ZK_REGION_OPENED,更新到ZooKeeper,Master监听到ZooKeeper节点变动后,更新该Region的状态为OPEN
(3)总结
ssign/assign操作是一个比较复杂的过程,涉及Master、RegionServer和ZooKeeper三个组件,三个组件的主要职责如下:
1)Master负责维护Region在整个操作过程中的状态变化,起到枢纽的作用。
2)RegionServer负责接收Master的指令执行具体unassign/assign操作,实际上就是关闭Region或者打开Region操作。
3)ZooKeeper负责存储操作过程中的事件。ZooKeeper有一个路径为/hbase/region-in-transition的节点,一旦Region发生unssign操作,就会在这个节点下生成一个子节点,子节点的内容是“事件”经过序列化的字符串,并且Master会在这个子节点上监听,一旦发生任何事件,Master会监听到并更新Region的状态。
2,Region In Transition
Region的这些状态会存储在三个区域:meta表,Master内存,ZooKeeper的region-in-transition节点,并且作用不同,说明如下:
(1)meta表只存储Region所在的RegionServer,并不存储迁移过程中的中间状态,如果Region从rs1成功迁移到rs2,那么meta表中就持久化存有Region与rs2的对应关系,而如果迁移中间出现异常,那么meta表就仅持久化存有Region与rs1的对应关系。
(2)Master内存中存储整个集群所有的Region信息,根据这个信息可以得出此Region当前以什么状态在哪个RegionServer上。Master存储的Region状态变更都是由RegionServer通过ZooKeeper通知给Master的,所以Master上的Region状态变更总是滞后于真正的Region状态变更。注意,我们在HBase Master WebUI上看到的Region状态都来自于Master内存信息。
(3)ZooKeeper中存储的是临时性的状态转移信息,作为Master和RegionServer之间反馈Region状态的通道。如果Master(或者相应RegionServer)在中间某个阶段发生异常,ZooKeeper上存储的状态可以在新Master启动之后作为依据继续进行迁移操作。
只有这三个状态保持一致,对应的Region才处于正常的工作状态。然而,在很多异常情况下,Region状态在三个地方并不能保持一致,这就会出现region-in-transition(RIT)现象。
二、Region合并
在线合并Region是HBase非常重要的功能之一。相比Region分裂,在线合并Region的使用场景比较有限,最典型的一个应用场景是,在某些业务中本来接收写入的Region在之后的很长时间都不再接收任何写入,而且Region上的数据因为TTL过期被删除。这种场景下的Region实际上没有任何存在的意义,称为空闲Region。一旦集群中空闲Region很多,就会导致集群管理运维成本增加。此时,可以使用在线合并功能将这些Region与相邻的Region合并,减少集群中空闲Region的个数。
从原理上看,Region合并的主要流程如下:
(1)客户端发送merge请求给Master。
(2)Master将待合并的所有Region都move到同一个RegionServer上。
(3)Master发送merge请求给该RegionServer。
(4)RegionServer启动一个本地事务执行merge操作。
(5)merge操作将待合并的两个Region下线,并将两个Region的文件进行合并。
(6)将这两个Region从hbase:meta中删除,并将新生成的Region添加到hbase:meta中。
(7)将新生成的Region上线。
HBase使用merge_region命令执行Region合并,如下:
$ hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME'
$ hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME', true
merge_region是一个异步操作,命令执行之后会立刻返回,用户需要一段时间之后手动检测合并是否成功。默认情况下merge_region命令只能合并相邻的两个Region,非相邻的Region无法执行合并操作。同时HBase也提供了一个可选参数true,使用此参数可以强制让不相邻的Region进行合并,因为该参数风险较大,一般并不建议生产线上使用。
三、Region分裂
Region分裂是HBase最核心的功能之一,是实现分布式可扩展性的基础。HBase中,Region分裂有多种触发策略可以配置,一旦触发,HBase会寻找分裂点,然后执行真正的分裂操作。
1,Region分裂触发策略
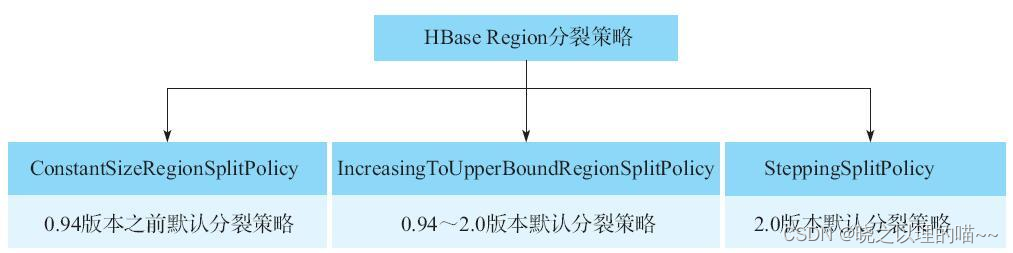
HBase已经有6种分裂触发策略。每种触发策略都有各自的适用场景,用户可以根据业务在表级别选择不同的分裂触发策略。
常用的有以下三种:
(1)ConstantSizeRegionSplitPolicy:0.94版本之前默认分裂策略。表示一个Region中最大Store的大小超过设置阈值(hbase.hregion.max.filesize)之后会触发分裂。ConstantSizeRegionSplitPolicy最简单,但是在生产线上这种分裂策略却有相当大的弊端——分裂策略对于大表和小表没有明显的区分。阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就只有1个Region,这对业务来说并不是什么好事。如果阈值设置较小则对小表友好,但一个大表就会在整个集群产生大量的Region,对于集群的管理、资源使用来说都不是一件好事。
(2)IncreasingToUpperBoundRegionSplitPolicy:0.94版本~2.0版本默认分裂策略。这种分裂策略总体来看和ConstantSizeRegionSplitPolicy思路相同,一个Region中最大Store大小超过设置阈值就会触发分裂。但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是在一定条件下不断调整,调整后的阈值大小和Region所属表在当前RegionServer上的Region个数有关系,调整后的阈值等于(#regions)(#regions)(#regions)flush size2,当然阈值并不会无限增大,最大值为用户设置的MaxRegionFileSize。这种分裂策略很好地弥补了ConstantSizeRegionSplitPolicy的短板,能够自适应大表和小表,而且在集群规模较大的场景下,对很多大表来说表现很优秀。然而,这种策略并不完美,比如在大集群场景下,很多小表就会产生大量小Region,分散在整个集群中。
(3)SteppingSplitPolicy:2.0版本默认分裂策略。这种分裂策略的分裂阈值也发生了变化,相比IncreasingToUpperBoundRegionSplitPolicy简单了一些,分裂阈值大小和待分裂Region所属表在当前RegionServer上的Region个数有关系,如果Region个数等于1,分裂阈值为flush size*2,否则为MaxRegionFileSize。这种分裂策略对于大集群中的大表、小表会比IncreasingToUpperBoundRegionSplitPolicy更加友好,小表不会再产生大量的小Region。
还有一些其他分裂策略,比如使用DisableSplitPolicy可以禁止Region发生分裂;而KeyPrefixRegionSplitPolicy和DelimitedKeyPrefixRegionSplitPolicy依然依据默认的分裂策略,但对于分裂点有自己的规定,比如KeyPrefixRegionSplitPolicy要求必须让相同的PrefixKey处于同一个Region中。
2,Region分裂准备工作——寻找分裂点
满足Region分裂策略之后就会触发Region分裂。分裂被触发后的第一件事是寻找分裂点。所有默认分裂策略,无论是ConstantSizeRegionSplitPolicy、IncreasingToUpperBoundRegionSplitPolicy还是SteppingSplitPolicy,对于分裂点的定义都是一致的。
HBase对于分裂点的定义为:整个Region中最大Store中的最大文件中最中心的一个Block的首个rowkey。另外,HBase还规定,如果定位到的rowkey是整个文件的首个rowkey或者最后一个rowkey,则认为没有分裂点。
注意:当待分裂Region只有一个Block时,会出现没有分裂点,执行split的时候就会无法分裂。
比如,新建一张测试表,往新表中插入几条数据并执行flush,再执行split,就会发现数据表并没有真正执行分裂。原因就在于测试表中只有一个Block,这个时候翻看debug日志可以看到如下代码:
2017-08-19 11:26:17,404 INFO [PriorityRpcServer.handler=1,queue=1,port=60020] regionserver.RSRpcServices:Splitting split,,1503112775843.6adfcc49ba04f307d6c6a604572d1bb2.
2017-08-19 11:26:17,499 DEBUG [PriorityRpcServer.handler=1,queue=1,port=60020] regionserver.StoreFile: cannot split because midkey is the same as first or last row
2017-08-19 11:26:17,499 DEBUG [PriorityRpcServer.handler=1,queue=1,port=60020] regionserver.CompactSplitThread: Region split,,1503112775843.6adfcc49ba04f307d6c6a604572d1bb2. not splittable because midkey=nul
3,Region核心分裂流程
HBase将整个分裂过程包装成了一个事务,目的是保证分裂事务的原子性。整个分裂事务过程分为三个阶段:prepare、execute和rollback。
if (!st.prepare()) return;
try {
st.execute(this.server, this.server, user); success = true;
} catch (Exception e) {
try {
st.rollback(this.server, this.server);
} catch (IOException re)
{
String msg = "Failed rollback of failed split of parent.getRegionNameAsString() -- abortingserver";
LOG.info(msg, re);
}
}
(1)prepare阶段
在内存中初始化两个子Region,具体生成两个HRegionInfo对象,包含tableName、regionName、startkey、endkey等。同时会生成一个transaction journal,这个对象用来记录分裂的进展,具体见rollback阶段。
(2)execute阶段
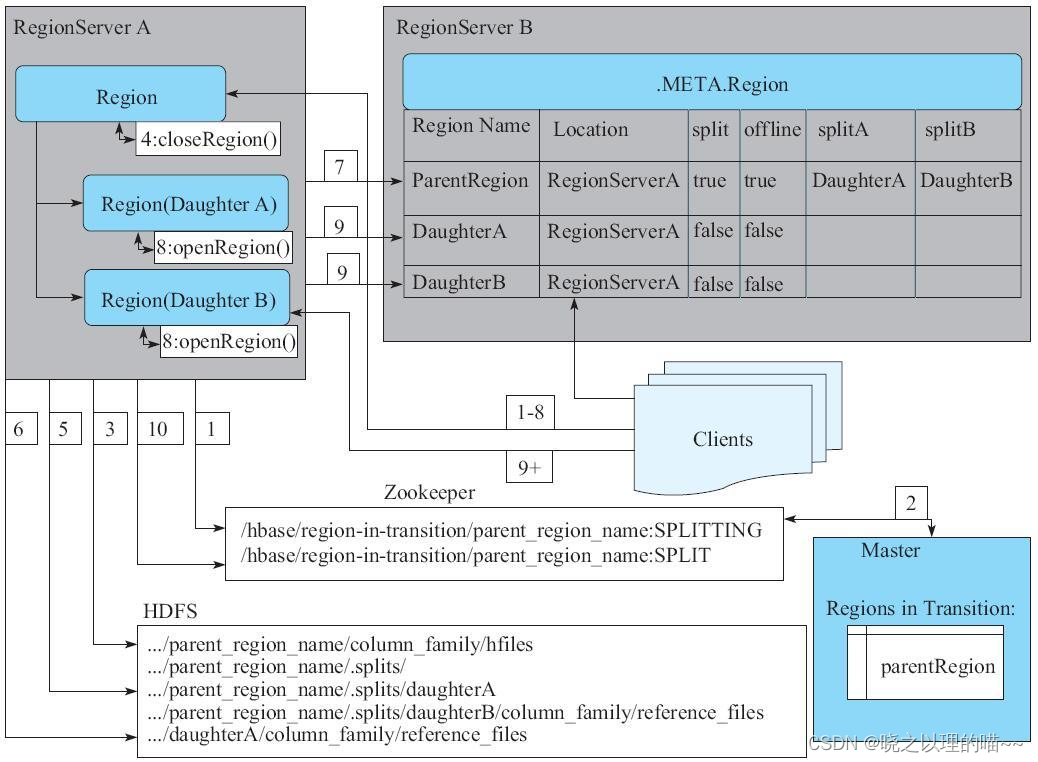
这个阶段的步骤如下:
1)RegionServer将ZooKeeper节点/region-in-transition中该Region的状态更改为SPLITING。
2)Master通过watch节点/region-in-transition检测到Region状态改变,并修改内存中Region的状态,在Master页面RIT模块可以看到Region执行split的状态信息。
3)在父存储目录下新建临时文件夹.split,保存split后的daughter region信息。
4)关闭父Region。父Region关闭数据写入并触发flush操作,将写入Region的数据全部持久化到磁盘。此后短时间内客户端落在父Region上的请求都会抛出异常NotServingRegionException。
5)在.split文件夹下新建两个子文件夹,称为daughter A、daughter B,并在文件夹中生成reference文件,分别指向父Region中对应文件。这个步骤是所有步骤中最核心的一个环节,生成了如下reference文件日志。
6)父Region分裂为两个子Region后,将daughter A、daughter B拷贝到HBase根目录下,形成两个新的Region。
7)父Region通知修改hbase:meta表后下线,不再提供服务。下线后父Region在meta表中的信息并不会马上删除,而是将split列、offline列标注为true,并记录两个子Region。
8)开启daughter A、daughter B两个子Region。通知修改hbase:meta表,正式对外提供服务。
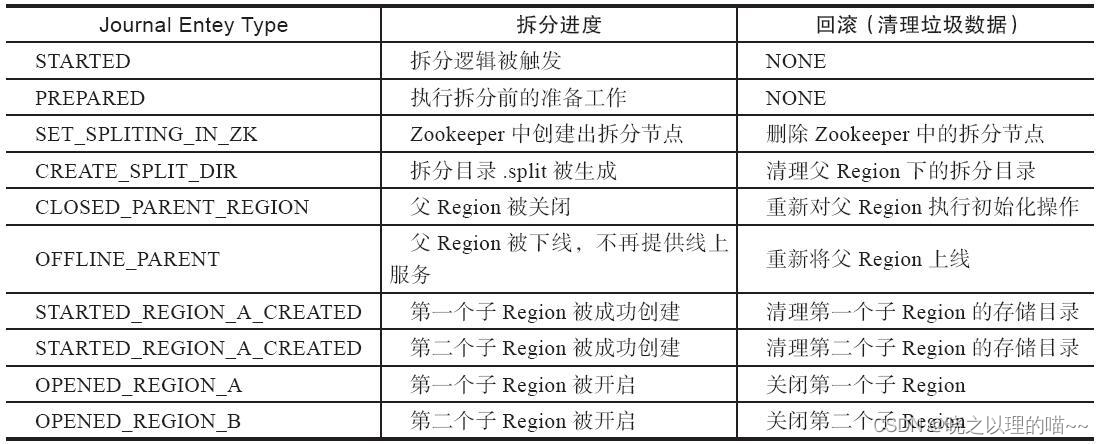
(3)rollback阶段
如果execute阶段出现异常,则执行rollback操作。为了实现回滚,整个分裂过程分为很多子阶段,回滚程序会根据当前进展到哪个子阶段清理对应的垃圾数据。代码中使用JournalEntryType来表征各个子阶段。
4,Region分裂原子性保证
Region分裂是一个比较复杂的过程,涉及父Region中HFile文件分裂、两个子Region生成、系统meta元数据更改等很多子步骤,因此必须保证整个分裂过程的原子性,即要么分裂成功,要么分裂失败,在任何情况下不能出现分裂完成一半的情况。
为了实现原子性,HBase使用状态机的方式保存分裂过程中的每个子步骤状态,这样一旦出现异常,系统可以根据当前所处的状态决定是否回滚,以及如何回滚。遗憾的是,目前实现中这些中间状态都只存储在内存中,一旦在分裂过程中出现RegionServer宕机的情况,有可能会出现分裂处于中间状态的情况,也就是RIT状态。这种情况下需要使用HBCK工具具体查看并分析解决方案。
在2.0版本之后,HBase将实现新的分布式事务框架Procedure V2(HBASE-12439),新框架使用类似HLog的日志文件存储这种单机事务(DDL操作、split操作、move操作等)的中间状态,因此可以保证即使在事务执行过程中参与者发生了宕机,依然可以使用对应日志文件作为协调者,对事务进行回滚操作或者重试提交,从而大大减少甚至杜绝RIT现象。这也是HBase 2.0在可用性方面最值得期待的一个亮点功能。
5,Region分裂对其他模块的影响
Region分裂过程因为没有涉及数据的移动,所以分裂成本本身并不是很高,可以很快完成。分裂后子Region的文件实际没有任何用户数据,文件中存储的仅是一些元数据信息——分裂点rowkey等。那么通过reference文件如何查找数据呢?子Region的数据实际在什么时候完成真正迁移?数据迁移完成之后父Region什么时候会被删掉?
(1)通过reference文件查找数据
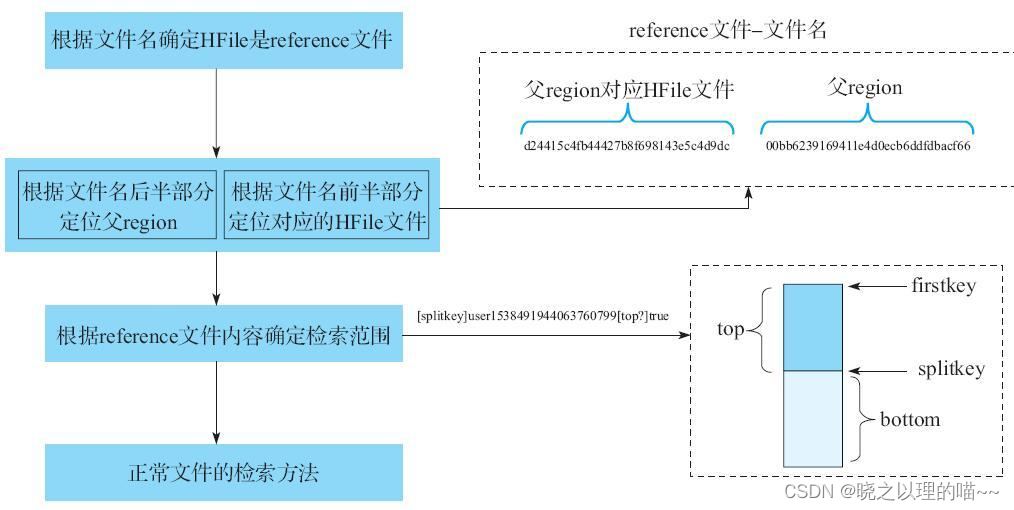
(1)根据reference文件名(父Region名+HFile文件名)定位到真实数据所在文件路径。
(2)根据reference文件内容中记录的两个重要字段确定实际扫描范围。top字段表示扫描范围是HFile上半部分还是下半部分。如果top为true,表示扫描的是上半部分,结合splitkey字段可以明确扫描范围为[firstkey,splitkey);如果top为false,表示扫描的是下半部分,结合splitkey字段可以明确扫描范围为[splitkey,endkey)。
(2)父Region的数据迁移到子Region目录的时间
迁移发生在子Region执行Major Compaction时。根据Compaction原理,从一系列小文件中依次由小到大读出所有数据并写入一个大文件,完成之后再将所有小文件删掉,因此Compaction本身就是一次数据迁移。分裂后的数据迁移完全可以借助Compaction实现,子Region执行Major Compaction后会将父目录中属于该子Region的所有数据读出来,并写入子Region目录数据文件中。
(3)父Region被删除的时间
Master会启动一个线程定期遍历检查所有处于splitting状态的父Region,确定父Region是否可以被清理。检查过程分为两步:
1)检测线程首先会在meta表中读出所有split列为true的Region,并加载出其分裂后生成的两个子Region(meta表中splitA列和splitB列)。
2)检查两个子Region是否还存在引用文件,如果都不存在引用文件就可以认为该父Region对应的文件可以被删除。
(4)HBCK中的split相关命令
在执行split过程中一旦发生RegionServer宕机等异常可能会导致region-in-transition。通常情况下建议使用HBCK查看报错信息,然后再根据HBCK提供的一些工具进行修复,HBCK提供了部分命令对处于split状态的rit region进行修复。
主要命令:
-fixSplitParents Try to force offline split parents to be online.
-removeParents Try to offline and sideline lingering parents and keep daughter regions.
-fixReferenceFiles Try to offline lingering reference store file
四、负载均衡应用
1,负载均衡策略
HBase官方目前支持两种负载均衡策略:SimpleLoadBalancer策略和StochasticLoadBalancer策略。
(1)SimpleLoadBalancer策略
这种策略能够保证每个RegionServer的Region个数基本相等,假设集群中一共有n个RegionServer,m个Region,那么集群的平均负载就是average=m/n,这种策略能够保证所有RegionServer上的Region个数都在[floor(average),ceil(average)]之间。因此,SimpleLoadBalancer策略中负载就是Region个数,集群负载迁移计划就是Region从个数较多的RegionServer上迁移到个数较少的RegionServer上。
该策略考虑的因素太过单一,对于RegionServer上的读写QPS、数据量大小等因素都没有实际考虑,这样就可能出现一种情况:虽然集群中每个RegionServer的Region个数都基本相同,但因为某台RegionServer上的Region全部都是热点数据,导致90%的读写请求还是落在了这台RegionServer上,这样显而易见没有达到负载均衡的目的。
(2)StochasticLoadBalancer策略
StochasticLoadBalancer策略相比SimpleLoadBalancer策略更复杂,它对于负载的定义不再是Region个数这么简单,而是由多种独立负载加权计算的复合值。
独立负载包括:
1)Region个数(RegionCountSkewCostFunction)
2)Region负载
3)读请求数(ReadRequestCostFunction)
4)写请求数(WriteRequestCostFunction)
5)Storefile大小(StoreFileCostFunction)
6)MemStore大小(MemStoreSizeCostFunction)
7)数据本地率(LocalityCostFunction)
8)移动代价(MoveCostFunction)
这些独立负载经过加权计算会得到一个代价值,系统使用这个代价值来评估当前Region分布是否均衡,越均衡代价值越低。HBase通过不断随机挑选迭代来找到一组Region迁移计划,使得代价值最小。
2,负载均衡策略的配置
StochasticLoadBalancer是目前HBase默认的负载均衡策略。用户可以通过配置选择具体的负载均衡策略。
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.hadoop.hbase.master.balancer.SimpleLoadBalancer</value>
</property
3,负载均衡相关的命令
HBase提供了多个与负载均衡相关的shell命令,主要包括负载均衡开关balance_switch
以及负载均衡执行balancer等命令。
文章来源:《HBase原理与实践》 作者:胡争;范欣欣
文章内容仅供学习交流,如有侵犯,联系删除哦!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











